еҰӮдҪ•дјҳеҢ– TensorFlow Lite иҝҗиЎҢж—¶еҶ…еӯҳпјҹ
з”ұдәҺиө„жәҗжңүйҷҗ пјҢ еңЁз§»еҠЁе’ҢеөҢе…ҘејҸи®ҫеӨҮдёҠиҝҗиЎҢжҺЁзҗҶеҫҲжңүжҢ‘жҲҳжҖ§ гҖӮ дәә们еҝ…йЎ»еңЁдёҘж јзҡ„иғҪиҖ—иҰҒжұӮдёӢдҪҝз”Ёжңүйҷҗзҡ„硬件 гҖӮ еңЁжң¬ж–Үдёӯ пјҢ жҲ‘们еёҢжңӣеұ•зӨә TensorFlow LiteпјҲTFLiteпјүеҶ…еӯҳдҪҝз”Ёж–№йқўзҡ„ж”№иҝӣ пјҢ иҝҷдәӣж”№иҝӣдҪҝе…¶жӣҙйҖӮеҗҲеңЁиҫ№зјҳи®ҫеӨҮиҝҗиЎҢжҺЁзҗҶ гҖӮ
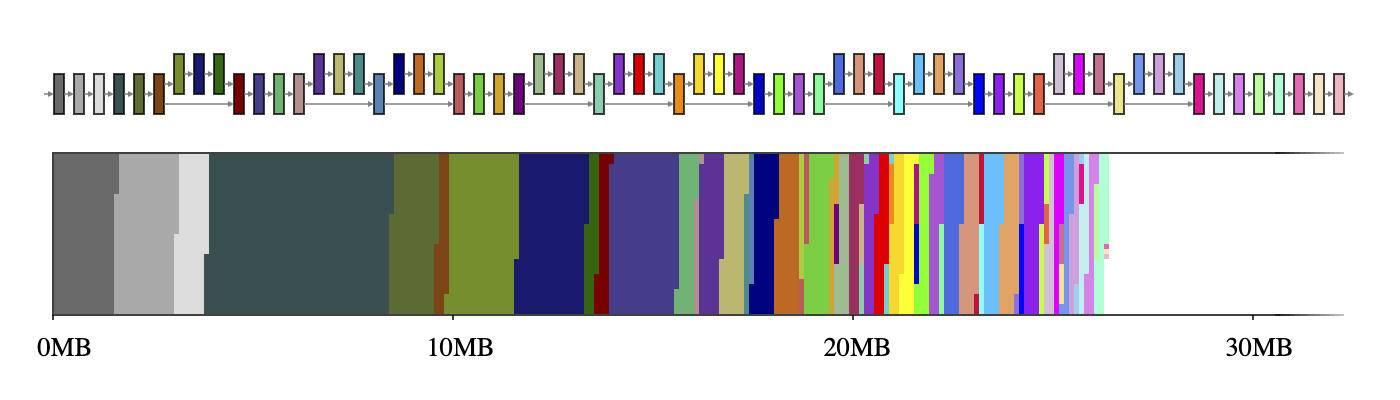
дёӯй—ҙеј йҮҸйҖҡеёёжғ…еҶөдёӢ пјҢ зҘһз»ҸзҪ‘з»ңеҸҜд»Ҙиў«и®ӨдёәжҳҜи®Ўз®—еӣҫ пјҢ з”ұиҝҗз®—з¬ҰпјҲеҰӮCONV_2DжҲ–FULLY_CONNECTEDпјүе’ҢеҢ…еҗ«дёӯй—ҙи®Ўз®—з»“жһңзҡ„еј йҮҸпјҲз§°дёәдёӯй—ҙеј йҮҸпјүз»„жҲҗ гҖӮ иҝҷдәӣдёӯй—ҙеј йҮҸйҖҡеёёжҳҜйў„е…ҲеҲҶй…Қзҡ„ пјҢ д»ҘеҮҸе°‘жҺЁзҗҶзӯүеҫ…ж—¶й—ҙ пјҢ иҖҢд»Јд»·жҳҜеӯҳеӮЁз©әй—ҙ гҖӮ 然иҖҢ пјҢ еҰӮжһңеӨ©зңҹең°е®һзҺ°дәҶиҝҷдёӘд»Јд»· пјҢ йӮЈд№ҲеңЁиө„жәҗеҸ—йҷҗзҡ„зҺҜеўғдёӯе°ұдёҚиғҪжҺүд»ҘиҪ»еҝғпјҡе®ғеҸҜиғҪдјҡеҚ з”ЁеӨ§йҮҸзҡ„з©әй—ҙ пјҢ жңүж—¶з”ҡиҮіжҜ”жЁЎеһӢжң¬иә«иҝҳиҰҒеӨ§еҘҪеҮ еҖҚ гҖӮ дҫӢеҰӮ пјҢ MobileNet V2 дёӯзҡ„дёӯй—ҙеј йҮҸеҚ з”ЁдәҶ 26MB еҶ…еӯҳпјҲи§Ғеӣҫ 1пјү пјҢ еӨ§зәҰжҳҜжЁЎеһӢжң¬иә«зҡ„дёӨеҖҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еӣҫ 1
