иҝһзҺҜи§ҰеҸ‘пјҒMongoDBж ёеҝғйӣҶзҫӨйӣӘеҙ©ж•…йҡңиғҢеҗҺз«ҹжҳҜвҖҰвҖҰ( дә” )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮә пјҢ е®ўжҲ·з«Ҝ6000并еҸ‘еҸҚеӨҚйҮҚиҝһ пјҢ жңҚеҠЎз«ҜеҺӢеҠӣжӯЈеёё пјҢ жүҖжңүCPUж¶ҲиҖ—еңЁus% пјҢ sy%ж¶ҲиҖ—еҫҲдҪҺ гҖӮ з”ЁжҲ·жҖҒCPUж¶ҲиҖ—3дёӘCPU пјҢ еҶ…ж ёжҖҒCPUж¶ҲиҖ—еҮ д№Һдёә0 пјҢ иҝҷжҳҜжҲ‘们жңҹеҫ…зҡ„жӯЈеёёз»“жһң пјҢ еӣ жӯӨи§үеҫ—иҜҘй—®йўҳеҸҜиғҪе’Ңж“ҚдҪңзі»з»ҹзүҲжң¬жңүй—®йўҳ гҖӮ
дёәдәҶйӘҢиҜҒжӣҙй«ҳ并еҸҚеӨҚе»әй“ҫж–ӯй“ҫеңЁLinux-3.10еҶ…ж ёзүҲжң¬жҳҜеҗҰжңү2.6зүҲжң¬еҗҢж ·зҡ„sy%еҶ…ж ёжҖҒCPUж¶ҲиҖ—й«ҳзҡ„й—®йўҳ пјҢ еӣ жӯӨжҠҠ并еҸ‘д»Һ6000жҸҗеҚҮеҲ°30000 пјҢ йӘҢиҜҒз»“жһңеҰӮдёӢпјҡ
жөӢиҜ•з»“жһңпјҡйҖҡиҝҮдҝ®ж”№MongoDBеҶ…ж ёзүҲжң¬ж•…ж„Ҹи®©е®ўжҲ·з«Ҝи¶…ж—¶еҸҚеӨҚе»әй“ҫж–ӯй“ҫ пјҢ еңЁlinux-2.6зүҲжң¬дёӯ пјҢ 1500д»ҘдёҠзҡ„并еҸ‘еҸҚеӨҚе»әй“ҫж–ӯй“ҫзі»з»ҹCPU sy% 100%зҡ„й—®йўҳеҚіеҸҜжө®зҺ° гҖӮ дҪҶжҳҜ пјҢ еңЁLinux-3.10зүҲжң¬дёӯ пјҢ 并еҸ‘еҲ°10000еҗҺ пјҢ sy%иҙҹиҪҪйҖҗжӯҘеўһеҠ пјҢ 并еҸ‘и¶Ҡй«ҳsy%иҙҹиҪҪи¶Ҡй«ҳ гҖӮ
жҖ»з»“пјҡlinux-2.6зі»з»ҹдёӯ пјҢ MongoDBеҸӘиҰҒжҜҸз§’жңүеҮ еҚғзҡ„еҸҚеӨҚе»әй“ҫж–ӯй“ҫ пјҢ зі»з»ҹsy%иҙҹиҪҪе°ұдјҡжҺҘиҝ‘100% гҖӮ Linux-3.10 пјҢ 并еҸ‘20000еҸҚеӨҚе»әй“ҫж–ӯй“ҫзҡ„ж—¶еҖҷ пјҢ sy%иҙҹиҪҪеҸҜд»ҘиҫҫеҲ°30% пјҢ йҡҸзқҖе®ўжҲ·з«Ҝ并еҸ‘еўһеҠ пјҢ sy%иҙҹиҪҪд№ҹзӣёеә”зҡ„еўһеҠ гҖӮ Linux-3.10зүҲжң¬зӣёжҜ”2.6зүҲжң¬й’ҲеҜ№еҸҚеӨҚе»әй“ҫж–ӯй“ҫзҡ„еңәжҷҜжңүеҫҲеӨ§зҡ„жҖ§иғҪж”№е–„ пјҢ дҪҶжҳҜдёҚиғҪи§ЈеҶіж №жң¬й—®йўҳ гҖӮ
