иҝһзҺҜи§ҰеҸ‘пјҒMongoDBж ёеҝғйӣҶзҫӨйӣӘеҙ©ж•…йҡңиғҢеҗҺз«ҹжҳҜвҖҰвҖҰ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮә пјҢ еӯҳеӮЁиҠӮзӮ№еңЁдёҡеҠЎжҠ–еҠЁзҡ„ж—¶еҖҷжІЎжңүд»»дҪ•ж…ўж—Ҙеҝ— пјҢ еӣ жӯӨеҸҜд»ҘеҲӨж–ӯеӯҳеӮЁиҠӮзӮ№дёҖеҲҮжӯЈеёё пјҢ дёҡеҠЎжҠ–еҠЁе’ҢmongodеӯҳеӮЁиҠӮзӮ№ж— е…і гҖӮ
2пјү mongosд»ЈзҗҶеҲҶжһҗ
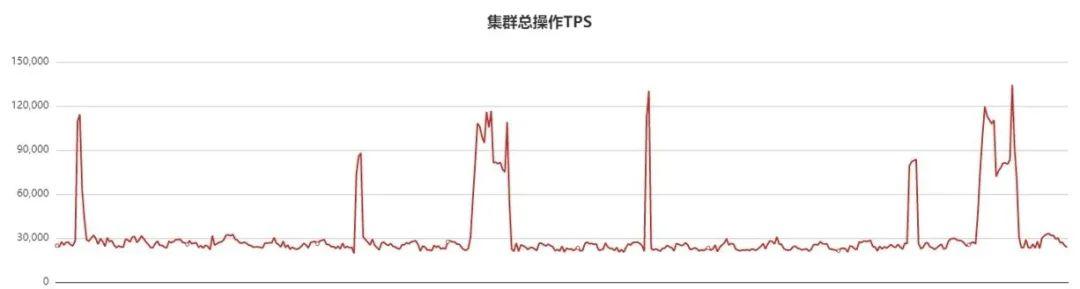
еӯҳеӮЁиҠӮзӮ№жІЎжңүд»»дҪ•й—®йўҳ пјҢ еӣ жӯӨејҖе§ӢжҺ’жҹҘmongosд»ЈзҗҶиҠӮзӮ№ гҖӮ з”ұдәҺеҺҶеҸІеҺҹеӣ пјҢ иҜҘйӣҶзҫӨйғЁзҪІеңЁе…¶д»–е№іеҸ° пјҢ иҜҘе№іеҸ°еҜ№QPSгҖҒ时延зӯүзӣ‘жҺ§дёҚжҳҜеҫҲе…Ё пјҢ йҖ жҲҗж—©жңҹжҠ–еҠЁзҡ„ж—¶еҖҷзӣ‘жҺ§жІЎжңүеҸҠж—¶еҸ‘зҺ° гҖӮ жҠ–еҠЁеҗҺ пјҢ иҝҒ移иҜҘе№іеҸ°йӣҶзҫӨеҲ°oppoиҮӘз ”зҡ„ж–°з®ЎжҺ§е№іеҸ° пјҢ ж–°е№іеҸ°жңүиҜҰз»Ҷзҡ„зӣ‘жҺ§дҝЎжҒҜ пјҢ иҝҒ移еҗҺQPSзӣ‘жҺ§жӣІзәҝеҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
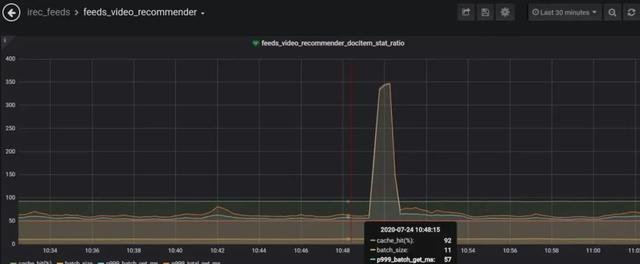
