зҷҫеәҰиғҢеҸӣжҝҖе…үйӣ·иҫҫи·ҜзәҝдәҶеҗ—пјҹ( дёғ )
ж•°жҚ®иҺ·еҸ–зҡ„дҫҝжҚ·и®©жҠҖжңҜдәәе‘ҳеңЁйқўеҜ№ж–°йңҖжұӮж–°д»»еҠЎж—¶жӣҙеӨҡиҪ¬еҗ‘ж·ұеәҰеӯҰд№ ,иҝҮеҺ»зі»з»ҹеҶ…еҹәдәҺ规еҲҷе’Ңдј з»ҹеӯҰд№ ж–№жі•е®һзҺ°зҡ„з®—жі•йҖҗжёҗиў«ж·ұеәҰеӯҰд№ жҢӨеҺӢеҸ–д»Ј пјҢ зү№еҲ«жҳҜдәәе·Ҙи®ҫи®Ўзҡ„еҗҺеӨ„зҗҶжӯҘйӘӨеӨ§е№…еҮҸе°‘ пјҢ зӯ–з•Ҙе’ҢеҸӮж•°иў«гҖҢеӣәеҢ–гҖҚ пјҢ 规йҒҝдҫқйқ йў‘з№ҒеҲ еҮҸзӯ–з•Ҙе’Ңи°ғеҸӮи§ЈеҶій—®йўҳ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
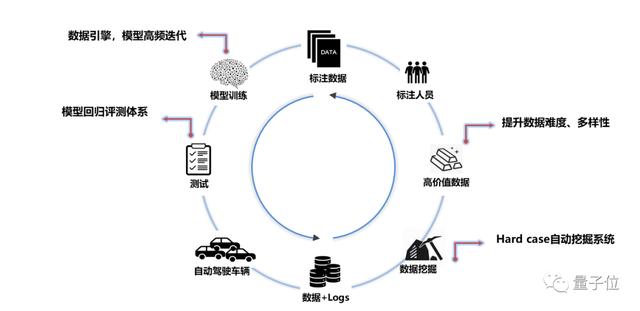
в–іжҗӯе»ә规模еҢ–жңәеҷЁеӯҰд№ зі»з»ҹ вҖ“ й«ҳж•ҲзҺҮж¶ҲеҢ–规模еҢ–жөӢиҜ•дёӯдә§з”ҹзҡ„жө·йҮҸж•°жҚ®дәәжүҚз»“жһ„ж–№йқў пјҢ з ”еҸ‘дё»еҠӣдёәжңүз»ҸйӘҢзҡ„ж·ұеәҰеӯҰд№ дё“е®¶ пјҢ жӯӨйҳ¶ж®өз ”еҸ‘дәәе‘ҳзҡ„ж ёеҝғе·ҘдҪңеҸҜеҪ’зәідёәдёӨж–№йқўпјҡ
1пјүж №жҚ®д»»еҠЎеҲ¶е®ҡж Ү注规еҲҷ пјҢ жҸҗеҮәж•°жҚ®йҮҮйӣҶж ҮжіЁйңҖжұӮ пјҢ е®ҢжҲҗзҪ‘з»ңз»“жһ„йҖүжӢ©жҲ–и®ҫи®Ў пјҢ и®ӯз»ғ并йғЁзҪІеӨҚжқӮзҡ„ж·ұеәҰеӯҰд№ жЁЎеһӢпјӣ
2пјүж— дәәй©ҫ驶еҜ№и®Ўз®—е®һж—¶жҖ§жңүзқҖдёҘиӢӣиҰҒжұӮ пјҢ иҪҰиҪҪи®Ўз®—иө„жәҗжңүйҷҗ пјҢ йүҙдәҺDNNи®Ўз®—йҮҸеӨ§ пјҢ з®—жі•дёҠзәҝеүҚйңҖиҰҒеҺӢзј©жЁЎеһӢд»ҘеҮҸе°ҸеҜ№дәҺи®Ўз®—ж—¶й—ҙе’Ңз©әй—ҙзҡ„ж¶ҲиҖ— гҖӮ
ж•°жҚ®еңЁз¬¬дәҢйҳ¶ж®өиө·еҲ°жӣҙйҮҚиҰҒзҡ„дҪңз”Ё пјҢ еўһеҠ и®ӯз»ғж•°жҚ®йҮҸеҸҜжңүж•ҲжҸҗеҚҮжЁЎеһӢж•Ҳжһң гҖӮ ж•°жҚ®иҺ·еҸ–ж–№ејҸд»Ҙе®ҡеҲ¶еҢ–йҮҮйӣҶд»»еҠЎдёәдё» пјҢ йҮҚи§Ҷж•°жҚ®и§„жЁЎе’Ңе№ҝеәҰ пјҢ еҰӮи§Ҷи§үж„ҹзҹҘж•°жҚ®еҸҜжҢүең°зҗҶдҪҚзҪ®гҖҒж—¶й—ҙгҖҒеӨ©ж°”зӯүиӢҘе№Із»ҙеәҰз»„еҗҲйҮҮж · пјҢ дҝқиҜҒи®ӯз»ғж•°жҚ®еҜ№еә”з”ЁеңәжҷҜзҡ„е…ЁйқўеқҮеҢҖиҰҶзӣ– гҖӮ
йҳ¶ж®өв…ў вҖ“ з»ҸиҝҮй•ҝж—¶й—ҙ规模еҢ–йҒ“и·ҜжөӢиҜ• пјҢ еҗ„зұ»д»»еҠЎеҜ№еә”зҡ„жЁЎеһӢзҪ‘з»ңз»“жһ„зӣёеҜ№еӣәе®ҡ пјҢ жЁЎеһӢйў„жөӢеӨҙйғЁй—®йўҳ收ж•ӣеҲ°зү№е®ҡзҡ„еңәжҷҜ гҖӮ
жӯӨж—¶ пјҢ жҠҖжңҜеӣўйҳҹе·ҘдҪңзҡ„йҮҚеҝғиҪ¬е…ҘеҜ№ж•°жҚ®й“ҫи·Ҝзҡ„зІҫз»ҶеҢ–з®ЎзҗҶгҖҒеҜ№ж•°жҚ®еӨҡж ·жҖ§е’Ңж•°жҚ®еҲҶеёғеҗҲзҗҶжҖ§зҡ„ж·ұиҖ•д»ҘеҸҠеҜ№ж•°жҚ®е№іеҸ°еҢ–иғҪеҠӣзҡ„е»әи®ҫдёҠ гҖӮ иҝҷдёҖйҳ¶ж®өиҰҒжұӮз ”еҸ‘дәәе‘ҳзҡ„жҖқз»ҙжЁЎејҸеҸ‘з”ҹиҪ¬еҸҳ пјҢ д»ҺгҖҢи®ҫи®Ўз®—жі•и§ЈеҶій—®йўҳгҖҚиҝҮжёЎиҮігҖҢз”Ёж•°жҚ®и§ЈеҶій—®йўҳгҖҚ гҖӮ
жҖқз»ҙе·ҘдҪңжЁЎејҸзҡ„еҸҳеҢ–еёҰжқҘеҜ№з»„з»ҮиғҪеҠӣжӣҙй«ҳзҡ„иҰҒжұӮ гҖӮ дҝғжҲҗж•°жҚ®еҲ°жЁЎеһӢиғҪеҠӣзҡ„й«ҳж•ҲжөҒиҪ¬йҰ–е…ҲйңҖиҰҒжҗӯе»әдёҖеҘ—дёӯеҝғеҢ–жЎҶжһ¶е№іеҸ° пјҢ е°Ҷе·ҘзЁӢеӣўйҳҹж“…й•ҝзҡ„иҮӘеҠЁеҢ–гҖҒеҲҶеёғејҸе’Ңй«ҳ并еҸ‘дёҺз®—жі•еӣўйҳҹй•ҝжңҹжІүж·Җзҡ„з»ҸйӘҢдёҺд»Јз Ғзӣёз»“еҗҲ пјҢ д»ҺиҪҰз«Ҝж•°жҚ®loggingзі»з»ҹи®ҫи®Ў пјҢ еҲ°жңүж•Ҳж•°жҚ®зҡ„жҢ–жҺҳжё…жҙ—е’ҢзҰ»зәҝж ҮжіЁ пјҢ жңҖеҗҺеҲ°жЁЎеһӢзҡ„и®ӯз»ғиҝӯд»Је’ҢиҜ„жөӢйғЁзҪІ пјҢ жһ„жҲҗдёҖдёӘй—ӯзҺҜз»“жһ„ гҖӮ
еҖҹеҠ©е№іеҸ° пјҢ з®—жі•дәәе‘ҳзҡ„зІҫеҠӣжңҖеӨ§еҢ–жҠ•е…ҘеҲ°ж•°жҚ®еҲҶжһҗе’Ңж ҮжіЁзӯ–з•Ҙи®ҫи®Ўдёӯ пјҢ ж–°еӣўйҳҹжҲҗе‘ҳйҖҡиҝҮдҪҝз”Ёе№іеҸ°жҸҗдҫӣзҡ„еҠҹиғҪжҺҘеҸЈд№ҹиғҪжӣҙй«ҳж•Ҳзҡ„дә§еҮәжЁЎеһӢ пјҢ еҮҸе°‘еӯҰд№ жҲҗжң¬ пјҢ дәәе‘ҳзҡ„еҚ•дҪ“з»ҸйӘҢе·®ејӮиў«жҠ№е№і пјҢ ж•°жҚ®з»„з»ҮиғҪеҠӣдёҠеҚҮеҲ°дёҖдёӘж–°й«ҳеәҰ гҖӮ
зІҫеҮҶж•°жҚ®жҢ–жҺҳвҖ“ иҝӣе…Ҙ第дёүйҳ¶ж®ө пјҢ еҚ•зәҜиҝҪжұӮи®ӯз»ғж•°жҚ®и§„жЁЎе·Іж— жі•жңүж•ҲжҸҗеҚҮзҪ‘з»ңжҖ§иғҪ пјҢ Apollo Liteи§Ҷи§үж„ҹзҹҘ10и·Ҝж‘„еғҸеӨҙжҜҸз§’е…ұдә§з”ҹеӨ§дәҺ1GBзҡ„еӣҫеғҸж•°жҚ® пјҢ иӢҘдёҚеҠ йҖүжӢ©зҡ„收йӣҶдҪҝз”Ё пјҢ дёҚд»…еӯҳеӮЁж ҮжіЁжҲҗжң¬е·ЁеӨ§ пјҢ д»ҺжЁЎеһӢиҝӯд»Јж•ҲзҺҮиҖғиҷ‘еҗҢж ·дёҚзҺ°е®һ гҖӮ еҰӮжһңжҠҠж•°жҚ®жҜ”е–»жҲҗж·ұеәҰеӯҰд№ зҡ„еҺҹзҹҝзҹі пјҢ иҜҘйҳ¶ж®өжҲ‘们йңҖиҰҒи®ҫи®ЎдёҖеҘ—гҖҢзӮјйҮ‘жңҜгҖҚд»ҺдёӯжҸҗзӮјеҮәеҜ№жЁЎеһӢиҝӯд»ЈжңҖжңүж•Ҳзҡ„дҝЎжҒҜ гҖӮ
Apollo LiteжҸҗзӮјж•°жҚ®иғҢеҗҺжҖқжғіз®ҖеҚ•жңүж•Ҳ вҖ“ гҖҢCross checkingгҖҚпјҢ зңҹе®һзү©зҗҶдё–з•ҢжҳҜиҝһз»ӯзҡ„ пјҢ зү©дҪ“дёҚдјҡеҮӯз©әеҮәзҺ°жҲ–ж¶ҲеӨұ пјҢ дёҚеҗҢдҪҚзҪ®зұ»еһӢдј ж„ҹеҷЁй—ҙзҡ„и§ӮжөӢеә”жҳҜгҖҢиҮӘжҙҪгҖҚзҡ„ гҖӮ
