иҝһзҺҜи§ҰеҸ‘пјҒMongoDBж ёеҝғйӣҶзҫӨйӣӘеҙ©ж•…йҡңиғҢеҗҺз«ҹжҳҜвҖҰвҖҰ( дёү )
- еӯҳеӮЁиҠӮзӮ№4дёӘ пјҢ д»ЈзҗҶиҠӮзӮ№5дёӘ пјҢ еӯҳеӮЁиҠӮзӮ№ж— д»»дҪ•жҠ–еҠЁпјҢ еҸҚиҖҢдёғеұӮиҪ¬еҸ‘зҡ„д»ЈзҗҶиҙҹиҪҪй«ҳпјҹ
- дёәдҪ•жҠ“еҢ…еҸ‘зҺ°еҫҲеӨҡж–°иҝһжҺҘеҮ еҚҒmsжҲ–иҖ…дёҖзҷҫеӨҡmsеҗҺе°ұж–ӯејҖиҝһжҺҘдәҶпјҹйў‘з№Ғе»әй“ҫж–ӯй“ҫпјҹ
- дёәдҪ•д»ЈзҗҶQPSеҸӘжңүеҮ дёҮ пјҢ иҝҷж—¶д»ЈзҗҶCPUж¶ҲиҖ—е°ұйқһеёёй«ҳ пјҢ иҖҢдё”е…ЁжҳҜsy%зі»з»ҹиҙҹиҪҪпјҹд»ҘжҲ‘еӨҡе№ҙдёӯй—ҙ件代зҗҶз ”еҸ‘з»ҸйӘҢ пјҢ д»ЈзҗҶж¶ҲиҖ—зҡ„иө„жәҗеҫҲе°‘жүҚеҜ№ пјҢ иҖҢдё”CPUеҸӘдјҡж¶ҲиҖ—us% пјҢ иҖҢдёҚжҳҜsy%ж¶ҲиҖ— гҖӮ
еҘҪжҷҜдёҚй•ҝ пјҢ дёҡеҠЎдёӢжҺүзӘҒеҸ‘жөҒйҮҸзҡ„жҺҘеҸЈжІЎиҝҮеҮ еӨ© пјҢ жӣҙдёҘйҮҚзҡ„ж•…йҡңеҮәзҺ°дәҶ пјҢ жңәжҲҝBзҡ„дёҡеҠЎжөҒйҮҸеңЁжҹҗдёҖж—¶еҲ»зӣҙжҺҘи·Ң0дәҶ пјҢ дёҚжҳҜз®ҖеҚ•зҡ„жҠ–еҠЁй—®йўҳ пјҢ иҖҢжҳҜдёҡеҠЎзӣҙжҺҘжөҒйҮҸи·Ң0 пјҢ зі»з»ҹsy%иҙҹиҪҪ100% пјҢ дёҡеҠЎеҮ д№Һ100%и¶…ж—¶йҮҚиҝһ гҖӮ
1пјүжңәеҷЁзі»з»ҹзӣ‘жҺ§еҲҶжһҗ
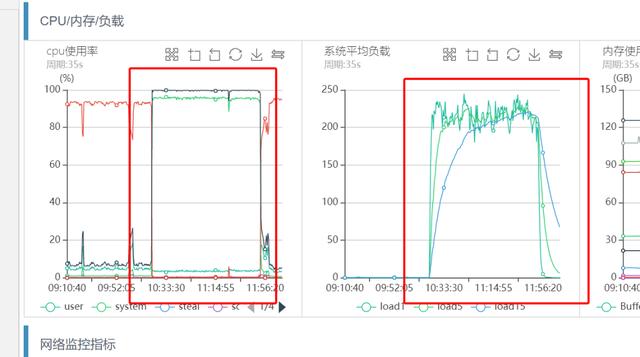
