数据不平衡问题
数据不平衡问题
?所谓的不平衡指的是不同类别的样本量差异非常大 , 或者少数样本代 表了业务的关键数据(少量样本更重要) , 需要对少量样本的模式有 很好的学习 。 样本类别分布不平衡主要出现在分类相关的建模问题上 。样本类别分布不均衡从数据规模上可以分为大数据分布不均衡和小数
?据分布不均衡两种:
?大数据分布不均衡——整体数据规模较大 , 某类别样本占比较 小 。 例如拥有1000万条记录的数据集中 , 其中占比5万条的少 数分类样本便于属于这种情况 。
?小数据分布不均衡——整体数据规模小 , 则某类别样本的数量 也少 , 这种情况下 , 由于少量样本数太少 , 很难提取特征进行 有/无监督算法学习 , 此时属于严重的小数据样本分布不均衡 。例如拥有100个样本 , 20个A类样本 , 80个B类样本 。
 文章插图
文章插图
?典型场景
?CTR预估:广告点击率 , 通常只有百分之几 , 点击的样本占比非常少 , 大量的未点击样本
?异常检测:比如恶意刷单、黄牛订单、信用卡欺诈、电力窃电、设备故障等 , 这 些数据样本所占的比例通常是整体样本中很少的一部分 , 以信用卡欺诈为例 , 刷实体信 用卡的欺诈比例一般都在0.1%以内 。
?罕见事件的分析:罕见事件分析与异常事件的区别在于异常检测通常都有是预先定义 好的规则和逻辑 , 并且大多数异常事件都对会企业运营造成负面影响 , 因此针对异常事 件的检测和预防非常重要;但罕见事件则无法预判 , 并且也没有明显的积极和消极影响 倾向 。
?工程过程中 , 应对样本不均衡问题常从以下三方面入手:
?欠采样:在少量样本数量不影响模型训练的情况下 , 可以通过对多数样本 欠采样 , 实现少数样本和多数样本的均衡 。
?过采样:在少量样本数量不支撑模型训练的情况下 , 可以通过对少量样本 过采样 , 实现少数样本和多数样本的均衡 。
?模型算法:通过引入有倚重的模型算法 , 针对少量样本着重拟合 , 以提升 对少量样本特征的学习
?常见处理方法
欠采样
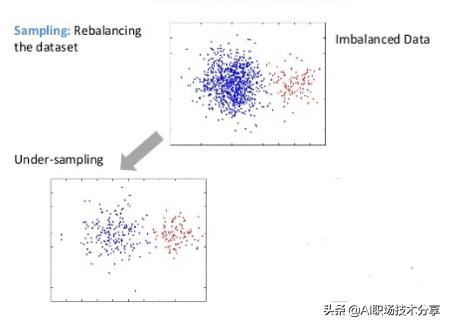
?欠抽样(也叫下采样、under-sampling , US)方法通 过减少分类中多数类样本的样本数量来实现样本均衡 。通过欠采样 , 在保留少量样本的同时 , 会丢失多数类样 本中的一些信息 。 经过欠采样 , 样本总量在减少 。
 文章插图
文章插图
欠采样 – 随机删除
?随机地删除一些多量样本 , 使少量样本和多量样本数量达到均衡
 文章插图
文章插图
欠采样 – 原型生成 (Prototype generation)
?PG 算法主要是在原有样本的基础上生成新的样本来实现样本均衡 , 具体做法如下:
 文章插图
文章插图
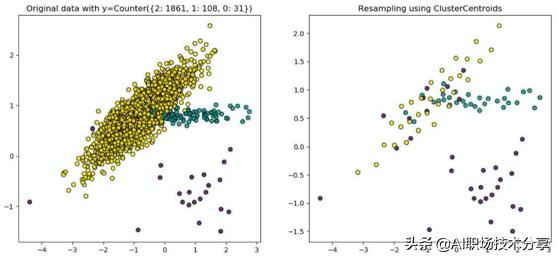
?下图所示为三类共2000个样本点的集合 , 每个样本维度为2 , label1个数为1861 , label2个数为108 , label3个数为31 。 利用PG算法完成数据均衡后 , 样本整体分布没有变化 。
 文章插图
文章插图
过采样
?过抽样(也叫上采样、over-sampling)方法通过增加分类中少数 样本的数量来实现样本均衡 , 最直接的方法是简单复制少数类样 本形成多条记录 , 这种方法的缺点是如果样本特征少而可能导致过 拟合的问题 。
?经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或 通过一定规则产生新的合成样本 , 对应的算法会在后面介绍 。
推荐阅读












- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 一则消息传来,苹果iPhone12再现问题,“果粉”有点慌
- 与荷兰光刻机完成联机!国产芯片设备传来喜讯:技术问题已经解决
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 国产芯再传好消息,关键技术问题已经解决,与荷兰光刻机联机成功
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 小米11屏幕翻车发绿怎么回事 屏幕问题检测方法介绍
- 装机点不亮 如何简易排查硬件问题?
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?