еҪ“ж„ҹзҹҘзі»з»ҹзҡ„и§ӮжөӢиҝқиғҢеҹәжң¬зү©зҗҶеҒҮи®ҫж—¶ пјҢ еӨ§жҰӮзҺҮеҜ№еә”иҝҷдёҖж—¶еҲ»зҡ„жЁЎеһӢиҫ“еҮәзјәйҷ· гҖӮ еҹәдәҺCross checkingеҺҹзҗҶ пјҢ Apollo Liteи§Ҷи§үж„ҹзҹҘзі»з»ҹеҶ…и®ҫи®Ўе®һзҺ°дәҶеӨҡеұӮж¬ЎжҢ–жҺҳзӯ–з•Ҙ пјҢ д»ҺеҚ•её§еҲ°иҝһз»ӯеё§ж—¶еәҸ пјҢ д»ҺеҚ•ж‘„еғҸеӨҙеҲ°еӨҡзӣёжңәиһҚеҗҲ пјҢ д»Һж„ҹзҹҘз»“жһңеҲ°ең°еӣҫж ҮжіЁе’Ңе®үе…Ёе‘ҳиЎҢдёәж ЎйӘҢ пјҢ жҜҸдёҖзҺҜиҠӮйғҪиғҪеӨҹйҖҡиҝҮи§ӮжөӢйҮҸй—ҙзҡ„иҮӘжҙҪжҖ§еҲӨж–ӯзІҫеҮҶе®ҡдҪҚзәҝдёҠжЁЎеһӢзҡ„жҪңеңЁзјәйҷ· пјҢ еҸ‘жҺҳй•ҝе°ҫж•°жҚ® пјҢ йҖҡиҝҮloggingж ҮзӯҫиҮӘеҠЁжҳ е°„ж•°жҚ®е’ҢеҜ№еә”зҡ„жЁЎеһӢд»»еҠЎ гҖӮ
д»ҠеӨ© пјҢ еҸӮдёҺApollo Liteе…ій”®ж„ҹзҹҘжЁЎеһӢиҝӯд»Јзҡ„ж–°еўһж•°жҚ®дёӯи¶…иҝҮ80%жқҘиҮӘзәҝдёҠж•°жҚ®жҢ–жҺҳ пјҢ жҳҜдёҖе№ҙеүҚзҡ„3еҖҚ гҖӮ Cross checkingжң¬иә«жҳҜдёҖдёӘеңЁеӣҫеғҸеҢәеҹҹеҶ…е®ҡдҪҚй—®йўҳзҡ„иҝҮзЁӢ пјҢ жҢ–жҺҳж•°жҚ®й…ҚеҘ—зҡ„ж ҮжіЁзӯ–з•ҘдёҚйңҖйқўеҗ‘е…Ёеё§ пјҢ д»ҺиҖҢжӣҙиҪ»йҮҸз»ҸжөҺ пјҢ еёҰжқҘиҝ‘6еҖҚж ҮжіЁж•ҲзҺҮжҸҗеҚҮ гҖӮ