жҜҸдёӘжөҒйҮҸеҫ’еўһж—¶й—ҙзӮ№ пјҢ еҜ№еә”дёҡеҠЎзӣ‘жҺ§йғҪжңүдёҖжіўи¶…ж—¶жҲ–иҖ…жҠ–еҠЁ пјҢ еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҲҶжһҗеҜ№еә”д»ЈзҗҶmongosж—Ҙеҝ— пјҢ еҸ‘зҺ°еҰӮдёӢзҺ°иұЎпјҡжҠ–еҠЁж—¶й—ҙзӮ№mongos.logж—Ҙеҝ—жңүеӨ§йҮҸзҡ„е»әй“ҫжҺҘе’Ңж–ӯй“ҫжҺҘзҡ„иҝҮзЁӢ пјҢ еҰӮдёӢеӣҫжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮә пјҢ дёҖз§’й’ҹеҶ…жңүеҮ еҚғдёӘй“ҫжҺҘе»әз«Ӣ пјҢ еҗҢж—¶жңүеҮ еҚғдёӘй“ҫжҺҘж–ӯејҖ пјҢ жӯӨеӨ–жҠ“еҢ…еҸ‘зҺ°еҫҲеӨҡй“ҫжҺҘзҹӯжңҹеҶ…еҚіж–ӯејҖй“ҫжҺҘ пјҢ зҺ°иұЎеҰӮдёӢ(ж–ӯй“ҫж—¶й—ҙ-е»әй“ҫж—¶й—ҙ=51ms, йғЁеҲҶ100еӨҡmsж–ӯејҖ)пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҜ№еә”жҠ“еҢ…еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
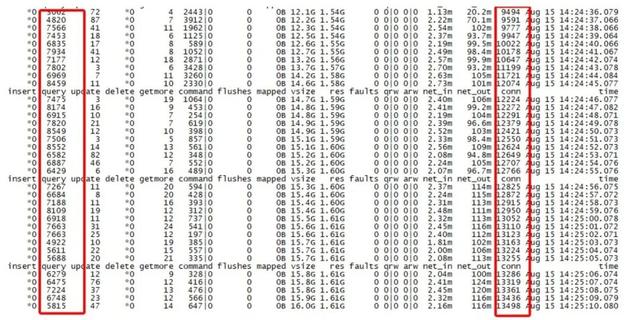
жӯӨеӨ– пјҢ иҜҘжңәеҷЁд»ЈзҗҶдёҠе®ўжҲ·з«Ҝй“ҫжҺҘдҪҺеі°жңҹйғҪеҫҲй«ҳ пјҢ з”ҡиҮіи¶…иҝҮжӯЈеёёзҡ„QPSеҖј пјҢ QPSеӨ§зәҰ7000-8000 пјҢ дҪҶжҳҜconnй“ҫжҺҘзјәй«ҳиҫҫ13000 пјҢ mongostatиҺ·еҸ–еҲ°зӣ‘жҺ§дҝЎжҒҜеҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
3пјүд»ЈзҗҶжңәеҷЁиҙҹиҪҪеҲҶжһҗ
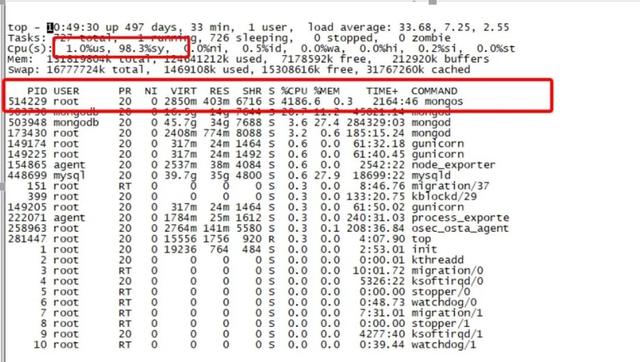
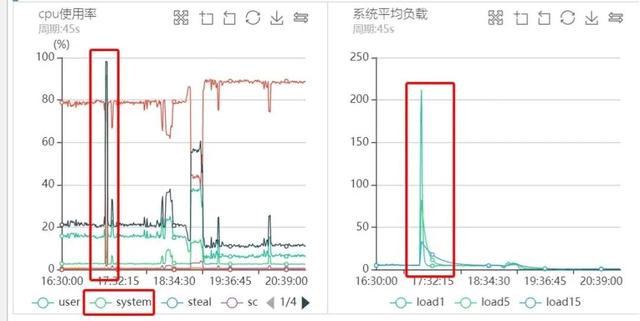
жҜҸж¬ЎзӘҒеҸ‘жөҒйҮҸзҡ„ж—¶еҖҷ пјҢ д»ЈзҗҶиҙҹиҪҪеҫҲй«ҳ пјҢ йҖҡиҝҮйғЁзҪІи„ҡжң¬е®ҡжңҹйҮҮж · пјҢ жҠ–еҠЁж—¶й—ҙзӮ№еҜ№еә”зӣ‘жҺ§еӣҫеҰӮдёӢеӣҫжүҖзӨәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮә пјҢ жҜҸж¬ЎжөҒйҮҸй«ҳеі°зҡ„ж—¶еҖҷCPUиҙҹиҪҪйғҪйқһеёёзҡ„й«ҳ пјҢ иҖҢдё”жҳҜsy%иҙҹиҪҪ пјҢ us%иҙҹиҪҪеҫҲдҪҺ пјҢ еҗҢж—¶Loadз”ҡиҮій«ҳиҫҫеҘҪеҮ зҷҫ пјҢ еҒ¶е°”з”ҡиҮіиҝҮеҚғ гҖӮ
4пјү жҠ–еҠЁеҲҶжһҗжҖ»з»“
д»ҺдёҠйқўзҡ„еҲҶжһҗеҸҜд»ҘзңӢеҮә пјҢ жҹҗдәӣж—¶й—ҙзӮ№дёҡеҠЎжңүзӘҒеҸ‘жөҒйҮҸеј•иө·зі»з»ҹиҙҹиҪҪеҫҲй«ҳ гҖӮ ж №еӣ зңҹзҡ„жҳҜеӣ дёәзӘҒеҸ‘жөҒйҮҸеҗ—пјҹе…¶е®һдёҚ然 пјҢ иҜ·зңӢеҗҺз»ӯеҲҶжһҗ пјҢ иҝҷе…¶е®һжҳҜдёҖдёӘй”ҷиҜҜз»“и®ә гҖӮ жІЎиҝҮеҮ еӨ© пјҢ еҗҢдёҖдёӘйӣҶзҫӨйӣӘеҙ©дәҶ гҖӮ
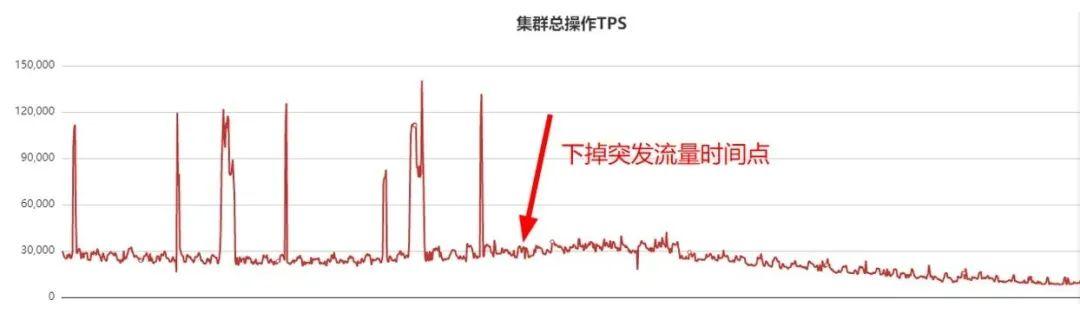
дәҺжҳҜдёҡеҠЎжўізҗҶзӘҒеҸ‘жөҒйҮҸеҜ№еә”жҺҘеҸЈ пјҢ жўізҗҶеҮәжқҘеҗҺдёӢжҺүдәҶиҜҘжҺҘеҸЈ пјҢ QPSзӣ‘жҺ§жӣІзәҝеҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёәдәҶеҮҸе°‘дёҡеҠЎжҠ–еҠЁ пјҢ еӣ жӯӨдёӢжҺүдәҶзӘҒеҸ‘жөҒйҮҸжҺҘеҸЈ пјҢ жӯӨеҗҺеҮ дёӘе°Ҹж—¶дёҡеҠЎдёҚеҶҚжҠ–еҠЁ гҖӮ еҪ“дёӢжҺүзӘҒеҸ‘жөҒйҮҸжҺҘеҸЈеҗҺ пјҢ жҲ‘们иҝҳеҒҡдәҶеҰӮдёӢеҮ 件дәӢжғ…пјҡ
