дёәAIиҖҢз”ҹзҡ„IPUиҠҜзүҮпјҢжҲ–жҢ‘жҲҳGPUзҡ„йңёдё»дҪҚпјҹ
еңЁCPUиҠҜзүҮйўҶеҹҹ пјҢ 延з»ӯиҮід»Ҡзҡ„вҖңж‘©е°”е®ҡеҫӢвҖқжӯЈеңЁйҡҸзқҖеҲ¶зЁӢе·ҘиүәйҖјиҝ‘зү©зҗҶжһҒйҷҗиҖҢжңүдәҶ延缓зҡ„и¶ӢеҠҝ пјҢ з”ҡиҮіеӨұж•Ҳзҡ„еҸҜиғҪ гҖӮ е°ұеңЁж‘©е°”е®ҡеҫӢзҡ„еўһй•ҝж”ҫзј“и„ҡжӯҘзҡ„еҗҢж—¶ пјҢ еҚҠеҜјдҪ“иҠҜзүҮзҡ„и®Ўз®—д№ҹжӯЈеңЁд»ҺйҖҡз”Ёиө°еҗ‘дё“з”Ё пјҢ е…¶дёӯAIи®Ўз®—жӯЈжҳҜе…¶дёӯеўһй•ҝжңҖеҝ«зҡ„дёҖз§Қдё“з”Ёи®Ўз®— гҖӮзҺ°еңЁ пјҢ AIи®Ўз®—жӯЈеңЁжҺҘжЈ’ж‘©е°”е®ҡеҫӢ пјҢ 延з»ӯ并超и¶Ҡе…¶еҖҚеўһзҘһиҜқ гҖӮ 2019е№ҙ пјҢ OpenAIеҸ‘еёғдәҶAIз®—еҠӣзҡ„еўһй•ҝжғ…еҶө пјҢ з»“жһңжҳҫзӨәAIз®—еҠӣд»Ҙ3.4дёӘжңҲзҡ„еҖҚеўһж—¶й—ҙе®һзҺ°дәҶжҢҮж•°еўһй•ҝ пјҢ д»Һ2012е№ҙиө· пјҢ иҜҘжҢҮж Үе·Із»Ҹеўһй•ҝдәҶ30дёҮеҖҚ гҖӮеңЁAIз®—еҠӣзҲҶзӮёејҸеўһй•ҝзҡ„иҝҮзЁӢдёӯ пјҢ иӢұдјҹиҫҫзҡ„GPUеҠҹдёҚеҸҜжІЎ гҖӮ е№ҝдёәдәәзҹҘзҡ„дёҖдёӘж•…дәӢе°ұжҳҜ2012е№ҙ пјҢ жқҘиҮӘеӨҡдјҰеӨҡеӨ§еӯҰзҡ„Alexе’Ңд»–зҡ„еӣўйҳҹи®ҫи®ЎдәҶAlexNetзҡ„ж·ұеәҰеӯҰд№ з®—жі• пјҢ 并用дәҶ2дёӘиӢұдјҹиҫҫзҡ„GTX580 GPUиҝӣиЎҢи®ӯз»ғеҗҺ пјҢ жү“иҙҘдәҶе…¶д»–жүҖжңүи®Ўз®—жңәи§Ҷи§үеӣўйҳҹејҖеҸ‘зҡ„з®—жі• пјҢ жҲҗдёәйӮЈдёҖеұҠImageNetзҡ„еҶ еҶӣ гҖӮжӯӨеҗҺ пјҢ еңЁи®Ўз®—жңәи§Ҷи§үе’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹ пјҢ GPUзҡ„й«ҳ并иЎҢи®Ўз®—иғҪеҠӣеҫ—еҲ°дәҶе……еҲҶзҡ„еҸ‘жҢҘ пјҢ иӢұдјҹиҫҫзҡ„GPUд№ҹйҡҸзқҖAI第дёүж¬ЎжөӘжҪ®зҡ„еҙӣиө·иҖҢиҝҺжқҘдә•е–·еҸ‘еұ• гҖӮ дёҺжӯӨеҗҢж—¶ пјҢ жӣҙеӨҡдёәжңәеҷЁеӯҰд№ иҖҢдё“й—Ёе®ҡеҲ¶зҡ„дё“з”ЁиҠҜзүҮејҖе§ӢеҮәзҺ° пјҢ жҜ”еҰӮдё“з”ЁйӣҶжҲҗз”өи·ҜпјҲASICпјүзҡ„еј йҮҸеӨ„зҗҶеҚ•е…ғTPUгҖҒзҘһз»ҸзҪ‘з»ңеҚ•е…ғNPUд»ҘеҸҠеҚҠе®ҡеҲ¶иҠҜзүҮFPGAзӯүзӯү гҖӮ2018е№ҙеә• пјҢ иӢұеӣҪдёҖ家еҗҚдёәGraphcoreзҡ„еҲӣдёҡе…¬еҸёжҺЁеҮәдәҶдёҖз§Қдё“й—Ёз”ЁдәҺAIи®Ўз®—зҡ„еӨ„зҗҶеҷЁиҠҜзүҮIPUпјҲIntelligence Processing Unitпјү гҖӮ дёҖз»Ҹй—®дё– пјҢ IPUе°ұеҸ—еҲ°AIз•Ңи¶ҠжқҘи¶ҠеӨҡзҡ„е…іжіЁ гҖӮ
ARMеҲӣе§Ӣдәә пјҢ иў«з§°дёәиӢұеӣҪеҚҠеҜјдҪ“д№ӢзҲ¶зҡ„иө«жӣјВ·иұӘз‘ҹжӣҫдёәGraphcoreзҡ„IPUз»ҷеҮәеҫҲй«ҳиҜ„д»· пјҢ е°Ҷе…¶иӘүдёәвҖңи®Ўз®—жңәеҸІдёҠдёүж¬Ўйқ©е‘Ҫдёӯ пјҢ 继CPUе’ҢGPUд№ӢеҗҺзҡ„第дёүж¬Ўйқ©е‘ҪвҖқ гҖӮ иө«жӣјеңЁиҠҜзүҮдә§дёҡзҡ„ең°дҪҚиҮӘ然дёҚе®№зҪ®з–‘ пјҢ дҪҶз”ұдәҺGraphcoreжҳҜиӢұеӣҪиҠҜзүҮдә§дёҡдёӯдёәж•°дёҚеӨҡзҡ„ж–°з”ҹеҠӣйҮҸ пјҢ йҡҫе…Қиө«жӣјжңүвҖңжҠӨзҠҠеӯҗвҖқзҡ„жү“е№ҝе‘Ҡд№Ӣе«Ң гҖӮIPUеҮәйҒ“2е№ҙж—¶й—ҙ пјҢ зҺ°е·ІжҺЁеҮәдәҶйҮҸдә§з¬¬дәҢд»ЈеһӢеҸ·дёәGC2зҡ„IPU гҖӮ йӮЈд№Ҳ пјҢ IPUзҡ„иЎЁзҺ°еҰӮдҪ• пјҢ дёҺGPUзӣёжҜ”жңүе“ӘдәӣдјҳеҠҝд№ӢеӨ„ пјҢ иҝҷжҳҜжң¬ж–ҮиҰҒйҮҚзӮ№жҺўи®Ёзҡ„й—®йўҳ гҖӮGPUжүҖејҖеҗҜзҡ„ж·ұеәҰеӯҰд№ дёҖдёӘе№ҝдёәдәә们зҶҹзҹҘзҡ„дҫӢеӯҗе°ұжҳҜ пјҢ еңЁи®Ўз®—жңәи§Ҷи§үеҸ‘еұ•еҲқжңҹзҡ„2011е№ҙ пјҢ и°·жӯҢеӨ§и„‘жғіиҰҒеңЁYouTubeзҡ„и§Ҷйў‘дёӯиҜҶеҲ«дәәзұ»е’ҢзҢ« пјҢ еҪ“ж—¶иҝҷж ·дёҖдёӘз®ҖеҚ•зҡ„д»»еҠЎ пјҢ и°·жӯҢиҰҒеҠЁз”ЁдёҖ家еӨ§еһӢж•°жҚ®дёӯеҝғеҶ…зҡ„ 2,000 йў—жңҚеҠЎеҷЁ CPU пјҢ иҝҷдәӣCPUзҡ„иҝҗиЎҢдјҡдә§з”ҹеӨ§йҮҸзҡ„зғӯйҮҸе’ҢиғҪиҖ— пјҢ е…ій”®жҳҜд»Јд»·дёҚиҸІ пјҢ еҫҲе°‘иғҪжңүз ”з©¶дәәе‘ҳеҸҜд»Ҙз”Ёеҫ—иө·иҝҷз§Қ规模зҡ„жңҚеҠЎеҷЁ гҖӮ
дёҚиҝҮеңЁеҪ“ж—¶ пјҢ з ”з©¶дәәе‘ҳжіЁж„ҸеҲ°дәҶиӢұдјҹиҫҫзҡ„GPU пјҢ ж–ҜеқҰзҰҸеӨ§еӯҰзҡ„еҗҙжҒ©иҫҫеӣўйҳҹејҖе§Ӣе’ҢиӢұдјҹиҫҫеҗҲдҪң пјҢ е°ҶGPUеә”з”ЁдәҺж·ұеәҰеӯҰд№ гҖӮ еҗҺжқҘиҜҒжҳҺ пјҢ еҸӘйңҖиҰҒ12йў—иӢұдјҹиҫҫGPUе°ұеҸҜд»ҘиҫҫеҲ°зӣёеҪ“дәҺ2000йў—CPUжҸҗдҫӣзҡ„ж·ұеәҰеӯҰд№ жҖ§иғҪ гҖӮ жӯӨеҗҺи¶ҠжқҘи¶ҠеӨҡзҡ„AIз ”з©¶дәәе‘ҳејҖе§ӢеңЁGPUдёҠеҠ йҖҹе…¶ж·ұеәҰзҘһз»ҸзҪ‘з»ң (DNN)зҡ„и®ӯз»ғ гҖӮ
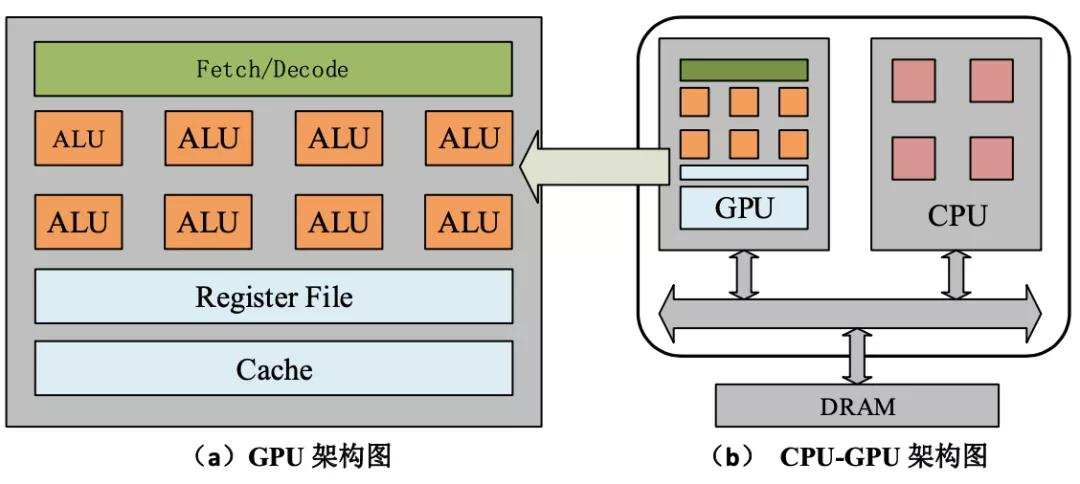
зҺ°еңЁжҲ‘们йғҪзҹҘйҒ“ пјҢ GPUиғҪеӨҹеңЁж·ұеәҰеӯҰд№ зҡ„и®ӯз»ғдёӯеӨ§жҳҫиә«жүӢ пјҢ жӯЈжҳҜжәҗдәҺGPUзҡ„и®Ўз®—жһ¶жһ„жӯЈеҘҪйҖӮз”ЁдәҺж·ұеәҰеӯҰд№ зҡ„и®Ўз®—жЁЎејҸ гҖӮ ж·ұеәҰеӯҰд№ жҳҜдёҖз§Қе…Ёж–°зҡ„и®Ўз®—жЁЎејҸ пјҢ е…¶йҮҮз”Ёзҡ„DNNз®—жі•еҢ…еҗ«ж•°еҚҒдәҝдёӘзҪ‘з»ңзҘһз»Ҹе…ғе’Ңж•°дёҮдәҝдёӘиҝһжҺҘжқҘиҝӣиЎҢ并иЎҢи®ӯз»ғ пјҢ 并д»Һе®һдҫӢдёӯиҮӘе·ұеӯҰд№ и§„еҫӢ гҖӮж·ұеәҰеӯҰд№ з®—жі•дё»иҰҒдҫқиө–зҡ„еҹәжң¬иҝҗз®—ж–№жі•жңүзҹ©йҳөзӣёз§°е’ҢеҚ·з§Ҝжө®зӮ№иҝҗз®— пјҢ иҖҢGPUеӨҡж