4гҖҒе®ўжҲ·з«ҜеҸҚеӨҚе»әй“ҫж–ӯй“ҫеј•иө·sy% 100%ж №еӣ
дёәдәҶеҲҶжһҗ%syзі»з»ҹиҙҹиҪҪй«ҳзҡ„еҺҹеӣ пјҢ е®үиЈ…perfиҺ·еҸ–зі»з»ҹtopдҝЎжҒҜ пјҢ еҸ‘зҺ°жүҖжңүCPUж¶ҲиҖ—еңЁеҰӮдёӢжҺҘеҸЈпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
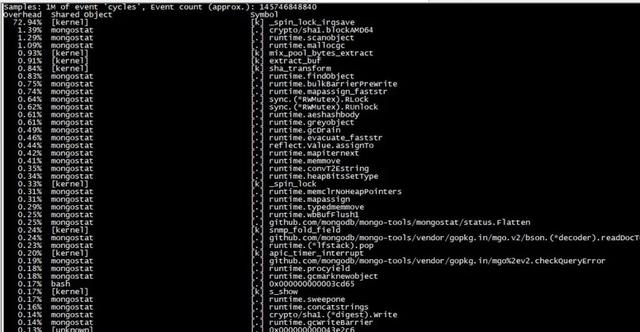
д»ҺperfеҲҶжһҗеҸҜд»ҘзңӢеҮә пјҢ cpu ж¶ҲиҖ—еңЁ_spin_lock_irqsaveеҮҪж•° пјҢ 继з»ӯеҲҶжһҗеҶ…ж ёжҖҒи°ғз”Ёж Ҳ пјҢ еҫ—еҲ°еҰӮдёӢе Ҷж ҲдҝЎжҒҜпјҡ
- 89.81% 89.81% [kernel] [k] _spin_lock_irqsave - _spin_lock_irqsave
- mix_pool_bytes_extract
- extract_buf
extract_entropy_user
urandom_read
vfs_read
sys_read
system_call_fastpath
0xe82d
дёҠйқўзҡ„е Ҷж ҲдҝЎжҒҜиҜҙжҳҺ пјҢ MongoDBеңЁиҜ»еҸ– /dev/urandomпјҢ 并且з”ұдәҺеӨҡдёӘзәҝзЁӢеҗҢж—¶иҜ»еҸ–иҜҘж–Ү件 пјҢ еҜјиҮҙж¶ҲиҖ—еңЁдёҖжҠҠspinlockдёҠ гҖӮ
еҲ°иҝҷйҮҢй—®йўҳиҝӣдёҖжӯҘжҳҺжң—дәҶ пјҢ ж•…йҡңroot case дёҚжҳҜжҜҸз§’еҮ дёҮзҡ„иҝһжҺҘж•°еҜјиҮҙsys иҝҮй«ҳеј•иө· гҖӮ ж №жң¬еҺҹеӣ жҳҜжҜҸдёӘmongoе®ўжҲ·з«Ҝзҡ„ж–°й“ҫжҺҘдјҡеҜјиҮҙMongoDBеҗҺз«Ҝж–°е»әдёҖдёӘзәҝзЁӢ пјҢ иҜҘзәҝзЁӢеңЁжҹҗз§Қжғ…еҶөдёӢдјҡи°ғз”Ёurandom_read еҺ»иҜ»еҸ–йҡҸжңәж•°/dev/urandomпјҢ 并且з”ұдәҺеӨҡдёӘзәҝзЁӢеҗҢж—¶иҜ»еҸ– пјҢ еҜјиҮҙеҶ…ж ёжҖҒж¶ҲиҖ—еңЁдёҖжҠҠspinlockй”ҒдёҠ пјҢ еҮәзҺ°cpu й«ҳзҡ„зҺ°иұЎ гҖӮ
5гҖҒMongoDBеҶ…ж ёйҡҸжңәж•°дјҳеҢ–
1пјү MongoDBеҶ…ж ёжәҗз Ғе®ҡдҪҚеҲҶжһҗ