- з”ұдәҺжІЎжүҫеҲ°mongosиҙҹиҪҪ100%зңҹжӯЈеҺҹеӣ пјҢ дәҺжҳҜжҜҸдёӘжңәжҲҝжү©е®№mongsд»ЈзҗҶ пјҢ дҝқжҢҒжҜҸдёӘжңәжҲҝ4дёӘд»ЈзҗҶ пјҢ еҗҢж—¶дҝқиҜҒжүҖжңүд»ЈзҗҶеңЁдёҚеҗҢжңҚеҠЎеҷЁ пјҢ йҖҡиҝҮеҲҶжөҒжқҘе°ҪйҮҸеҮҸе°‘д»ЈзҗҶиҙҹиҪҪ гҖӮ
- йҖҡзҹҘAжңәжҲҝе’ҢBжңәжҲҝзҡ„дёҡеҠЎй…ҚзҪ®дёҠжүҖжңүзҡ„8дёӘд»ЈзҗҶ пјҢ дёҚеҶҚжҳҜжҜҸдёӘжңәжҲҝеҸӘй…ҚзҪ®еҜ№еә”жңәжҲҝзҡ„д»ЈзҗҶ(еӣ дёә第дёҖж¬ЎдёҡеҠЎжҠ–еҠЁеҗҺ пјҢ жҲ‘们еҲҶжһҗMongoDBзҡ„java sdk пјҢ зЎ®е®ҡsdkеқҮиЎЎзӯ–з•ҘдјҡиҮӘеҠЁеү”йҷӨиҜ·жұӮ时延й«ҳзҡ„д»ЈзҗҶ пјҢ дёӢж¬ЎеҰӮжһңжҹҗдёӘд»ЈзҗҶеҶҚеҮәй—®йўҳ пјҢ д№ҹдјҡиў«иҮӘеҠЁеү”йҷӨ) гҖӮ
жҺЁиҚҗйҳ…иҜ»
- centos7 е®үиЈ… MongoDB (еӨҚеҲ¶зІҳиҙҙзі»еҲ—)
- и°·жӯҢиҜҒе®һжңүзәҝиҖіжңәдәҰеҸҜи§ҰеҸ‘Google AssistantйҖҡзҹҘжң—иҜ»еҠҹиғҪ
- еҚҒеҲҶй’ҹдәҶи§ЈMongodbж•°жҚ®еә“
- йҳҝйҮҢеҗҺз«ҜйқўиҜ•е®ҳзҡ„иҝһзҺҜзӮ®пјҢзңӢзңӢдҪ иғҪж’‘еҲ°е“ӘдёҖжӯҘпјҹ
- docker е®үиЈ… MongoDB е°ұжҳҜиҝҷд№Ҳз®ҖеҚ•пјҹ



