жңәеҷЁCPUе’Ңзі»з»ҹиҙҹиҪҪзӣ‘жҺ§еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫд»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮә пјҢ еҮ д№Һе’ҢеүҚйқўзҡ„зӘҒеҸ‘жөҒйҮҸеј•иө·зҡ„зі»з»ҹиҙҹиҪҪиҝҮй«ҳзҺ°иұЎдёҖиҮҙ пјҢ дёҡеҠЎCPU sy%иҙҹиҪҪ100% пјҢ loadеҫҲй«ҳ гҖӮ зҷ»йҷҶжңәеҷЁиҺ·еҸ–topдҝЎжҒҜ пјҢ зҺ°иұЎе’Ңзӣ‘жҺ§дёҖиҮҙ гҖӮ
 ж–Үз« жҸ’еӣҫ
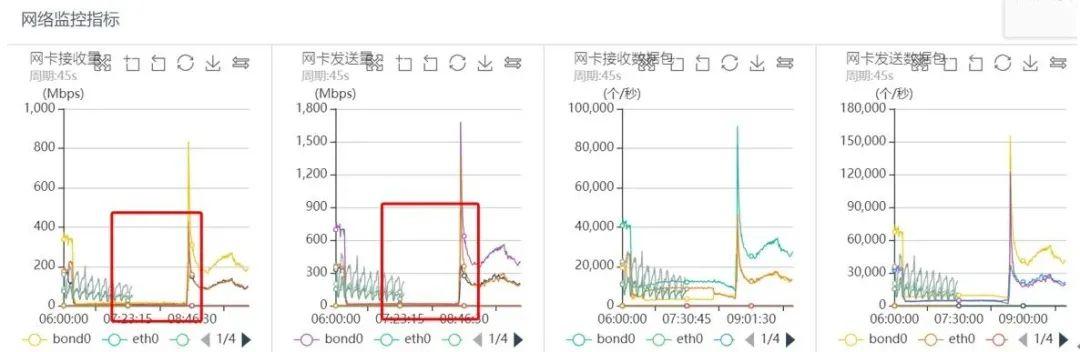
ж–Үз« жҸ’еӣҫеҗҢдёҖж—¶еҲ»еҜ№еә”зҪ‘з»ңзӣ‘жҺ§еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
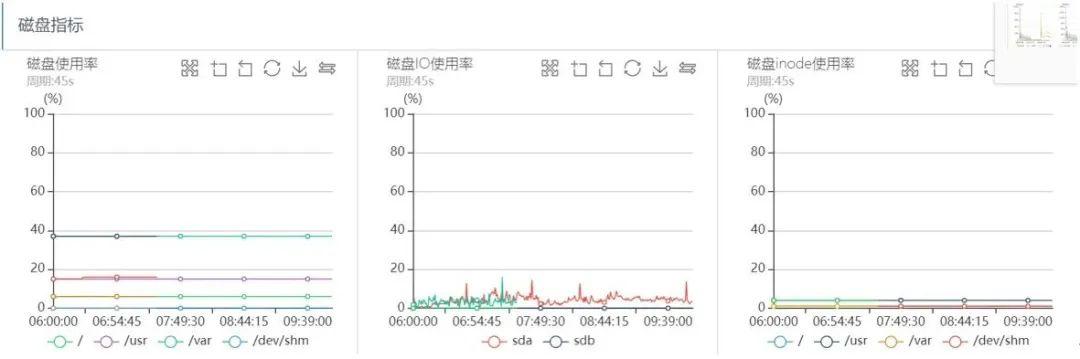
ж–Үз« жҸ’еӣҫзЈҒзӣҳIOзӣ‘жҺ§еҰӮдёӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ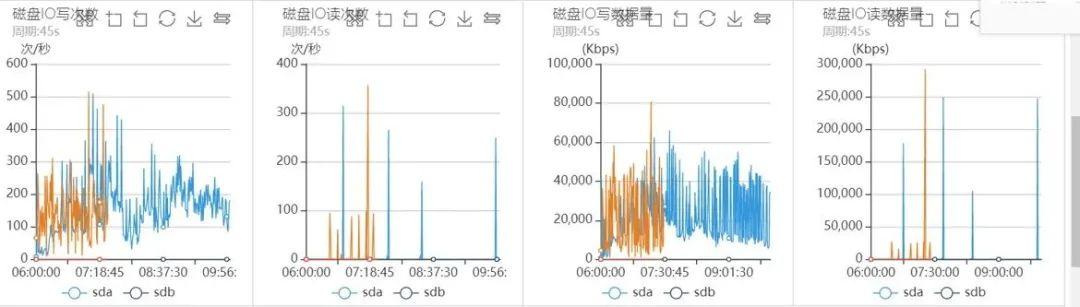 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫд»ҺдёҠйқўзҡ„зі»з»ҹзӣ‘жҺ§еҲҶжһҗеҸҜд»ҘзңӢеҮә пјҢ еҮәй—®йўҳзҡ„ж—¶й—ҙж®ө пјҢ зі»з»ҹCPU sy%гҖҒloadиҙҹиҪҪйғҪеҫҲй«ҳ пјҢ зҪ‘з»ңиҜ»еҶҷжөҒйҮҸеҮ д№Һи·Ң0 пјҢ зЈҒзӣҳIOдёҖеҲҮжӯЈеёё пјҢ еҸҜд»ҘзңӢеҮәж•ҙдёӘиҝҮзЁӢеҮ д№Һе’Ңд№ӢеүҚзӘҒеҸ‘жөҒйҮҸеј•иө·зҡ„жҠ–еҠЁй—®йўҳе®Ңе…ЁдёҖиҮҙ гҖӮ
2пјү дёҡеҠЎеҰӮдҪ•жҒўеӨҚ
