 文章插图
文章插图
背景介绍随着人工智能技术在爱奇艺视频业务线的广泛应用 , 深度学习算法在云端的部署对计算资源 , 尤其是 GPU 资源的需求也在飞速增长 。 如何提高深度学习应用部署效率 , 降低云平台运行成本 , 帮助算法及业务团队快速落地应用和服务 , 让 AI 发挥真正的生产力 , 是深度学习云平台团队努力的目标。
从基础架构的角度 , GPU 资源的紧缺和 GPU 利用率的不足是我们面临的主要挑战 。 由于大量的算法训练及推理服务需求 , 云端 GPU 资源经常处于短缺状态;而使用 CPU 进行的推理服务常常由于性能问题 , 无法满足服务指标 。 除此之外 , 线上服务通常有较高的实时性要求 , 需要独占 GPU , 但由于较低的 QPS , GPU 利用率经常处于较低的状态(<20%) 。
在此背景下 , 我们尝试进行了基于 CPU 的深度学习推理服务优化 , 通过提升推理服务在 CPU 上的性能 , 完成服务从 GPU 迁移到 CPU 上的目的 , 以利用集群中大量的 CPU 服务器 , 同时节省 GPU 计算资源。
 文章插图
文章插图
图 1. 深度学习服务对云平台的挑战
1. 深度学习推理服务及优化流程1.1 什么是深度学习推理服务?
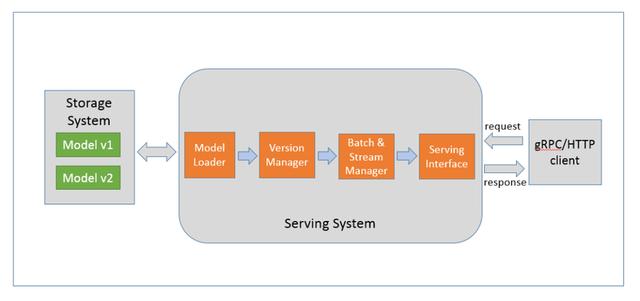
深度学习推理服务通常是指将训练好的深度学习模型部署到云端 , 并对外提供 gRPC/HTTP 接口请求的服务 。 推理服务内部实现的功能包括模型加载 , 模型版本管理 , 批处理及多路支持 , 以及服务接口的封装等 , 如图 2 所示:
 文章插图
文章插图
图 2. 深度学习推理服务功能模块
业界常用的深度学习推理服务框架包括 Google 的 tensorflow serving、Nvidia 的 Tensor RT inference server , Amazon 的 Elastic Inference 等 。 目前爱奇艺深度学习云平台(Jarvis)提供以 tensorflow serving 为框架的自动推理服务部署功能 , 已支持的深度学习模型包括 tensorflow , caffe , caffe2 , mxnet , tensorrt 等 , 未来还会支持包括 openvino , pytorch 。 除此之外 , 业务团队也可以根据自身需求实现和定制特定的深度学习服务化容器 , 并通过 QAE 进行服务的部署和管理 。
1.2 服务优化的流程是怎样的?
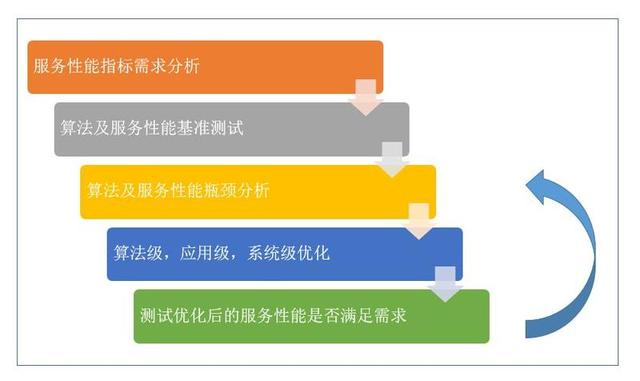
服务优化流程如图 3 所示 , 是一个不断朝优化目标迭代的过程 。
 文章插图
文章插图
图 3. 服务优化的流程
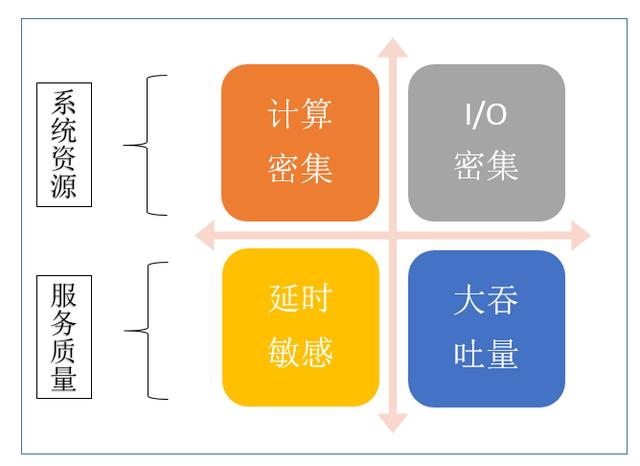
进行深度学习推理服务的优化 , 首先需要明确服务的类型和主要性能指标 , 以确定服务优化的目标 。 从系统资源的角度 , 深度学习服务可以分为计算密集或者 I/O 密集类服务 , 例如基于 CNN 的图像 / 视频类算法通常对计算的需求比较大 , 属于计算密集型服务 , 搜索推荐类的大数据算法输入数据的特征维度较高 , 数据量大 , 通常属于 I/O 密集型服务 。 从服务质量的角度 , 又可以分为延时敏感类服务和大吞吐量类型服务 , 例如在线类服务通常需要更低的请求响应时间 , 多属于延时敏感类服务 , 而离线服务通常是批处理的大吞吐量类型服务 。 不同类型的深度学习服务优化的目标和方法也不尽相同 。
 文章插图
文章插图
图 4. 深度学习推理服务的分类
1.3 深度学习推理服务的性能指标有哪些?
深度学习服务的性能指标主要包括响应延时(latency) , 吞吐量(throughput) , 及模型精度(accuracy)等 , 如图 5 所示 。 其中响应延时和吞吐量两个指标是进行服务化过程中关心的性能指标 。 明确服务性能指标后便于我们分析服务规模 , 计算单一服务节点需要达到的服务性能 。
推荐阅读














- 华硕基于WRX80的主板现身 为AMD Ryzen Threadripper Pro打造
- 微软新版电子邮件客户端截图曝光:基于网页端Outlook
- AMD 专利展现 MCM 模块化芯片设计,GPU 将采用多核封装
- Sonnet更新便携式eGPU Breakaway Puck系列产品线
- 曝光 | 小鹏或春节前推送NGP更新,基于高精地图可自动变道
- 英特尔Xe GPU在Linux 5.11上的性能表现不错
- 基于Spring+Angular9+MySQL开发平台
- 华硕和宏碁即将推出发烧级笔电 采用AMD Zen 3 移动处理器和NVIDIA 3080 GPU
- 14款华为手机/平板公测EMUI 11:全部基于麒麟980
- NVIDIA下代GPU信息再爆:5nm无悬念,代号或不是Hopper