ёжһ¶жһ„еңЁеҺҹжң¬еӣҫеғҸжёІжҹ“дёӯеҸҜд»ҘеӨ§и§„жЁЎеӨ„зҗҶзҹ©йҳөд№ҳжі•иҝҗз®—е’Ңжө®зӮ№иҝҗз®— пјҢ еҫҲеҘҪең°еҸҜд»ҘеӨ„зҗҶ并иЎҢи®Ўз®—д»»еҠЎ пјҢ дҪҝеҫ—DNNи®ӯз»ғйҖҹеәҰеӨ§е№…жҸҗеҚҮ гҖӮжӯӨеҗҺ пјҢ GPUжҲҗдёәиҫ…еҠ©е®ҢжҲҗж·ұеәҰеӯҰд№ з®—жі•зҡ„дё»жөҒи®Ўз®—е·Ҙе…· пјҢ еӨ§ж”ҫејӮеҪ© гҖӮ дҪҶGPUжң¬иә«е№¶йқһжҳҜдё“й—ЁдёәAIи®Ўз®—иҖҢи®ҫи®Ўзҡ„иҠҜзүҮ пјҢ е…¶дёӯжңүеӨ§йҮҸзҡ„йҖ»иҫ‘и®Ўз®—еҜ№дәҺAIз®—жі•жқҘиҜҙжҜ«ж— з”ЁеӨ„ пјҢ жүҖд»ҘиЎҢдёҡиҮӘ然д№ҹйңҖиҰҒдё“й—Ёй’ҲеҜ№AIз®—жі•зҡ„дё“з”ЁAIиҠҜзүҮ гҖӮиҝ‘еҮ е№ҙ пјҢ е…Ёзҗғе·Із»ҸжңүдёҠзҷҫ家公еҸёжҠ•е…ҘеҲ°ж–°еһӢAIиҠҜзүҮзҡ„з ”еҸ‘е’Ңи®ҫи®ЎеҪ“дёӯ пјҢ еҪ“然жңҖз»ҲиғҪеӨҹжҲҗеҠҹжөҒзүҮ并жҺЁеҮәе•Ҷз”Ёзҡ„д»Қ然жҳҜеҮ 家巨еӨҙе…¬еҸёе’Ңе°‘ж•°е®һеҠӣйӣ„еҺҡзҡ„зӢ¬и§’е…Ҫе…¬еҸё гҖӮиҝҷе…¶дёӯ пјҢ 2017е№ҙеҲқеҲӣжҲҗз«Ӣзҡ„GraphcoreжүҖз ”еҸ‘зҡ„AIиҠҜзүҮIPU пјҢ еҲҷжҲҗдёәиҝҷдәӣAIиҠҜзүҮеҪ“дёӯзҡ„еҸҰзұ»д»ЈиЎЁ пјҢ еӣ е…¶дёҚеҗҢдәҺGPUжһ¶жһ„зҡ„еҲӣж–°еҫ—еҲ°дәҶдёҡеҶ…зҡ„е…іжіЁ гҖӮ иҖҢиҝҷжӯЈжҳҜжҲ‘们иҰҒзқҖйҮҚд»Ӣз»Қзҡ„йғЁеҲҶ гҖӮжӣҙйҖӮеҗҲAIи®Ўз®—зҡ„IPUиҠҜзүҮиҝ‘дёӨе№ҙ пјҢ AI иҠҜзүҮеҮәзҺ°дәҶеҗ„з§Қе“Ғзұ»зҡ„дә•е–· пјҢ е…¶дёӯз”ҡиҮіеҮәзҺ°дёҖдәӣе Әз§°з–ҜзӢӮзҡ„еҸҰзұ»дә§е“Ғ гҖӮжҜ”еҰӮдёҖ家еҗҢж ·еҲӣз«Ӣеӣӣе№ҙзҡ„AIиҠҜзүҮеҲӣдёҡе…¬еҸёCerebras Systemsе°ұеҸ‘еёғдәҶеҸІдёҠжңҖеӨ§зҡ„еҚҠеҜјдҪ“иҠҜзүҮWafer Scale EngineпјҲWSEпјү пјҢ еҸ·з§°вҖңжҷ¶еңҶзә§еҸ‘еҠЁжңәвҖқ пјҢ жӢҘжңү1.2дёҮдәҝдёӘжҷ¶дҪ“з®Ў пјҢ жҜ”иӢұдјҹиҫҫжңҖеӨ§зҡ„GPUиҰҒеӨ§еҮә56.7еҖҚ гҖӮ иҝҷеқ—иҠҜзүҮдё»иҰҒзһ„еҮҶзҡ„жҳҜи¶…зә§и®Ўз®—е’Ңе’ҢеӨ§еһӢдә‘и®Ўз®—дёӯеҝғеёӮеңә пјҢ е…¶еҲӣж–°д№ӢеӨ„еңЁдәҺдёҖдҪ“еҢ–зҡ„иҠҜзүҮи®ҫи®ЎеӨ§е№…жҸҗй«ҳдәҶеҶ…йғЁзҡ„ж•°жҚ®йҖҡдҝЎж•°жҚ® пјҢ дҪҶе…¶жһ¶жһ„д»Қ然зұ»дјјдәҺGPUзҡ„и®Ўз®—жһ¶жһ„ гҖӮиҖҢGraphcoreзҡ„ IPUдёҺGPUзҡ„жһ¶жһ„е·®ејӮйқһеёёеӨ§ пјҢ д»ЈиЎЁзҡ„жҳҜдёҖз§Қж–°зҡ„жҠҖжңҜжһ¶жһ„ пјҢ еҸҜд»ҘиҜҙжҳҜдё“й—Ёдёәи§ЈеҶіCPUе’ҢGPUеңЁAIи®Ўз®—дёӯйҡҫд»Ҙи§ЈеҶізҡ„й—®йўҳиҖҢи®ҫи®Ўзҡ„ гҖӮ
IPUдёәAIи®Ўз®—жҸҗдҫӣдәҶе…Ёж–°зҡ„жҠҖжңҜжһ¶жһ„ пјҢ еҗҢж—¶е°Ҷи®ӯз»ғе’ҢжҺЁзҗҶеҗҲдәҢдёәдёҖ пјҢ е…је…·еӨ„зҗҶдәҢиҖ…е·ҘдҪңзҡ„иғҪеҠӣ гҖӮжҲ‘们д»Ҙзӣ®еүҚе·Із»ҸйҮҸдә§зҡ„IPUзҡ„GC2еӨ„зҗҶеҷЁжқҘзңӢ пјҢ IPU GC2йҮҮз”ЁеҸ°з§Ҝз”өзҡ„16nmе·Ҙиүә пјҢ жӢҘжңү 236дәҝдёӘжҷ¶дҪ“з®Ў пјҢ еңЁ120з“Ұзҡ„еҠҹиҖ—дёӢжңү125TFlopsзҡ„ж··еҗҲзІҫеәҰ пјҢ еҸҰеӨ–жңү45TB/sеҶ…еӯҳзҡ„еёҰе®ҪгҖҒ8TB/sзүҮдёҠеӨҡеҜ№еӨҡдәӨжҚўжҖ»зәҝ пјҢ 2.5 TB/sзҡ„зүҮй—ҙIPU-Links гҖӮе…¶дёӯ пјҢ зүҮеҶ…жңү1216дёӘIPU-TilesзӢ¬з«ӢеӨ„зҗҶеҷЁж ёеҝғ пјҢ жҜҸдёӘTileдёӯжңүзӢ¬з«Ӣзҡ„IPUж ё пјҢ дҪңдёәи®Ўз®—д»ҘеҸҠIn-Processor-MemoryпјҲеӨ„зҗҶеҷЁеҶ…зҡ„еҶ…еӯҳпјү гҖӮ еҜ№ж•ҙдёӘGC2жқҘиҜҙе…ұжңү7296дёӘзәҝзЁӢпјҲжҜҸдёӘж ёеҝғжңҖеӨҡеҸҜд»Ҙи·‘6дёӘзәҝзЁӢпјү пјҢ иғҪеӨҹж”ҜжҢҒ7296дёӘзЁӢеәҸ并иЎҢиҝҗиЎҢ пјҢ еӨ„зҗҶеҷЁеҶ…зҡ„еҶ…еӯҳжҖ»е…ұеҸҜд»ҘиҫҫеҲ°300MB пјҢ е…¶и®ҫи®ЎжҖқи·Ҝе°ұжҳҜиҰҒжҠҠжүҖжңүжЁЎеһӢж”ҫеңЁзүҮеҶ…еӨ„зҗҶ гҖӮйҰ–е…Ҳ пјҢ IPUдҪңдёәдёҖдёӘж ҮеҮҶзҡ„зҘһз»ҸзҪ‘з»ңеӨ„зҗҶиҠҜзүҮ пјҢ еҸҜд»Ҙж”ҜжҢҒеӨҡз§ҚзҘһз»ҸзҪ‘з»ңжЁЎеһӢ пјҢ еӣ е…¶е…·еӨҮж•°д»ҘеҚғи®ЎеҲ°ж•°зҷҫдёҮи®Ўзҡ„йЎ¶зӮ№ж•°йҮҸ пјҢ иҝңиҝңи¶…иҝҮGPUзҡ„йЎ¶зӮ№и§„жЁЎ пјҢ еҸҜд»ҘиҝӣиЎҢжӣҙй«ҳжҪңеҠӣзҡ„并иЎҢи®Ўз®—е·ҘдҪң гҖӮ жӯӨеӨ– пјҢ IPUзҡ„йЎ¶зӮ№зҡ„зЁҖз–Ҹзү№жҖ§ пјҢ д»Өе…¶д№ҹеҸҜд»Ҙй«ҳж•ҲеӨ„зҗҶGPUдёҚж“…й•ҝзҡ„зЁҖз–Ҹзҡ„еҚ·з§Ҝи®Ўз®— гҖӮ е…¶ж¬Ў пјҢ IPU д№ҹж”ҜжҢҒдәҶжЁЎеһӢеҸӮж•°зҡ„еӨҚз”Ё пјҢ иҝҷдәӣеӨҚз”Ёзү№жҖ§еҸҜд»ҘиҺ·еҸ–ж•°жҚ®дёӯзҡ„з©әй—ҙжҲ–ж—¶й—ҙдёҚеҸҳжҖ§ пјҢ еҜ№дәҺи®ӯз»ғдёҺжҺЁзҗҶзҡ„жҖ§иғҪдјҡжңүжҳҺжҳҫеё®еҠ© гҖӮе…¶ж¬Ў пјҢ дёәи§ЈеҶіиҠҜзүҮеҶ…еӯҳзҡ„е®ҪеёҰйҷҗеҲ¶ пјҢ IPUйҮҮз”ЁдәҶеӨ§и§„模并иЎҢMIMDпјҲеӨҡжҢҮд»ӨжөҒеӨҡж•°жҚ®жөҒпјүдј—ж ёжһ¶жһ„ пјҢ еҗҢж—¶ пјҢ IPUжһ¶жһ„еҒҡдәҶеӨ§и§„жЁЎеҲҶеёғејҸзҡ„зүҮдёҠSRAM гҖӮ зүҮеҶ…300MBзҡ„SRAM пјҢ зӣёеҜ№дәҺGPUзҡ„GDDRгҖҒHBMжқҘиҜҙ пјҢ еҸҜд»ҘеҒҡеҲ°ж•°еҚҒеҖҚзҡ„жҖ§иғҪжҸҗеҚҮ пјҢ иҖҢдё”дёҺи®ҝй—®еӨ–еӯҳзӣёжҜ” пјҢ SRAMзҡ„зүҮеҶ…时延еҹәжң¬еҸҜд»ҘеҝҪз•ҘдёҚи®Ў гҖӮ第дёү пјҢ IPUйҮҮз”ЁдәҶй«ҳж•Ҳзҡ„еӨҡж ёйҖҡдҝЎжҠҖжңҜBSPпјҲBulk Synchronous Parallelпјү гҖӮ IPUжҳҜзӣ®еүҚдё–з•ҢдёҠ第дёҖж¬ҫйҮҮз”ЁBSPйҖҡдҝЎзҡ„еӨ„зҗҶеҷЁ пјҢ ж”ҜжҢҒеҶ…йғЁ1216дёӘж ёеҝғд№Ӣй—ҙзҡ„йҖҡдҝЎд»ҘеҸҠи·ЁдёҚеҗҢзҡ„IPUд№Ӣй—ҙзҡ„йҖҡдҝЎ гҖӮ йҖҡиҝҮ硬件ж”ҜжҢҒBSPеҚҸи®® пјҢ 并йҖҡиҝҮBSPеҚҸи®®жҠҠж•ҙдёӘи®Ўз®—йҖ»иҫ‘еҲҶжҲҗдәҶи®Ўз®—гҖҒеҗҢжӯҘгҖҒдәӨжҚў пјҢ иғҪжһҒеӨ§ж–№дҫҝе·ҘзЁӢеёҲ们зҡ„ејҖеҸ‘е·ҘдҪң гҖӮ


жҺЁиҚҗйҳ…иҜ»


![[ж•°з Ғе°ҸзҺӢ]ProжңүзӮ№еғҸпјҢиҝҳжҳҜеҸҢжү“еӯ”жӣІйқўеұҸпјҒиҚЈиҖҖ30 Proзңҹжңәжӣқе…үпјҢи·ҹеҚҺдёәP40](https://imgcdn.toutiaoyule.com/20200328/20200328061128829913a_t.jpeg)















- жҫҺж№ғж–°й—»|иў«жҢҮејәеҘёеҘіз”ҹзҡ„еҚҺеҚ—зҗҶе·Ҙж•ҷжҺҲеӣһеә”з§°е°ҶеҒҡжҫ„жё…пјҢиӯҰж–№е’ҢеҰҮиҒ”д»Ӣе…Ҙ
- е№ёзҰҸжҳҜдәәз”ҹзҡ„жңҖй«ҳзӣ®ж Ү
- иҠҜзүҮдёҚдёҠеҺ»ең°зҗғзҗғзұҚйҡҫдҝқ
- еҰӮжқҫпјҡиҠҜзүҮеӨ§жҲҳпјҢ究з«ҹжү“зҡ„жҳҜд»Җд№Ҳпјҹ
- е№ҝиҘҝйҖҡ|жҒӢзҲұдёҖжңҲпјҢеҘүеӯҗжҲҗе©ҡеҸҲзҰ»е©ҡеҗҺпјҢе№ҝиҘҝдёҖз”·еӯҗжүҚеҸ‘зҺ°дёӨеҘіе„ҝдёҚжҳҜдәІз”ҹзҡ„......
- й«ҳе…үпјҒеҚ—дә¬еӨ§еӯҰж”»е…Ӣж–°зҡ„е…үеҲ»жҠҖжңҜжңүжңӣи§ЈеҶіжҲ‘еӣҪиҠҜзүҮ
- йҹ©еү§йӣҶеҗҲеӨ„|дәәз”ҹзҡ„жңҖдҪіжёЎиҝҮж–№ејҸпјҢеҖјеҫ—дҝқи—Ҹ
- жүӢжңә|дёҖйў—д»·еҖј2900е…ғпјҒ5nmиҠҜзүҮжҲҗжң¬жӣқе…үпјҢйЎ¶й…ҚiPhone12иҙөеҲ°д№°дёҚиө·
- зҘһеү§и§ЈиҜҙ|зҸӯдё»д»»еқҰиЁҖпјҡе·®з”ҹдёҺе°–еӯҗз”ҹзҡ„е·®и·қпјҢдёҚеңЁдәҺжҷәе•ҶпјҢиҖҢеңЁдәҺиҝҷ3дёӘз»ҶиҠӮ
- е№ҝдёңжҸҙй„ӮеҢ»з”ҹйҮҚиҝ”жӯҰжұүпјҢе®ҢжҲҗдёҺж–№иҲұиҖғз”ҹзҡ„зәҰе®ҡ