数据不平衡问题( 三 )
?在信用卡盗用检查中 , 将正常使用误认为是盗用 , 可能会使用户体验不佳 , 但是将盗用误认为是 正常使用 , 会使用户承受巨大的损失 。
?为了权衡不同类型错误所造成的不同损失 , 可为错误赋予“非均等代价” (unequal cost) 。
模型算法 – Cost Sensitive算法
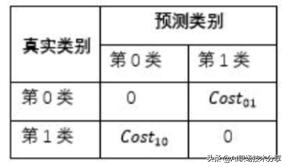
?代价敏感方法的核心要素是代价矩阵 , 如下表所示 。 cost_ij 表示将第i类样本预测为第j类样本的代价 。 一般来说 ,cost_ij=0;若将第0类判定为第1类所造成的损失更大 , 则cost_01 >cost_10;损失程度相差越大 ,cost_01 与 cost_10 的值差别越大 。 当 cost_01 与 cost_10相等时为代价不敏感的学习问题 。
 文章插图
文章插图
?从学习模型出发 , 对某一具体学习方法的改造 , 使之能适应不平衡数据下的学习 , 研究者们针对 不同的学习模型如感知机、支持向量机、决策树、神经网络等分别提出了其代价敏感的版本 。 以 代价敏感的决策树为例 , 可以从三个方面对其进行改造以适应不平衡数据的学习 , 这三个方面分 别是决策阈值的选择方面、分裂标准的选择方面、剪枝方面 , 这三个方面都可以将代价矩阵引入 。
?从贝叶斯风险理论出发 , 把代价敏感学习看成是分类结果的一种后处理 , 按照传统方法学习到一 个模型 , 以实现损失最小为目标对结果进行调整 。 此方法的优点在于它可以不依赖所用的具体分 类器 , 但是缺点也很明显 , 它要求分类器输出值为概率 。
?从预处理的角度出发 , 将代价用于权重调整 , 使得分类器满足代价敏感的特性
模型算法 – MetaCost算法
?在训练集中多次采样 , 生成多个模型 。
?根据多个模型 , 得到训练集中每条记录属于 每个类别的概率 。
?计算训练集中每条记录的属于每个类的代价 ,根据最小代价 , 修改类标签 。
?训练修改过的数据集 , 得到新的模型 。
 文章插图
文章插图
模型算法 – Focal Loss
?Focal Loss for Dense Object Detection,ICCV2017
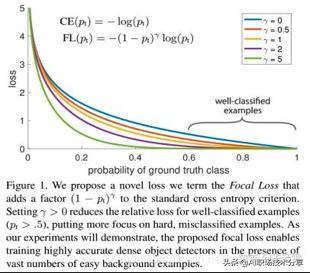
?Focal loss 是在标准交叉熵损失基础上修改得到的 , 通过减少易分类样本的权重 , 使得模型在训练时更专注于难分类的样本 。
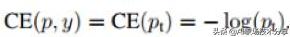 文章插图
文章插图
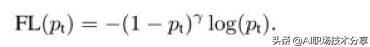 文章插图
文章插图
 文章插图
文章插图
评价指标 – 基础知识
?错误率(Error Rate):分类错误的样本数占样本总数的比例 。
?混淆矩阵(confusion matrix)
 文章插图
文章插图
?查准率(Precision) , 又叫精确率 , 表示的是预测为正的样例中有多少是真正的正样例P=TP/(TP+FP)
?召回率(Recall) , 表示的是样本中的正/负例有多少被预测正确 , R=TP/(TP+FN)
?准确率(Accuracy):分类正确的样本数占样本总数的比例 , Accuracy = (TP+TN)/(TP+FP+FN+TN) 。
?F1 = 2 * TP / (样本总数 + TP - TN)
评价指标 – G-mean
?在样本不均衡的情况下 , 由于少量样本占比较小 , 如果仅考虑Error Rate或者accuracy , 即使模型 全部把少量样本分错 , 其整体的Error Rate和Accuracy还是比较高的 。 因此 , 对于样本不平衡的情 况下 , 引入另外一个评价指标——G - mean 。
 文章插图
文章插图
推荐阅读












![人民网|[网连中国]乡音唱新风、定约除陋习,文明实践最后"一公里"通了](https://mz.eastday.com/18403767.jpg)






- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 一则消息传来,苹果iPhone12再现问题,“果粉”有点慌
- 与荷兰光刻机完成联机!国产芯片设备传来喜讯:技术问题已经解决
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 国产芯再传好消息,关键技术问题已经解决,与荷兰光刻机联机成功
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 小米11屏幕翻车发绿怎么回事 屏幕问题检测方法介绍
- 装机点不亮 如何简易排查硬件问题?
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?