第дёҖж¬ЎзӘҒеҸ‘жөҒйҮҸеј•иө·зҡ„жҠ–еҠЁй—®йўҳеҗҺ пјҢ жҲ‘们жү©е®№жүҖжңүзҡ„д»ЈзҗҶеҲ°8дёӘ пјҢ еҗҢж—¶йҖҡзҹҘдёҡеҠЎжҠҠжүҖжңүдёҡеҠЎжҺҘеҸЈй…ҚзҪ®дёҠжүҖжңүд»ЈзҗҶ гҖӮ з”ұдәҺдёҡеҠЎжҺҘеҸЈдј—еӨҡ пјҢ жңҖз»ҲBжңәжҲҝзҡ„дёҡеҠЎжІЎжңүй…ҚзҪ®е…ЁйғЁд»ЈзҗҶ пјҢ еҸӘй…ҚзҪ®дәҶеҺҹе…Ҳзҡ„дёӨдёӘеӨ„дәҺеҗҢдёҖеҸ°зү©зҗҶжңәзҡ„д»ЈзҗҶ(4.4.4.4:1111,4.4.4.4:2222) пјҢ жңҖз»Ҳи§ҰеҸ‘MongoDBзҡ„дёҖдёӘжҖ§иғҪ瓶йўҲ(иҜҰи§ҒеҗҺйқўеҲҶжһҗ) пјҢ еј•иө·дәҶж•ҙдёӘMongoDBйӣҶзҫӨвҖқйӣӘеҙ©вҖқ
жңҖз»Ҳ пјҢ дёҡеҠЎйҖҡиҝҮйҮҚеҗҜжңҚеҠЎ пјҢ еҗҢж—¶жҠҠBжңәжҲҝзҡ„8дёӘд»ЈзҗҶеҗҢж—¶й…ҚзҪ®дёҠ пјҢ й—®йўҳеҫ—д»Ҙи§ЈеҶі гҖӮ
3пјү mongosд»ЈзҗҶе®һдҫӢзӣ‘жҺ§еҲҶжһҗ
еҲҶжһҗиҜҘж—¶й—ҙж®өд»ЈзҗҶж—Ҙеҝ— пјҢ еҸҜд»ҘзңӢеҮәе’ҢдёҠиҝ°з¬¬дёҖзӮ№еҗҢж ·зҡ„зҺ°иұЎ пјҢ еӨ§йҮҸзҡ„ж–°й”®иҝһжҺҘ пјҢ еҗҢж—¶ж–°иҝһжҺҘеңЁеҮ еҚҒmsгҖҒдёҖзҷҫеӨҡmsеҗҺеҸҲе…ій—ӯиҝһжҺҘ гҖӮ ж•ҙдёӘзҺ°иұЎе’Ңд№ӢеүҚеҲҶжһҗдёҖиҮҙ пјҢ иҝҷйҮҢдёҚеңЁз»ҹи®ЎеҲҶжһҗеҜ№еә”ж—Ҙеҝ— гҖӮ
жӯӨеӨ– пјҢ еҲҶжһҗеҪ“ж—¶зҡ„д»ЈзҗҶQPSзӣ‘жҺ§ пјҢ жӯЈеёёqueryиҜ»иҜ·жұӮзҡ„QPSи®ҝй—®жӣІзәҝеҰӮдёӢ пјҢ ж•…йҡңж—¶й—ҙж®өQPSеҮ д№Һи·Ңйӣ¶йӣӘеҙ©дәҶпјҡ
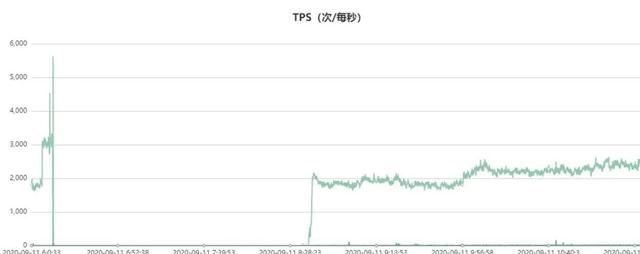 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫCommandз»ҹи®Ўзӣ‘жҺ§жӣІзәҝеҰӮдёӢпјҡ