еӣҫ 1пјҡMobileNet V2 зҡ„дёӯй—ҙеј йҮҸпјҲдёҠпјүеҸҠе…¶еңЁ 2D еӯҳеӮЁз©әй—ҙпјҲдёӢпјүдёҠзҡ„жҳ е°„ гҖӮ еҰӮжһңжҜҸдёӘдёӯй—ҙеј йҮҸдҪҝз”Ёдё“з”Ёзҡ„еҶ…еӯҳзј“еҶІеҢәпјҲз”Ё 56 з§ҚдёҚеҗҢзҡ„йўңиүІиЎЁзӨәпјү пјҢ е®ғ们е°ҶеҚ з”ЁзәҰ 26MB зҡ„иҝҗиЎҢж—¶еҶ…еӯҳ
еҘҪж¶ҲжҒҜжҳҜ пјҢ з”ұдәҺж•°жҚ®зӣёе…іжҖ§еҲҶжһҗ пјҢ иҝҷдәӣдёӯй—ҙеј йҮҸдёҚеҝ…еңЁеҶ…еӯҳдёӯе…ұеӯҳ гҖӮ иҝҷе…Ғи®ёжҲ‘们еҸҜд»ҘйҮҚз”Ёдёӯй—ҙеј йҮҸзҡ„еҶ…еӯҳзј“еҶІеҢә пјҢ 并еҮҸе°‘жҺЁзҗҶжңәзҡ„жҖ»еҶ…еӯҳеҚ з”Ё гҖӮ еҰӮжһңзҪ‘з»ңе…·жңүз®ҖеҚ•й“ҫзҡ„еҪўзҠ¶ пјҢ йӮЈд№ҲдёӨдёӘеӨ§зҡ„еҶ…еӯҳзј“еҶІеҢәе°ұи¶іеӨҹдәҶ пјҢ еӣ дёәе®ғ们еҸҜд»ҘеңЁж•ҙдёӘзҪ‘з»ңдёӯжқҘеӣһдә’жҚў гҖӮ 然иҖҢ пјҢ еҜ№дәҺжһ„жҲҗеӨҚжқӮеӣҫзҡ„д»»ж„ҸзҪ‘з»ң пјҢ иҝҷз§Қ NP е®Ңе…ЁпјҲNP-Complete пјҢ зј©еҶҷдёә NP-C жҲ– NPCпјүиө„жәҗеҲҶй…Қй—®йўҳйңҖиҰҒдёҖдёӘиүҜеҘҪзҡ„иҝ‘дјјз®—жі• гҖӮ
жҲ‘们дёәиҝҷдёӘй—®йўҳи®ҫи®ЎдәҶи®ёеӨҡдёҚеҗҢзҡ„иҝ‘дјјз®—жі• пјҢ е®ғ们зҡ„жү§иЎҢж–№ејҸйғҪеҸ–еҶідәҺзҘһз»ҸзҪ‘з»ңе’ҢеҶ…еӯҳзј“еҶІеҢәзҡ„еұһжҖ§ пјҢ дҪҶе®ғ们йғҪдҪҝз”ЁдёҖдёӘе…ұеҗҢзӮ№пјҡеј йҮҸдҪҝз”Ёи®°еҪ• гҖӮ дёҖдёӘдёӯй—ҙеј йҮҸзҡ„еј йҮҸдҪҝз”Ёи®°еҪ•жҳҜдёҖдёӘиҫ…еҠ©ж•°жҚ®з»“жһ„ пјҢ е®ғеҢ…еҗ«е…ідәҺеј йҮҸжңүеӨҡеӨ§ пјҢ д»ҘеҸҠеңЁзҪ‘з»ңзҡ„з»ҷе®ҡжү§иЎҢи®ЎеҲ’дёӯ第дёҖж¬Ўе’ҢжңҖеҗҺдёҖж¬ЎдҪҝз”Ёзҡ„ж—¶й—ҙдҝЎжҒҜ гҖӮ еңЁиҝҷдәӣи®°еҪ•зҡ„её®еҠ©дёӢ пјҢ еҶ…еӯҳз®ЎзҗҶеҷЁиғҪеӨҹеңЁзҪ‘з»ңжү§иЎҢзҡ„д»»дҪ•ж—¶еҲ»и®Ўз®—дёӯй—ҙеј йҮҸзҡ„дҪҝз”Ё пјҢ 并дјҳеҢ–е…¶иҝҗиЎҢж—¶еҶ…еӯҳд»ҘиҺ·еҫ—е°ҪеҸҜиғҪе°Ҹзҡ„еҚ з”Ёз©әй—ҙ гҖӮ
е…ұдә«еҶ…еӯҳзј“еҶІеҢәеҜ№иұЎеңЁ TFLite GPU OpenGL еҗҺз«Ҝ пјҢ жҲ‘们дёәиҝҷдәӣдёӯй—ҙеј йҮҸйҮҮз”Ё GL зә№зҗҶ гҖӮ иҝҷдәӣйғҪжңүдёҖдәӣжңүи¶Јзҡ„йҷҗеҲ¶пјҡпјҲaпјүзә№зҗҶзҡ„еӨ§е°ҸеңЁеҲӣе»әд№ӢеҗҺдҫҝж— жі•дҝ®ж”№ пјҢ 并且пјҲbпјүеңЁз»ҷе®ҡзҡ„ж—¶й—ҙеҸӘжңүдёҖдёӘзқҖиүІеҷЁзЁӢеәҸиҺ·еҫ—еҜ№зә№зҗҶеҜ№иұЎзҡ„зӢ¬еҚ и®ҝй—®жқғ гҖӮ еңЁиҝҷз§Қе…ұдә«еҶ…еӯҳзј“еҶІеҢәеҜ№иұЎжЁЎејҸдёӯ пјҢ зӣ®ж ҮжҳҜжңҖе°ҸеҢ–еҜ№иұЎжұ дёӯжүҖжңүеҲӣе»әзҡ„е…ұдә«еҶ…еӯҳзј“еҶІеҢәеҜ№иұЎзҡ„еӨ§е°Ҹд№Ӣе’Ң гҖӮ иҝҷз§ҚдјҳеҢ–зұ»дјјдәҺдј—жүҖе‘ЁзҹҘзҡ„еҜ„еӯҳеҷЁеҲҶй…Қй—®йўҳ пјҢ еҸӘдёҚиҝҮз”ұдәҺжҜҸдёӘеҜ№иұЎзҡ„еӨ§е°ҸдёҚеҗҢ пјҢ иҝҷз§ҚдјҳеҢ–иҰҒеӨҚжқӮеҫ—еӨҡ гҖӮ
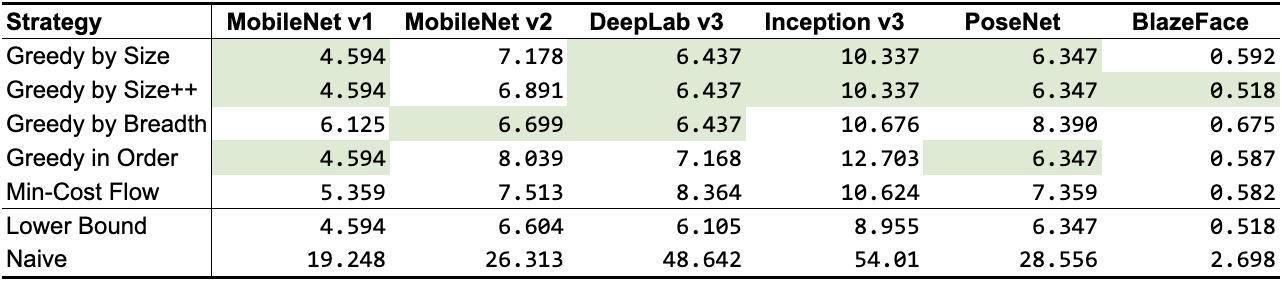