дёҠйқўзҡ„еҲҶжһҗе·Із»ҸзЎ®е®ҡ пјҢ й—®йўҳж №жәҗжҳҜMongoDBеҶ…ж ёеӨҡдёӘзәҝзЁӢиҜ»еҸ–/dev/urandomйҡҸжңәж•°еј•иө· пјҢ иө°иҜ»MongoDBеҶ…ж ёд»Јз Ғ пјҢ еҸ‘зҺ°иҜ»еҸ–иҜҘж–Ү件зҡ„ең°ж–№еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёҠйқўжҳҜз”ҹжҲҗйҡҸжңәж•°зҡ„ж ёеҝғд»Јз Ғ пјҢ жҜҸж¬ЎиҺ·еҸ–йҡҸжңәж•°йғҪдјҡиҜ»еҸ–вҖқ/dev/urandomвҖқзі»з»ҹж–Ү件 пјҢ жүҖд»ҘеҸӘиҰҒжүҫеҲ°дҪҝз”ЁиҜҘжҺҘеҸЈзҡ„ең°ж–№еҚіеҸҜеҚіеҸҜеҲҶжһҗеҮәй—®йўҳ гҖӮ
继з»ӯиө°иҜ»д»Јз Ғ пјҢ еҸ‘зҺ°дё»иҰҒеңЁеҰӮдёӢең°ж–№пјҡ
//жңҚеҠЎз«Ҝ收еҲ°е®ўжҲ·з«Ҝsaslи®ӨиҜҒзҡ„第дёҖдёӘжҠҘж–ҮеҗҺзҡ„еӨ„зҗҶ пјҢ иҝҷйҮҢдјҡз”ҹжҲҗйҡҸжңәж•°
//еҰӮжһңжҳҜmongos пјҢ иҝҷйҮҢе°ұжҳҜжҺҘ收客жҲ·з«Ҝsaslи®ӨиҜҒзҡ„第дёҖдёӘжҠҘж–Үзҡ„еӨ„зҗҶжөҒзЁӢ
Sasl_scramsha1_server_conversation::_firstStep(...) {... ...
unique_ptr sr(SecureRandom::create);binaryNonce[0] = sr->nextInt64;
binaryNonce[1] = sr->nextInt64;
binaryNonce[2] = sr->nextInt64;
... ...
}
//mongosзӣёжҜ”mongodеӯҳеӮЁиҠӮзӮ№е°ұжҳҜе®ўжҲ·з«Ҝ пјҢ mongosдҪңдёәе®ўжҲ·з«Ҝд№ҹйңҖиҰҒз”ҹжҲҗйҡҸжңәж•°
SaslSCRAMSHA1ClientConversation::_firstStep(...) {... ...
unique_ptr sr(SecureRandom::create);binaryNonce[0] = sr->nextInt64;
binaryNonce[1] = sr->nextInt64;
жҺЁиҚҗйҳ…иҜ»














- centos7 е®үиЈ… MongoDB (еӨҚеҲ¶зІҳиҙҙзі»еҲ—)
- и°·жӯҢиҜҒе®һжңүзәҝиҖіжңәдәҰеҸҜи§ҰеҸ‘Google AssistantйҖҡзҹҘжң—иҜ»еҠҹиғҪ
- еҚҒеҲҶй’ҹдәҶи§ЈMongodbж•°жҚ®еә“
- йҳҝйҮҢеҗҺз«ҜйқўиҜ•е®ҳзҡ„иҝһзҺҜзӮ®пјҢзңӢзңӢдҪ иғҪж’‘еҲ°е“ӘдёҖжӯҘпјҹ
- docker е®үиЈ… MongoDB е°ұжҳҜиҝҷд№Ҳз®ҖеҚ•пјҹ