目前线上集群已支持选择不同类型的 CPU 进行服务部署 。
(4)输入数据格式的影响
除 Tensorflow 之外的其他常用深度学习框架 , 对于图像类算法的输入 , 通常推荐使用 NCHW 格式的数据作为输入 。 Tensorflow 原生框架默认在 CPU 上只支持 NHWC 格式的输入 , 经过 MKL-DNN 优化的 Tensorflow 可以支持两种输入数据格式 。
使用以上两种优化方式 , 建议算法模型以 NCHW 作为输入格式 , 以减少推理过程中内存数据重排带来的额外开销 。
【GPU|干货|基于 CPU 的深度学习推理部署优化实践】(5)NUMA 配置的影响
对于 NUMA 架构的服务器 , NUMA 配置在同一 node 上相比不同 node 上性能通常会有 5%-10% 的提升 。
2.5 如何进行应用级的优化?
进行应用级的优化 , 首先需要将应用端到端的各个环节进行性能分析和测试 , 找到应用的性能瓶颈 , 再进行针对性优化 。 性能分析和测试可以通过加入时间戳日志 , 或者使用时序性能分析工具 , 例如 Vtune , timeline 等。 优化方法主要包括并发和流水设计、数据预取和预处理、I/O 加速、特定功能加速(例如使用加速库或硬件进行编解码、抽帧、特征 embedding 等功能加速)等方式 。
下面以视频质量评估服务为例 , 介绍如何利用 Vtune 工具进行瓶颈分析 , 以及如何利用多线程 / 进程并发进行服务的优化 。
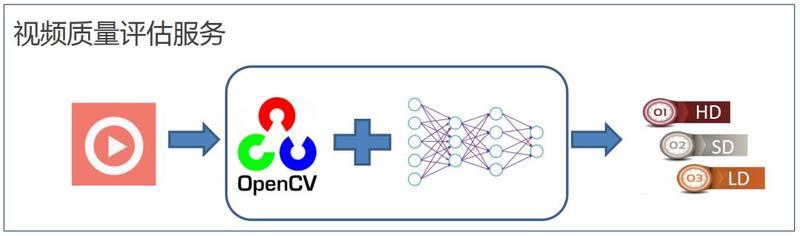
视频质量评估服务的基本流程如图 10 所示 , 应用读入一段视频码流 , 通过 OpenCV 进行解码、抽帧、预处理 , 之后将处理后的码流经过深度学习网络进行推理 , 最后通过推理结果的聚合得到视频质量的打分 , 来判定是何种类型视频 。
 文章插图
文章插图
图 10. 视频质量评估服务流程
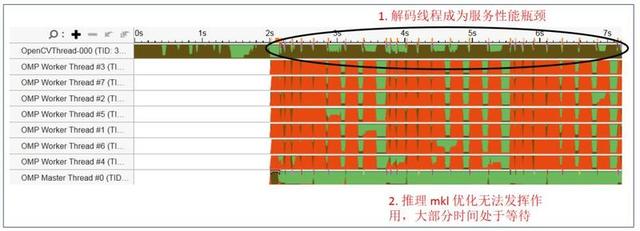
图 11 是通过 Vtune 工具抓取的原始应用线程 , 可以看到 OpenCV 单一解码线程一直处于繁忙状态(棕色) , 而 OMP 推理线程常常处于等待状态(红色) 。 整个应用的瓶颈位于 Opencv 的解码及预处理部分 。
 文章插图
文章插图
图 11. 应用优化前线程状态
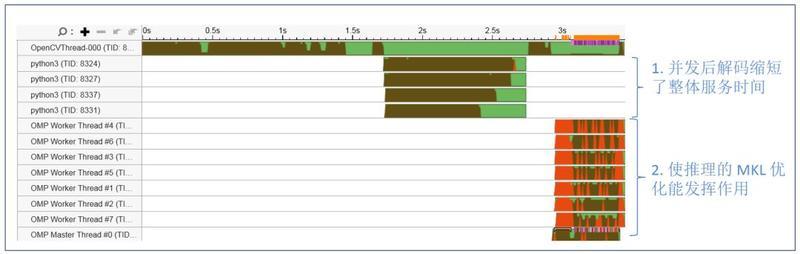
图 12 显示优化后的服务线程状态 , 通过生成多个进程并发进行视频流解码 , 并以 batch 的方式进行预处理;处理后的数据以 batch 的方式传入 OMP threads 进行推理来进行服务的优化 。
 文章插图
文章插图
图 12. 应用并发优化后线程状态
经过上述简单的并发优化后 , 对 720 帧视频码流的处理时间 , 从 7 秒提升到了 3.5 秒 , 性能提升一倍 。 除此之外 , 我们还可以通过流水设计 , 专用解码硬件加速等方法进一步提升服务整体性能 。
2.6 如何进行算法级的优化?
常见的算法级优化提升推理服务性能的方法包括 batchsize 的调整、模型剪枝、模型量化等 。 其中模型剪枝和量化因涉及到模型结构和参数的调整 , 通常需要算法同学帮助一起进行优化 , 以保证模型的精度能满足要求 。
2.7 Batchsize 的选取在 CPU 上对服务性能的影响是怎样的?
Batchsize 选取的基本原则是延时敏感类服务选取较小的 batchsize , 吞吐量敏感的服务选取较大的 batchsize 。
图 13 是选取不同的 batchsize 对推理服务吞吐量及延时的影响 。 测试结果可以看 batchsize 较小时适当增大 batchsize(例如 bs 从 1 到 2) , 对延时的影响较小 , 但是可以迅速提升吞吐量的性能;batchsize 较大时再增加其值(例如从 8 到 32) , 对服务吞吐量的提升已没有帮助 , 但是会极大影响服务延时性能 。 因此实践中需根据部署服务节点 CPU 核数及服务性能需求来优化选取 batchsize 。
推荐阅读











![[绿豆]男人想要长寿,5件“耗阳”的事要“舍弃”,一些人表示很难做到](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/26fa2bbcc60faf5ef39679c3f1999fd3.jpg)





- 华硕基于WRX80的主板现身 为AMD Ryzen Threadripper Pro打造
- 微软新版电子邮件客户端截图曝光:基于网页端Outlook
- AMD 专利展现 MCM 模块化芯片设计,GPU 将采用多核封装
- Sonnet更新便携式eGPU Breakaway Puck系列产品线
- 曝光 | 小鹏或春节前推送NGP更新,基于高精地图可自动变道
- 英特尔Xe GPU在Linux 5.11上的性能表现不错
- 基于Spring+Angular9+MySQL开发平台
- 华硕和宏碁即将推出发烧级笔电 采用AMD Zen 3 移动处理器和NVIDIA 3080 GPU
- 14款华为手机/平板公测EMUI 11:全部基于麒麟980
- NVIDIA下代GPU信息再爆:5nm无悬念,代号或不是Hopper