万字干货还原美团Flink实时数仓建设( 四 )
除了数据本身我们会在每条数据上额外补充一些信息 , 应对实时数据生产环节的一些常见问题:
 文章插图
文章插图
4)唯一键和主键
我们会给每一条数据都补充一个唯一键和一个主键 , 这两个是一对的 , 唯一键就是标识是唯一一条数据的 , 主键是标记为一行数据 。 一行数据可能变化很多次 , 但是主键是一样的 , 每一次变化都是其一次唯一的变化 , 所以会有一个唯一键 。 唯一键主要解决的是数据重复问题 , 从分层来讲 , 数据是从我们仓库以外进行生产的 , 所以很难保证我们仓库以外的数据是不会重复的 。
可能有些人交付数据给也会告知数据可能会有重复 。 生成唯一键的意思是指我们需要保证 DW 层的数据能够有一个标识 , 来解决可能由于上游产生的重复数据导致的计算重复问题 。 生成主键 , 其实最主要在于主键在 kafka 进行分区操作 , 跟之前接 ODS 保证分区有序的原理是一样的 , 通过主键 , 在 kafka 里进行分区之后 , 消费数据的时候就可以保证单条数据的消费是有序的 。
5)版本和批次
版本和批次这两个其实又是一组 。 当然这个内容名字可以随便起 , 最重要的是它的逻辑 。
首先 , 版本 。 版本的概念就是对应的表结构 , 也就是 schema 一个版本的数据 。 由于在处理实时数据的时候 , 下游的脚本依赖表上一次的 schema 进行开发的 。 当数据表结构发生变化的时候 , 就可能出现两种情况:第一种情况 , 可能新加或者删减的字段并没有用到 , 其实完全不用感知 , 不用做任何操作就可以了 。 另外一种情况 , 需要用到变动的字段 。 此时会产生一个问题 , 在 Kafka 的表中 , 就相当于有两种不同的表结构的数据 。 这时候其实需要一个标记版本的内容来告诉我们 , 消费的这条数据到底应该用什么样的表结构来进行处理 , 所以要加一个像版本这样的概念 。
第二 , 批次 。 批次实际上是一个更不常见的场景 , 有些时候可能会发生数据重导 , 它跟重启不太一样 , 重启作业可能就是改一改 , 然后接着上一次消费的位置启动 。 而重导的话 , 数据消费的位置会发生变化 。
比如 , 今天的数据算错了 , 领导很着急让我改 , 然后我需要把今天的数据重算 , 可能把数据程序修改好之后 , 还要设定程序 , 比如从今天的凌晨开始重新跑 。 这个时候由于整个数据程序是一个 7x24 小时的在线状态 , 其实原先的数据程序不能停 , 等重导的程序追上新的数据之后 , 才能把原来的程序停掉 , 最后使用重导的数据来更新结果层的数据 。
在这种情况下 , 必然会短暂的存在两套数据 。 这两套数据想要进行区分的时候 , 就要通过批次来区分 。 其实就是所有的作业只消费指定批次的数据 , 当重导作业产生的时候 , 只有消费重导批次的作业才会消费这些重导的数据 , 然后数据追上之后 , 只要把原来批次的作业都停掉就可以了 , 这样就可以解决一个数据重导的问题 。
6)维度数据建设
其次就是维度数据 , 我们的明细层里面包括了维度数据 。 关于维度的数据的处理 , 实际上是先把维度数据分成了两大类采用不同的方案来进行处理 。
① 变化频率低的维度
第一类数据就是一些变化频率比较低的数据 , 这些数据其实可能是一些基本上是不会变的数据 。 比如说 , 一些地理的维度信息、节假日信息和一些固定代码的转换 。
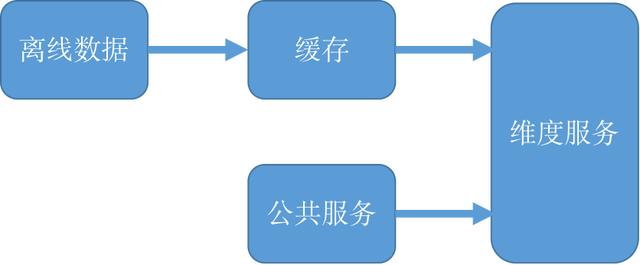 文章插图
文章插图
这些数据实际上我们采用的方法就是直接可以通过离线仓库里面会有对应的维表 , 然后通过一个同步作业把它加载到缓存中来进行访问 。 还有一些维度数据创建得会很快 , 可能会不断有新的数据创建出来 , 但是一旦创建出来 , 其实也就不再会变了 。
推荐阅读




![[坦言]收入提高了?滴滴司机坦言:因为平台这波操作,现在收入](/renwen/images/defaultpic.gif)












- 广色域还不够 投影如何实现精准色彩还原?
- 对话五位英伟达技术专家:解析GTC China大会不容错过的技术干货
- AI从业必看!英伟达GTC China大会最新干货
- 渗透测试干货 | 横向渗透的常见方法
- 又一篇干货文章——德生PL990收音机的频率显示校准方法
- Python中字符串有哪些常用操作?纯干货超详细
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- 激光雷达、相机…万字长文带你入门无人驾驶车硬件
- 干货 | 特斯拉时代的线束发展趋势
- 收藏:Win10完美快速去掉快捷方式箭头和还原快捷箭头的方法