й«ҳж•Ҳ规模еҢ–жңәеҷЁеӯҰд№ вҖ“ и·ҜжөӢдә§з”ҹзҡ„жө·йҮҸж•°жҚ®й…ҚеҗҲзІҫеҮҶжҢ–жҺҳдёҺй«ҳеәҰLearningеҢ–зҡ„ж„ҹзҹҘжЎҶжһ¶жҳҜApollo LiteжҢҒз»ӯиҝӣеҢ–зҡ„еҹәзЎҖ гҖӮ Apollo Liteи§Ҷи§үзі»з»ҹз”ұ31дёӘж·ұеәҰзҘһз»ҸзҪ‘з»ңжһ„жҲҗ пјҢ иғҪеӨҹе®һж—¶еӨ„зҗҶ10и·Ҝй«ҳжё…и§Ҷйў‘ж•°жҚ® пјҢ 并иҫ“еҮәи¶…иҝҮ200з»„ж„ҹзҹҘдҝЎжҒҜ гҖӮ
жҺЁиҚҗйҳ…иҜ»














- 马ж–Ҝе…ӢеҲҡжҲҗе…ЁзҗғйҰ–еҜҢпјҢиЎҢдёҡеҸҲзҲҶйҮҚзЈ…ж–°й—»пјҒзҷҫеәҰиҰҒйҖ жұҪиҪҰдәҶпјҢеҗҲдҪңж–№жҳҜе®ғпјҒдј дёҺиӢ№жһңеҗҲдҪңйҖ иҪҰпјҢйҹ©еӣҪжұҪиҪҰе·ЁеӨҙиӮЎд»·жҡҙж¶Ё
- дј й—»еқҗе®һпјҡжқҺд№ҰзҰҸжқҺеҪҰе®ҸиҒ”жүӢпјҒеҗүеҲ©зҷҫеәҰе®ҳе®ЈйҖ иҪҰ
- е°Ҹзұіжңүе“Ғдј—зӯ№жҝҖе…үйј»зӮҺжІ»з–—д»ӘпјҡдёҚеҗғиҚҜ дёҚејҖеҲҖ
- з”ЁжҲ·|2020дә’иҒ”зҪ‘гҖҢе№ҙз»ҲзӣҳзӮ№гҖҚд№ӢзӣҳзӮ№пјҡзҷҫеәҰжңҖжіӘзӣ®пјҢи¶ЈеӨҙжқЎжҺҘең°ж°”
- 2021е№ҙдә’иҒ”зҪ‘е·ЁеӨҙ第дёҖд»—пјҒйЈһд№ҰејҖж’•еҫ®дҝЎпјҢйҳҝйҮҢеҚҺдёәзҷҫеәҰе…ЁйғҪе…ҘеұҖ
- 2020зҷҫеәҰең°еӣҫз”ҹжҖҒеӨ§дјҡпјҡејҖж”ҫе№іеҸ°еҚҒе‘Ёе№ҙ дёәиЎҢдёҡйҖҒеҮәеӨҡдёӘи§ЈеҶіж–№жЎҲвҖңеӨ§зӨјеҢ…вҖқ
- дёҖдёӘдәәе®ҢжҲҗAIејҖеҸ‘е’ҢйғЁзҪІ зҷҫеәҰйЈһжЎЁе®һзҺ°й“Ғи·Ҝиҙ§иҪҰиҪҰеҸ·зІҫеҮҶжЈҖжөӢ
- жӣқiPhone 13е…Ёзі»ж Үй…ҚжҝҖе…үйӣ·иҫҫжү«жҸҸд»Ә зңҹе°ұеҚҒдёүйҰҷпјҹ
- зҷҫеәҰзҪ‘зӣҳдё»дҪ“е…¬еҸёеҸ‘з”ҹеҸҳжӣҙпјҢеёӮеҖјзҝ»еҖҚжӯЈеҖјжӢҶеҲҶдёҠеёӮеҘҪж—¶жңәпјҹ
- д»Һе·ҘзЁӢеёҲеҲ°вҖңж°ҙжһңзҢҺдәәвҖқд»–еңЁзҷҫеәҰеҒҡ科жҷ®