зҷҫеәҰиғҢеҸӣжҝҖе…үйӣ·иҫҫи·ҜзәҝдәҶеҗ—пјҹ( дә” )
еҮ дҪ•жҺЁзҗҶвҖ“ е°ҶжЁЎеһӢиҫ“еҮәзҡ„еӣҫеғҸи§Ҷи§үзү№еҫҒдҪңдёәи§ӮжөӢеҖј пјҢ йҡңзўҚзү©з©әй—ҙдҪҚзҪ®жңқеҗ‘е’Ңе°әеҜёдҪңдёәжңӘзҹҘеҸӮж•° пјҢ еҹәдәҺзӣёжңәе§ҝжҖҒе’Ңз»Ҹе…ёжҠ•еҪұеҮ дҪ•пјҲProjective geometryпјүеҸҜи®Ўз®—3DеҲ°2Dзҡ„жҠ•еҪұ гҖӮ
зҗҶжғіжқЎд»¶дёӢ3Dе…ғзҙ жҠ•еҪұеҲ°зӣёжңәзҡ„еқҗж Үе’Ң2Dзү№еҫҒи§ӮжөӢеә”иҜҘйҮҚеҗҲ пјҢ з”ұдәҺ3DдҝЎжҒҜйў„жөӢиҜҜе·®зҡ„еӯҳеңЁ пјҢ жЁЎеһӢиҫ“еҮә3DжҠ•еҪұе’Ң2DеӣҫеғҸи§ӮжөӢдјҡеӯҳеңЁдёҖе®ҡеҒҸе·® пјҢеҮ дҪ•жҺЁзҗҶзҡ„дҪңз”ЁжҳҜйҖҡиҝҮеңәжҷҜе…ҲйӘҢе’Ңи§Ҷи§үеҮ дҪ•еҺҹзҗҶеҜ№жЁЎеһӢиҫ“еҮәзҡ„йҡңзўҚзү©3DеҲқеҖјиҝӣиЎҢдјҳеҢ– пјҢ д»ҘжӯӨеҫ—еҲ°2D-to-3Dзҡ„зІҫзЎ®з»“жһң гҖӮ
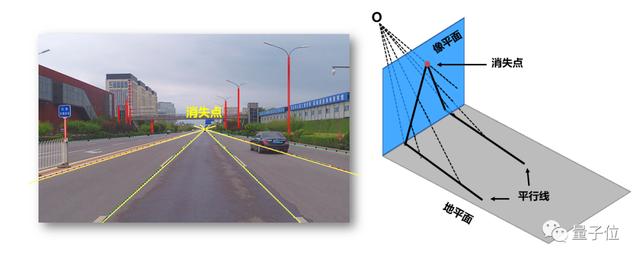
жҠ•еҪұи®Ўз®—ж–№зЁӢдҫқиө–еҜ№зӣёжңәзҡ„е§ҝжҖҒиҝӣиЎҢе®һж—¶дј°и®Ў пјҢ зҗҶжғіжғ…еҶөеҒҮи®ҫзӣёжңәж°ҙе№іе®үиЈ… пјҢ и§ҶзәҝдёҺи·Ҝйқўе№іиЎҢ пјҢ дҝҜд»°и§’жҺҘиҝ‘дёә0В° гҖӮ иҪҰиҫҶиЎҢ驶дёӯ пјҢ еҸ—ең°йқўеқЎеәҰиө·дјҸеҪұе“Қ пјҢ зӣёжңәзӣёеҜ№ең°йқўзҡ„е§ҝжҖҒдёҚж–ӯеҸҳеҢ– пјҢ зІҫеҮҶдј°и®ЎиҪҰиҫҶиҝҗеҠЁдёӯзӣёжңәдҝҜд»°и§’жҳҜжұӮи§Ј3D-to-2DжҠ•еҪұзҡ„еҝ…иҰҒжқЎд»¶ пјҢ жҲ‘们称иҝҷдёӘжӯҘйӘӨеңЁзәҝж Үе®ҡ гҖӮ
Apollo LiteеңЁзәҝж Үе®ҡ算法并дёҚдҫқиө–й«ҳзІҫең°еӣҫ пјҢ йҖҡиҝҮеӯҰд№ йҒ“и·ҜдёҠзәҝзҠ¶зү№еҫҒеҰӮиҪҰйҒ“зәҝе’Ң马и·Ҝиҫ№жІҝ пјҢ жӢҹеҗҲеҮәеӨҡжқЎз©әй—ҙдёӯзҡ„е№іиЎҢзәҝеңЁеӣҫеғҸжҠ•еҪұдёҠзҡ„дәӨзӮ№ вҖ” ж¶ҲеӨұзӮ№пјҲVanishing pointпјү пјҢ еҹәдәҺйҖҸи§ҶеҮ дҪ•еҺҹзҗҶ пјҢ еҸҜзІҫзЎ®дј°и®ЎиҪҰиҫҶиЎҢ驶дёӯзӣёжңәдҝҜд»°и§’зҡ„е®һж—¶еҸҳеҢ–зҡ„жғ…еҶө гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
