万字干货还原美团Flink实时数仓建设( 六 )
第一点是对于一些共性指标的加工 , 比如说 pv、uv、交易额这些运算 , 我们会在汇总层进行统一的运算 。 另外 , 在各个脚本中多次运算 , 不仅浪费算力 , 同时也有可能会算错 , 需要确保关于指标的口径是统一在一个固定的模型里面的 。 本身 Flink SQL 已经其实支持了非常多的计算方法 , 包括这些 count distinct 等都支持 。
值得注意的一点是 , 它在使用 count distinct 的时候 , 他会默认把所有的要去重的数据存在一个 state 里面 , 所以当去重的基数比较大的时候 , 可能会吃掉非常多的内存 , 导致程序崩溃 。 这个时候其实是可以考虑使用一些非精确系统的算法 , 比如说 BloomFilter 非精确去重、 HyperLogLog 超低内存去重方案 , 这些方案可以极大的减少内存的使用 。
【万字干货还原美团Flink实时数仓建设】第二点就是 Flink 比较有特色的一个点 , 就是 Flink 内置非常多的这种时间窗口 。 Flink SQL 里面有翻滚窗口、滑动窗口以及会话窗口 , 这些窗口在写离线 SQL 的时候是很难写出来的 , 所以可以开发出一些更加专注的模型 , 甚至可以使用一些在离线开发当中比较少使用的一些比较小的时间窗口 。
比如说 , 计算最近10分钟的数据 , 这样的窗口可以帮助我们建设一些基于时间趋势图的应用 。 但是这里面要注意一点 , 就是一旦使用了这个时间窗口 , 要配置对应的 TTL 参数 , 这样可以减少内存的使用 , 提高程序的运行效率 。 另外 , 如果 TTL 不够满足窗口的话 , 也有可能会导致数据计算的错误 。
第三点 , 在汇总层进行多维的主题汇总 , 因为实时仓库本身是面向主题的 , 可能每一个主题会关心的维度都不一样 , 所以我们会在不同的主题下 , 按照这个主题关心的维度对数据进行一些汇总 , 最后来算之前说过的那些汇总指标 。 但是这里有一个问题 , 如果不使用时间窗口的话 , 直接使用 group by, 它会导致生产出来的数据是一个 retract 流 , 默认的 kafka 的 sink 它是只支持 append 模式 , 所以在这里要进行一个转化 。
如果想把这个数据写入 kafka 的话 , 需要做一次转化 , 一般的转化方案实际上是把撤回流里的 false 的过程去掉 , 把 true 的过程保存起来 , 转化成一个 append stream, 然后就可以写入到 kafka 里了 。
第四点 , 在汇总层会做一个比较重要的工作 , 就是衍生维度的加工 。 如果衍生维度加工的时候可以利用 HBase 存储 , HBase 的版本机制可以帮助你更加轻松地来构建一个这种衍生维度的拉链表 , 可以帮助你准确的 get 到一个实时数据当时的准确的维度 。
三、仓库质量保证
经过上面的环节 , 如果你已经建立好了一个仓库 , 你会发现想保证仓库的正常的运行或者是保证它高质量的运行 , 其实是一个非常麻烦的过程 , 它要比一线的操作复杂得多 , 所以我们在建设完仓库之后 , 需要建设很多的周边系统来提高我们的生产效率 。
下面介绍一下我们目前使用的一些工具链系统 , 工具链系统的功能结构图如下图:
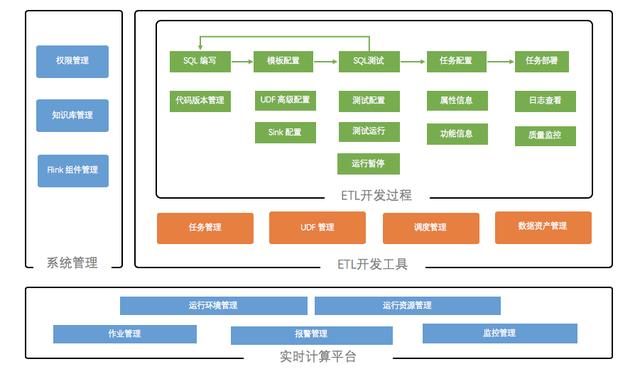 文章插图
文章插图
首先 , 工具链系统包括一个实时计算平台 , 主要的功能是统一提交作业和一些资源分配以及监控告警 , 但是实际上无论是否开发数仓 , 大概都需要这样的一个工具 , 这是开发 Flink 的基本工具 。
对于我们来讲 , 跟数仓相关的主要工具有两块:
1)系统管理模块 , 这个模块实际上是我们的实时和离线是一起使用的 。 其中知识库管理模块 , 主要是用来记录模型中表和字段的一些信息 , 另外就是一些工单的解决方法也会维护进去 。 Flink 管理主要是用来管理一些我们公司自己开发的一些 Flink 相关的系统组件 。
2)重点其实还是我们整个用来开发实时数仓 ETL 的一个开发工具 。 主要是如下几点:
推荐阅读




![[坦言]收入提高了?滴滴司机坦言:因为平台这波操作,现在收入](/renwen/images/defaultpic.gif)












- 广色域还不够 投影如何实现精准色彩还原?
- 对话五位英伟达技术专家:解析GTC China大会不容错过的技术干货
- AI从业必看!英伟达GTC China大会最新干货
- 渗透测试干货 | 横向渗透的常见方法
- 又一篇干货文章——德生PL990收音机的频率显示校准方法
- Python中字符串有哪些常用操作?纯干货超详细
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- 激光雷达、相机…万字长文带你入门无人驾驶车硬件
- 干货 | 特斯拉时代的线束发展趋势
- 收藏:Win10完美快速去掉快捷方式箭头和还原快捷箭头的方法