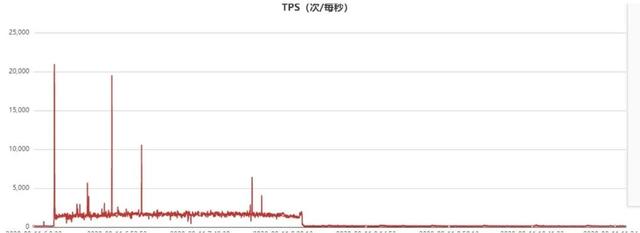 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫд»ҺдёҠйқўзҡ„з»ҹи®ЎеҸҜд»ҘзңӢеҮә пјҢ еҪ“иҜҘд»ЈзҗҶиҠӮзӮ№зҡ„жөҒйҮҸж•…йҡңж—¶й—ҙзӮ№жңүдёҖжіўе°–еҲә пјҢ еҗҢж—¶иҜҘж—¶й—ҙзӮ№зҡ„commandз»ҹи®Ўзһ¬й—ҙйЈҷж¶ЁеҲ°22000(е®һйҷ…еҸҜиғҪжӣҙй«ҳ пјҢ еӣ дёәжҲ‘们зӣ‘жҺ§йҮҮж ·е‘Ёжңҹ30s,иҝҷйҮҢеҸӘжҳҜе№іеқҮеҖј) пјҢ д№ҹе°ұжҳҜзһ¬й—ҙжңү2.2дёҮдёӘиҝһжҺҘзһ¬й—ҙиҝӣжқҘдәҶ гҖӮ Commandз»ҹи®Ўе®һйҷ…дёҠжҳҜdb.ismasterз»ҹи®Ў пјҢ е®ўжҲ·з«ҜconnectжңҚеҠЎз«ҜжҲҗеҠҹеҗҺзҡ„第дёҖдёӘжҠҘж–Үе°ұжҳҜismasterжҠҘж–Ү пјҢ жңҚеҠЎз«Ҝжү§иЎҢdb.ismasterеҗҺеә”зӯ”е®ўжҲ·з«Ҝ пјҢ е®ўжҲ·з«Ҝ收еҲ°еҗҺејҖе§ӢжӯЈејҸзҡ„saslи®ӨиҜҒжөҒзЁӢ гҖӮ
жӯЈеёёе®ўжҲ·з«Ҝи®ҝй—®жөҒзЁӢеҰӮдёӢпјҡ
жҺЁиҚҗйҳ…иҜ»














- centos7 е®үиЈ… MongoDB (еӨҚеҲ¶зІҳиҙҙзі»еҲ—)
- и°·жӯҢиҜҒе®һжңүзәҝиҖіжңәдәҰеҸҜи§ҰеҸ‘Google AssistantйҖҡзҹҘжң—иҜ»еҠҹиғҪ
- еҚҒеҲҶй’ҹдәҶи§ЈMongodbж•°жҚ®еә“
- йҳҝйҮҢеҗҺз«ҜйқўиҜ•е®ҳзҡ„иҝһзҺҜзӮ®пјҢзңӢзңӢдҪ иғҪж’‘еҲ°е“ӘдёҖжӯҘпјҹ
- docker е®үиЈ… MongoDB е°ұжҳҜиҝҷд№Ҳз®ҖеҚ•пјҹ