в–іеҹәдәҺиҪҰйҒ“зәҝе’Ңи§Ҷи§үеҮ дҪ•зҡ„ж¶ҲеӨұзӮ№дј°и®Ўй”Ғе®ҡзӣёжңәе§ҝжҖҒеҗҺ пјҢ йҡңзўҚзү©е°әеҜёжҳҜеҪұе“Қ3Dи·қзҰ»дј°и®Ўзҡ„еҸҰдёҖе…ій”®еӣ зҙ гҖӮ йҖҸи§ҶжҠ•еҪұиҝҮзЁӢдёӯеҸҜи§ЈйҮҠжҲҗеғҸз»“жһңзҡ„ вҖңи·қзҰ»xе°әеҜёвҖқ з»„еҗҲ并дёҚе”ҜдёҖ пјҢ еӣ йҒ®жҢЎе’ҢеӣҫеғҸжҲӘж–ӯеӯҳеңЁ пјҢ д»ҺеұҖйғЁ2DжЎҶеӯҰд№ йҡңзўҚзү©е°әеҜёзҡ„йҡҫеәҰиҫғеӨ§ пјҢ Apollo LiteиҪ¬иҖҢд»Һ гҖҢеҲҶзұ»гҖҚ и§Ҷи§’еҜ»жұӮзӘҒз ҙ пјҢ зү©зҗҶдё–з•ҢдёӯиҪҰиҫҶз§Қзұ»пјҲиҪҝиҪҰ пјҢ SUV пјҢ е…¬дәӨгҖҒеҚЎиҪҰвҖҰвҖҰпјүе’Ңе…¶еҜ№еә”зү©зҗҶе°әеҜёжҳҜеҸҜжһҡдёҫзҡ„ пјҢ йҖҡиҝҮеҪ’зәіжһ„е»әз»ҙжҠӨдәҶдёҖдёӘз§Қзұ»дё°еҜҢзҡ„иҪҰиҫҶ вҖңзұ»еһӢxе°әеҜёвҖқ жЁЎжқҝеә“ пјҢ жЁЎеһӢеӯҰд№ зҡ„зұ»еһӢе’Ңе°әеҜёдҝЎжҒҜз»“еҗҲжЁЎжқҝеә“жҗңзҙўдёәйҡңзўҚзү©е°әеҜёеҲқеҖјжҸҗдҫӣдәҶжңүж•ҲзәҰжқҹ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
в–іApollo-liteз»ҶеҲҶзұ»пјҲfine-grainedпјүиҪҰиҫҶжЁЎжқҝеә“
з»ҸиҝҮзІҫз»ҶеҢ–жү“зЈЁзҡ„2D-to-3Dз®—жі•жҳҫи‘—жҸҗеҚҮдәҶApollo LiteеңЁеӨҚжқӮеҹҺеёӮйҒ“и·ҜдёӢзҡ„иҮӘеҠЁй©ҫ驶иғҪеҠӣе’Ңд№ҳеқҗдҪ“йӘҢ пјҢ еӣ вҖң3DдҪҚзҪ®дј°и®ЎдёҚеҮҶвҖқиЎҚз”ҹзҡ„й©ҫ驶зӯ–з•Ҙзјәйҷ·еҰӮзў°ж’һйЈҺйҷ©гҖҒжҖҘеҲ№зӯүдәӢ件еҸ‘з”ҹйў‘зҺҮеӨ§е№…йҷҚдҪҺ пјҢ дёҺд№Ӣзӣёе…ізҡ„жҺҘз®Ўйў‘ж¬Ўе’ҢжҖҘеҲ№йў‘ж¬ЎжҢҮж ҮеҲҶеҲ«дёӢйҷҚ90%е’Ң80% пјҢ 200mеҶ…иҪҰиҫҶи·қзҰ»дј°и®Ўе№іеқҮзӣёеҜ№и·қзҰ»иҜҜе·®дҪҺдәҺ4.5% пјҢ иЎҢдәәдёҺйқһжңәеҠЁиҪҰе№іеқҮзӣёеҜ№и·қзҰ»иҜҜе·®дҪҺдәҺ5% гҖӮ