ж №жҚ®еүҚйқўжҸҗеҲ°зҡ„еј йҮҸдҪҝз”Ёи®°еҪ• пјҢ жҲ‘们и®ҫи®ЎдәҶ 5 з§ҚдёҚеҗҢзҡ„з®—жі• пјҢ еҰӮиЎЁ 1 жүҖзӨә гҖӮ йҷӨдәҶжңҖе°ҸжҲҗжң¬жөҒд№ӢеӨ– пјҢ е®ғ们йғҪжҳҜиҙӘеҝғз®—жі•пјҲGreedy algorithmпјү пјҢ жҜҸз§Қз®—жі•дҪҝз”ЁдәҶдёҚеҗҢзҡ„еҗҜеҸ‘ејҸз®—жі• пјҢ дҪҶд»Қ然йқһеёёжҺҘиҝ‘жҲ–жҺҘиҝ‘зҗҶи®әдёӢйҷҗ гҖӮ ж №жҚ®зҪ‘з»ңжӢ“жү‘зҡ„дёҚеҗҢ пјҢ дёҖдәӣз®—жі•жҜ”е…¶д»–з®—жі•жү§иЎҢеҫ—жӣҙеҘҪ пјҢ дҪҶйҖҡеёёжғ…еҶөдёӢ пјҢGREEDY_BY_SIZE_IMPROVEDе’ҢGREEDY_BY_BREADTHдә§з”ҹзҡ„еҜ№иұЎеҲҶй…ҚеҚ з”Ёзҡ„еҶ…еӯҳжңҖе°‘ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иЎЁ 1
иЎЁ 1пјҡе…ұдә«еҜ№иұЎзӯ–з•Ҙзҡ„еҶ…еӯҳеҚ з”ЁпјҲд»Ҙ MB дёәеҚ•дҪҚпјӣжңҖдҪіз»“жһңд»Ҙз»ҝиүІй«ҳдә®жҳҫзӨәпјү гҖӮ еүҚ 5 иЎҢжҳҜжҲ‘们зҡ„зӯ–з•Ҙ пјҢ еҗҺ 2 иЎҢдҪңдёәеҹәзәҝпјҲдёӢйҷҗиЎЁзӨәеҸҜиғҪж— жі•е®һзҺ°зҡ„жңҖдҪіж•°еҖјзҡ„иҝ‘дјјеҖј пјҢ Naive иЎЁзӨәжҜҸдёӘдёӯй—ҙеј йҮҸеҲҶй…ҚиҮӘе·ұзҡ„еҶ…еӯҳзј“еҶІеҢәж—¶еҸҜиғҪеҮәзҺ°зҡ„жңҖе·®ж•°еҖјпјү
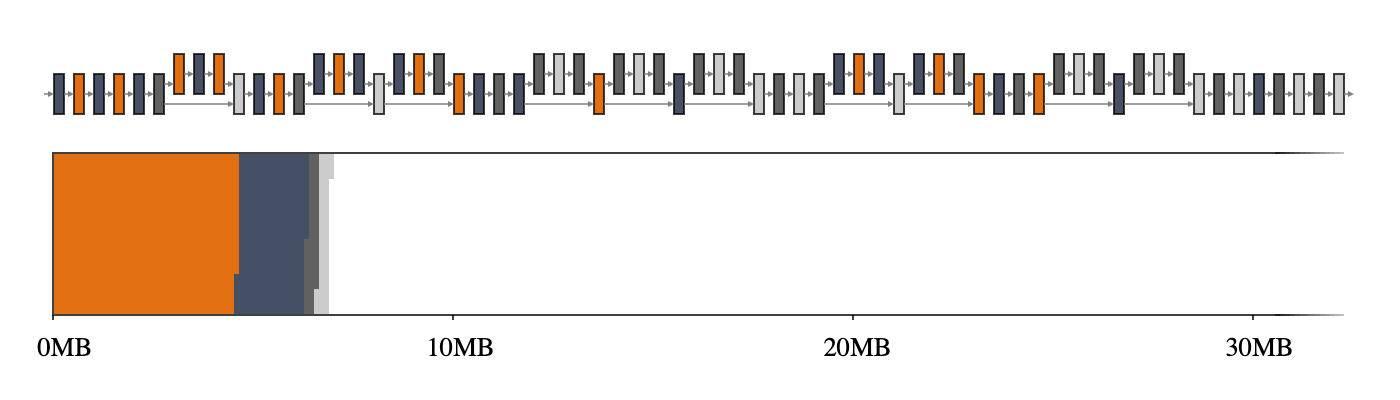
еӣһеҲ°еүҚйқўзҡ„зӨәдҫӢ пјҢ GREEDY_BY_BREADTHеңЁ MobileNet V2 дёҠжү§иЎҢеҫ—жңҖеҘҪ пјҢ е®ғеҲ©з”ЁдәҶжҜҸдёӘиҝҗз®—з¬Ұзҡ„е®ҪеәҰ пјҢ еҚіиҝҗз®—з¬Ұй…ҚзҪ®ж–Ү件дёӯжүҖжңүеј йҮҸзҡ„жҖ»е’Ң гҖӮ еӣҫ 2 пјҢ зү№еҲ«жҳҜдёҺеӣҫ 1 зӣёжҜ”ж—¶ пјҢ зӘҒеҮәжҳҫзӨәдәҶдҪҝз”ЁжҷәиғҪеҶ…еӯҳз®ЎзҗҶеҷЁж—¶ пјҢ еҸҜд»ҘиҺ·еҫ—еӨҡеӨ§зҡ„收зӣҠ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»





