万字干货还原美团Flink实时数仓建设( 二 )
3)数仓对象层面
离线数仓实际上就是在使用 Hive 表 。 对于实时数仓来讲 , 我们对表的抽象是使用 Stream Table 来进行抽象 。
4)物理存储
离线数仓 , 我们多数情况下会使用 HDFS 进行存储 。 实时数仓 , 我们更多的时候会采用像 Kafka 这样的消息队列来进行数据的存储 。
2、实时数仓的整体架构
在此之前我们做过一次分享 , 是关于为什么选择 Flink 来做实时数仓 , 其中重点介绍了技术组件选型的原因和思路 , 具体内容参考《美团点评基于 Flink 的实时数仓建设实践》 。 本文分享的主要内容是围绕数据本身来进行的 , 下面是我们目前的实时数仓的数据架构图:
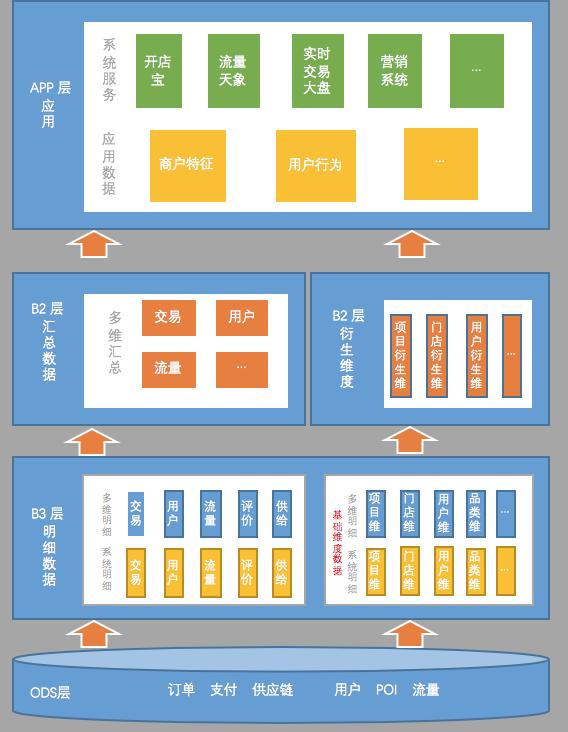 文章插图
文章插图
从数据架构图来看 , 实时数仓的数据架构会跟离线数仓有很多类似的地方 。 比如分层结构;比如说 ODS 层 , 明细层、汇总层 , 乃至应用层 , 它们命名的模式可能都是一样的 。 尽管如此 , 实时数仓和离线数仓还是有很多的区别的 。
跟离线数仓主要不一样的地方 , 就是实时数仓的层次更少一些 。
以我们目前建设离线数仓的经验来看 , 数仓的第二层远远不止这么简单 , 一般都会有一些轻度汇总层这样的概念 , 其实第二层会包含很多层 。 另外一个就是应用层 , 以往建设数仓的时候 , 应用层其实是在仓库内部的 。 在应用层建设好后 , 会建同步任务 , 把数据同步到应用系统的数据库里 。
在实时数仓里面 , 所谓 APP 层的应用表 , 实际上就已经在应用系统的数据库里了 。 上图 , 虽然画了 APP 层 , 但它其实并不算是数仓里的表 , 这些数据本质上已经存过去了 。
为什么主题层次要少一些?是因为在实时处理数据的时候 , 每建一个层次 , 数据必然会产生一定的延迟 。
为什么汇总层也会尽量少建?是因为在汇总统计的时候 , 往往为了容忍一部分数据的延迟 , 可能会人为的制造一些延迟来保证数据的准确 。
举例 , 统计事件中的数据时 , 可能会等到 10:00:05 或者 10:00:10再统计 , 确保 10:00 前的数据已经全部接受到位了 , 再进行统计 。 所以 , 汇总层的层次太多的话 , 就会更大的加重人为造成的数据延迟 。
建议尽量减少层次 , 特别是汇总层一定要减少 , 最好不要超过两层 。 明细层可能多一点层次还好 , 会有这种系统明细的设计概念 。
第二个比较大的不同点就是在于数据源的存储 。
在建设离线数仓的时候 , 可能整个数仓都全部是建立在 Hive 表上 , 都是跑在 Hadoop 上 。 但是 , 在建设实时数仓的时候 , 同一份表 , 我们甚至可能会使用不同的方式进行存储 。
比如常见的情况下 , 可能绝大多数的明细数据或者汇总数据都会存在 Kafka 里面 , 但是像维度数据 , 可能会存在像 Tair 或者 HBase 这样的 kv 存储的系统中 , 实际上可能汇总数据也会存进去 , 具体原因后面详细分析 。 除了整体结构 , 我们也分享一下每一层建设的要点 。
1)ODS 层的建设
- 数据来源尽可能统一
- 利用分区保证数据局部有序
 文章插图
文章插图首先第一个建设要点就是 ODS 层 , 其实 ODS 层建设可能跟仓库不一定有必然的关系 , 只要使用 Flink 开发程序 , 就必然都要有实时的数据源 。 目前主要的实时数据源是消息队列 , 如 Kafka 。 而我们目前接触到的数据源 , 主要还是以 binlog、流量日志和系统日志为主 。
这里面我主要想讲两点:
首先第一个建设要点就是 ODS层 , 其实ODS层建设可能跟这个仓库不一定有必然的关系 , 只要你使用这个flink开发程序 , 你必然都要有这种实时的数据源 。 目前的主要的实时数据源就是消息队列 , 如kafka 。 我们目前接触到的数据源 , 主要还是以binlog、流量日志和系统日志为主 。
推荐阅读















- 广色域还不够 投影如何实现精准色彩还原?
- 对话五位英伟达技术专家:解析GTC China大会不容错过的技术干货
- AI从业必看!英伟达GTC China大会最新干货
- 渗透测试干货 | 横向渗透的常见方法
- 又一篇干货文章——德生PL990收音机的频率显示校准方法
- Python中字符串有哪些常用操作?纯干货超详细
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- 激光雷达、相机…万字长文带你入门无人驾驶车硬件
- 干货 | 特斯拉时代的线束发展趋势
- 收藏:Win10完美快速去掉快捷方式箭头和还原快捷箭头的方法