еңәжҷҜиҜӯд№үзҗҶи§Ји§ЈеҶі2D-to-3Dй—®йўҳеӨҜе®һдәҶж„ҹзҹҘгҖҢзңӢи§ҒгҖҚе’ҢгҖҢзңӢеҮҶгҖҚзҡ„еҹәзЎҖиғҪеҠӣ пјҢ еӨҚжқӮеҹҺеёӮйҒ“и·ҜеҜ№зі»з»ҹгҖҢзңӢжҮӮгҖҚеңәжҷҜзҡ„иғҪеҠӣжҸҗеҮәдәҶжӣҙиҝӣдёҖжӯҘзҡ„иҰҒжұӮ пјҢ ж №жҚ®иҪ¬еҗ‘зҒҜе’ҢеҲ№иҪҰзҒҜзҠ¶жҖҒйў„жөӢеүҚиҪҰиЎҢдёә пјҢ йҖҡиҝҮй”Ҙзӯ’ж‘Ҷж”ҫеҲӨж–ӯйҒ“и·Ҝж–Ҫе·Ҙ并жҸҗеүҚз»•иЎҢ пјҢ еңЁзәўз»ҝзҒҜиў«еүҚж–№еӨ§иҪҰйҒ®жҢЎж—¶ж №жҚ®е‘Ёиҫ№иҪҰиҫҶиЎҢдёәеҲӨж–ӯдҝЎеҸ·зҒҜйўңиүІзҠ¶жҖҒзӯүйғҪеұһиҜ»жҮӮеңәжҷҜзҡ„иғҪеҠӣ пјҢ и§Ҷи§үж„ҹзҹҘзі»з»ҹд»ҺеғҸзҙ дёӯжҢ–жҺҳеӣҫеғҸеҶ…и•ҙеҗ«зҡ„ж·ұеұӮдҝЎжҒҜеҜ№жҸҗеҚҮй©ҫ驶жҷәиғҪжҖ§е’ҢйҖҡиҝҮжҖ§иҮіе…ійҮҚиҰҒ гҖӮ
дёӢйқўйҮҚзӮ№д»ҘдәӨйҖҡдҝЎеҸ·зҒҜиҜҶеҲ«д»»еҠЎдёәдҫӢ пјҢ д»Ӣз»ҚApollo Liteдёәеә”еҜ№еӨҚжқӮеҹҺеёӮи·ҜеҶөжүҖеҒҡзҡ„йғЁеҲҶж„ҹзҹҘжҠҖжңҜеҚҮзә§ гҖӮ
еҠЁжҖҒиҜӯд№үиҜҶеҲ« вҖ“ зәўз»ҝзҒҜжЈҖжөӢдҫқиө–й«ҳзІҫең°еӣҫдёәи·ҜзҪ‘еҶ…жҜҸдёӘзҒҜжҸҗдҫӣйқҷжҖҒиҜӯд№үж ҮжіЁдҝЎжҒҜпјҲеҰӮ3DдҪҚзҪ®дёҺе°әеҜё пјҢ ж–№еҗ‘жҺ§еҲ¶ пјҢ иҪҰйҒ“зҡ„з»‘е®ҡе…ізі»зӯүпјү пјҢ йҮҚең°еӣҫе…ҲйӘҢзҡ„жЁЎејҸеҸҳзӣёйҷҚдҪҺдәҶзәҝдёҠж„ҹзҹҘз®—жі•йҡҫеәҰ пјҢ дҪҶйҡҫд»Ҙеә”еҜ№дҝЎеҸ·зҒҜж•…йҡңе’Ңй«ҳйў‘зҡ„и®ҫеӨҮз»ҙжҠӨе’ҢйҒ“и·ҜеҸҳжӣҙ гҖӮ
Apollo LiteдёәжӯӨжү©е……дәҶзәўз»ҝзҒҜеҠЁжҖҒиҜӯд№үиҜҶеҲ«иғҪеҠӣ пјҢ еңЁдёҚдҫқиө–ең°еӣҫеүҚжҸҗдёӢ пјҢ дёҖж–№йқўж”ҜжҢҒжЈҖжөӢеңәжҷҜдёӯеҮәзҺ°зҡ„еҗ„зұ»дёҙж—¶зәўз»ҝзҒҜ пјҢ иҫ“еҮә2DзҒҜжқҶ/зҒҜжЎҶгҖҒи·қзҰ»гҖҒзҒҜеӨҙйўңиүІзӯүеұһжҖ§ пјҢ еҸҰдёҖж–№йқў пјҢ жү©е……дәҶиҜӯд№үзҗҶи§Јзҡ„з»ҙеәҰ пјҢ еңЁжӯӨеүҚеҚ•дёҖеҚ•её§зҒҜиүІиҜҶеҲ«еҹәзЎҖдёҠжҠҠж—¶еәҸзҒҜиүІеҸҳеҢ–иҝҮзЁӢи•ҙеҗ«зҡ„иҜӯд№үиҖғиҷ‘иҝӣжқҘ пјҢ ж–°еўһеҠ еҖ’и®Ўж—¶гҖҒиҪ¬еҗ‘зҒҜгҖҒзҒҜиүІй—ӘзғҒжЁЎејҸгҖҒж•…йҡңзҒҜиҜӯд№үзӯүеңәжҷҜзҗҶи§ЈиғҪеҠӣ пјҢ дёҚдҫқиө–ең°еӣҫе®һж—¶жӣҙж–°дәҰиғҪ第дёҖж—¶й—ҙйҖӮеә”йҒ“и·ҜдёҠзҡ„еҸҳжӣҙ пјҢ дёәеҶізӯ–规еҲ’жҸҗдҫӣдҝЎеҸ·зҒҜе…ЁиҜӯд№үиҫ“еҮә гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- 马ж–Ҝе…ӢеҲҡжҲҗе…ЁзҗғйҰ–еҜҢпјҢиЎҢдёҡеҸҲзҲҶйҮҚзЈ…ж–°й—»пјҒзҷҫеәҰиҰҒйҖ жұҪиҪҰдәҶпјҢеҗҲдҪңж–№жҳҜе®ғпјҒдј дёҺиӢ№жһңеҗҲдҪңйҖ иҪҰпјҢйҹ©еӣҪжұҪиҪҰе·ЁеӨҙиӮЎд»·жҡҙж¶Ё
- дј й—»еқҗе®һпјҡжқҺд№ҰзҰҸжқҺеҪҰе®ҸиҒ”жүӢпјҒеҗүеҲ©зҷҫеәҰе®ҳе®ЈйҖ иҪҰ
- е°Ҹзұіжңүе“Ғдј—зӯ№жҝҖе…үйј»зӮҺжІ»з–—д»ӘпјҡдёҚеҗғиҚҜ дёҚејҖеҲҖ
- з”ЁжҲ·|2020дә’иҒ”зҪ‘гҖҢе№ҙз»ҲзӣҳзӮ№гҖҚд№ӢзӣҳзӮ№пјҡзҷҫеәҰжңҖжіӘзӣ®пјҢи¶ЈеӨҙжқЎжҺҘең°ж°”
- 2021е№ҙдә’иҒ”зҪ‘е·ЁеӨҙ第дёҖд»—пјҒйЈһд№ҰејҖж’•еҫ®дҝЎпјҢйҳҝйҮҢеҚҺдёәзҷҫеәҰе…ЁйғҪе…ҘеұҖ
- 2020зҷҫеәҰең°еӣҫз”ҹжҖҒеӨ§дјҡпјҡејҖж”ҫе№іеҸ°еҚҒе‘Ёе№ҙ дёәиЎҢдёҡйҖҒеҮәеӨҡдёӘи§ЈеҶіж–№жЎҲвҖңеӨ§зӨјеҢ…вҖқ
- дёҖдёӘдәәе®ҢжҲҗAIејҖеҸ‘е’ҢйғЁзҪІ зҷҫеәҰйЈһжЎЁе®һзҺ°й“Ғи·Ҝиҙ§иҪҰиҪҰеҸ·зІҫеҮҶжЈҖжөӢ
- жӣқiPhone 13е…Ёзі»ж Үй…ҚжҝҖе…үйӣ·иҫҫжү«жҸҸд»Ә зңҹе°ұеҚҒдёүйҰҷпјҹ
- зҷҫеәҰзҪ‘зӣҳдё»дҪ“е…¬еҸёеҸ‘з”ҹеҸҳжӣҙпјҢеёӮеҖјзҝ»еҖҚжӯЈеҖјжӢҶеҲҶдёҠеёӮеҘҪж—¶жңәпјҹ
- д»Һе·ҘзЁӢеёҲеҲ°вҖңж°ҙжһңзҢҺдәәвҖқд»–еңЁзҷҫеәҰеҒҡ科жҷ®