![[д»қеҚ“]д»қеҚ“дёәй«ҳиҖғиҲһејҠйҒ“жӯүпјҢзІүдёқзӣІзӣ®еҠӣжҢәпјҡеҮӯе®һеҠӣиҖғдёҠпјҢеӨ§е®¶жІЎеҝ…иҰҒйҖјд»–](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/1bcffc01b5f09cc7043a0f3818fe8f3e.jpg)









- еӨ§дёҖйқһи®Ўз®—жңәдё“дёҡзҡ„еӯҰз”ҹпјҢеҰӮдҪ•еҲ©з”ЁеҜ’еҒҮиҮӘеӯҰCиҜӯиЁҖ
- еҗ‘ж—Ҙи‘өиҝңзЁӢжҺ§еҲ¶дјҒдёҡзүҲе®ўжҲ·з«Ҝжӣҙж–°еҚҮзә§пјҢдјҳеҢ–иҝңжҺ§UIйҖӮй…ҚSADDCеҶ…ж ёз®—жі•
- зәўзұіK40жёІжҹ“еӣҫжӣқе…үпјҡеұ…дёӯжҢ–еӯ”+еҗҺзҪ®еӣӣж‘„пјҢиҝҷеӨ–и§ӮдҪ и§үеҫ—еҰӮдҪ•пјҹ
- и§ҶзҪ‘иҶңдјҳеҢ–пјҹзҙўе°је…·и®ӨзҹҘиғҪеҠӣз”өи§ҶиҠҜзүҮXRжқҘдәҶ
- еҘӢж–—|иҜҘеҰӮдҪ•зңӢеҫ…жӢјеӨҡеӨҡе‘ҳе·ҘзҢқжӯ»пјҡйј“еҠұеҘӢж–—пјҢд№ҹиҰҒдҝқжҠӨеҘҪеҘӢж–—иҖ…
- иЈ…жңәзӮ№дёҚдә® еҰӮдҪ•з®Җжҳ“жҺ’жҹҘ硬件问йўҳпјҹ
- иҷҫзұійҹід№җе®Јеёғе…іеҒңпјҒжҲ‘зҡ„жӯҢеҚ•еҰӮдҪ•еҜје…ҘQQйҹід№җгҖҒзҪ‘жҳ“дә‘йҹід№җпјҹ
- дәәи„ёиҜҶеҲ«и®ҫеӨҮдё»жқҝеҰӮдҪ•йҖүеһӢ иҪҜзЎ¬ж•ҙеҗҲеӨ§е№…зј©зҹӯејҖеҸ‘ж—¶й—ҙ
- еҫ®иҪҜе®ҳж–№ж•°жҚ®жҒўеӨҚе·Ҙе…·еҚіе°Ҷжӣҙж–°пјҡжӣҙжҳ“дәҺдёҠжүӢ дјҳеҢ–жҒўеӨҚжҖ§иғҪ
- Mini-LEDдә§е“Ғж•Ҳжһң究з«ҹеҰӮдҪ•пјҹ