зҷҫеәҰиғҢеҸӣжҝҖе…үйӣ·иҫҫи·ҜзәҝдәҶеҗ—пјҹ( еӣӣ )
дёҺжҝҖе…үйӣ·иҫҫдёҚеҗҢ пјҢ ж‘„еғҸеӨҙжҲҗеғҸжҳҜвҖңиў«еҠЁвҖқејҸзҡ„пјҲPassive sensingпјү пјҢ ж„ҹе…үе…ғ件仅жҺҘ收зү©дҪ“иЎЁйқўеҸҚе°„зҡ„зҺҜеўғе…ү пјҢ дёүз»ҙдё–з•Ңз»ҸжҠ•еҪұеҸҳжҚўпјҲProjective transformationпјүиў«вҖңеҺӢзј©вҖқеҲ°дәҢз»ҙзӣёе№ійқўдёҠ пјҢ жҲҗеғҸиҝҮзЁӢдёӯеңәжҷҜвҖңж·ұеәҰвҖқпјҲжҷҜж·ұпјүдҝЎжҒҜдёўеӨұдәҶ гҖӮ
еҪ“з®—жі•еҶҚиҜ•еӣҫд»ҺдәҢз»ҙеӣҫеғҸдёӯжҒўеӨҚзӣ®ж Үзү©дҪ“еҺҹжң¬еңЁдёүз»ҙз©әй—ҙдёӯжүҖеӨ„зҡ„дҪҚзҪ®ж—¶ пјҢ йқўеҜ№зҡ„жҳҜдёҖдёӘж¬ зәҰжқҹзҡ„вҖңйҖҶй—®йўҳвҖқпјҲill-posed inverse problemпјү пјҢ е…¶йҡҫеәҰеҸҜзӣҙи§ӮзҗҶи§Јдёәз”Ё2дёӘж–№зЁӢејҸжұӮи§Ј3дёӘжңӘзҹҘж•° гҖӮ
з”ұдёҖеј дәҢз»ҙеӣҫеғҸжҒўеӨҚеңәжҷҜдёӯзҡ„дёүз»ҙдҝЎжҒҜпјҲгҖҢ2D-to-3DгҖҚпјүжҳҜи®Ўз®—жңәи§Ҷи§үеӯҰ科иҜһз”ҹд№ӢеҲқе®ҡд№үзҡ„з»Ҹе…ёй—®йўҳд№ӢдёҖ пјҢ ж—¶иҮід»Ҡж—Ҙд»ҚжҳҜи§Ҷи§үз•Ңзғӯй—Ёз ”з©¶ж–№еҗ‘ пјҢ д№ҹжҳҜдҪҝз”Ёж‘„еғҸеӨҙд»ЈжӣҝжҝҖе…үйӣ·иҫҫдёәж— дәәй©ҫ驶жҸҗдҫӣж„ҹзҹҘз»“жһңжүҖйқўдёҙзҡ„ж ёеҝғжҠҖжңҜжҢ‘жҲҳ гҖӮ
иҝӣе…ҘжҠҖжңҜеҲҶдә«еүҚ пјҢ е…ҲзңӢдёҖж®өдёҖй•ңеҲ°еә•зҡ„ж—ҘеёёApollo LiteдәҰеә„и·ҜжөӢи§Ҷйў‘ гҖӮ и§Ҷйў‘дёӯжөӢиҜ•еҢәеҹҹеӨ„дәҺдәҰеә„дёӯеҝғз№ҒеҚҺи·Ҝж®ө пјҢ еҢ…еҗ«дёӨжқЎи·Ҝзәҝ пјҢ зҙҜи®ЎиҮӘеҠЁй©ҫ驶иЎҢ驶时й•ҝжҺҘиҝ‘60еҲҶй’ҹ пјҢ е…ЁзЁӢж— жҺҘз®Ў гҖӮ
д»Һи§Ҷйў‘дёӯеҸҜд»ҘзңӢеҮә пјҢ дё»иҪҰд»Ҙ40е…¬йҮҢ/е°Ҹж—¶е·ҰеҸізҡ„йҖҹеәҰиЎҢ驶 пјҢ е®Ҫйҳ”йҒ“и·ҜиЎҢ驶时йҖҹеәҰеҸҜжҸҗеҚҮиҮі55е…¬йҮҢ/е°Ҹж—¶д»ҘдёҠпјҲдәҰеә„йҒ“и·ҜйҷҗйҖҹдёә60е…¬йҮҢ/е°Ҹж—¶пјү гҖӮ иЎҢ驶иҝҮзЁӢдёӯ пјҢ дё»иҪҰдёҺе…¶д»–иҪҰиҫҶ пјҢ иЎҢдәә пјҢ иҮӘиЎҢиҪҰе’Ңз”өеҠЁиҪҰзӯүйҒ“и·ҜеҸӮдёҺиҖ…дәӨдә’йў‘з№Ғ пјҢ еңЁжҲҗеҠҹеӨ„зҗҶеҲҮиҪҰгҖҒеҸҳйҒ“гҖҒиҝҮи·ҜеҸЈгҖҒжҺүеӨҙгҖҒзӯүеҹҺеёӮйҒ“и·ҜеҹәзЎҖдәӨйҖҡеңәжҷҜд№ӢеӨ– пјҢ иҪҰиҫҶд№ҹеұ•зӨәдәҶеҮәиүІзҡ„йҖҡиЎҢиғҪеҠӣе’ҢдёҺйҒ“и·ҜеҸӮдёҺиҖ…зҡ„дәӨдә’иғҪеҠӣ пјҢ и§Ҷйў‘дёӯе‘ҲзҺ°дәҶе…¶еңЁи·ҜжЎ©ж‘Ҷж”ҫеҜҶйӣҶзҡ„зӢӯзӘ„и·Ҝж®өгҖҒж–Ҫе·ҘеҢәеҹҹд»ҘеҸҠеҸҢеҗ‘еҚ•иҪҰйҒ“дёҠзҡ„йҖҡиЎҢиғҪеҠӣ пјҢ иҪҰиҫҶиғҪеӨҹеҗҲзҗҶйҒҝи®©иҪҰжөҒдёӯжЁӘз©ҝйҒ“и·Ҝзҡ„иЎҢдәәе’ҢеңЁиҪҰжөҒдёӯз©ҝжўӯзҡ„ж‘©жүҳиҪҰе’Ңз”өеҠЁиҪҰ гҖӮ еҸҜи§ҶеҢ–жқҘиҮӘиҪҰз«Ҝе®һж—¶ж„ҹзҹҘз»“жһң пјҢ и§Ҷйў‘еҶ…е®№жңӘз»Ҹд»»дҪ•еүӘиҫ‘еҠ е·Ҙ пјҢ еҠӣжұӮе®ўи§Ӯзңҹе®һзҡ„е‘ҲзҺ°е®Ңж•ҙжөӢиҜ•иҝҮзЁӢ гҖӮ
03 Apollo Liteи§Ҷи§үж„ҹзҹҘжҠҖжңҜжҸӯз§ҳзҷҫеәҰеңЁиҝ‘дёҖе№ҙи§Ҷи§үж„ҹзҹҘж”»еқҡиҝҮзЁӢдёӯз§ҜзҙҜдәҶдё°еҜҢзҡ„е®һи·өз»ҸйӘҢ并жІүж·ҖдәҶжңүж•Ҳзҡ„ж–№жі•и®ә пјҢ жҖ»з»“дёӢжқҘ пјҢ дёүдёӘе…ій”®жҠҖжңҜеұӮйқўзҡ„ж·ұиҖ•зӘҒз ҙжҲҗе°ұдәҶApollo Liteй©ҫ驶иғҪеҠӣиҝ…йҖҹжҸҗеҚҮ гҖӮ
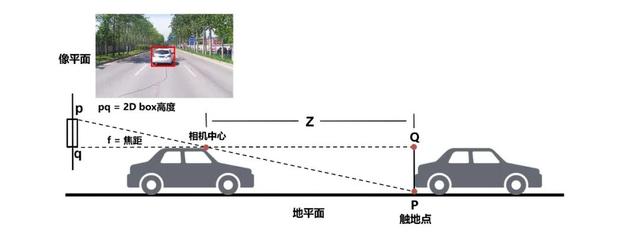
2D-to-3Dйҡҫйўҳиҝ‘е№ҙжқҘ пјҢ и§Ҷи§үзӣ®ж ҮжЈҖжөӢд»»еҠЎдјҙйҡҸж·ұеәҰеӯҰд№ жҠҖжңҜзҡ„иҝӣжӯҘеҸ–еҫ—дәҶзӘҒйЈһзҢӣиҝӣзҡ„еҸ‘еұ• гҖӮ д»ҠеӨ© пјҢ з»ҸеҜ№дәәе·Ҙж ҮжіЁж•°жҚ®иҝӣиЎҢзӣ‘зқЈеӯҰд№ пјҢ еңЁеӣҫеғҸдёҠе°Ҷзӣ®ж Үзү©дҪ“пјҲеҰӮиҪҰиҫҶгҖҒиЎҢдәәгҖҒиҮӘиЎҢиҪҰзӯүпјү2DжЎҶйҖүеҮәжқҘе·Із»ҸдёҚжҳҜи§Ҷи§үж„ҹзҹҘзҡ„еӨҙйғЁйҡҫйўҳ пјҢ еҚ•зәҜ2DжЎҶжЈҖжөӢж— жі•ж”ҜжҢҒ3Dз©әй—ҙдёӯзҡ„иҪҰиҫҶ规еҲ’жҺ§еҲ¶ пјҢ жү“йҖ дёҖеҘ—зәҜи§Ҷи§үж„ҹзҹҘзі»з»ҹ пјҢ и§ЈеҶі2D-to-3Dй—®йўҳйҰ–еҪ“е…¶еҶІ гҖӮ
дј з»ҹз®—жі•и®Ўз®—2DжЈҖжөӢжЎҶзҡ„жЎҶеә•дёӯеҝғеҗҺйҖҡиҝҮйҒ“и·Ҝе№ійқўеҒҮи®ҫе’ҢеҮ дҪ•жҺЁзҗҶзү©дҪ“ж·ұеәҰдҝЎжҒҜ пјҢ иҝҷзұ»ж–№жі•з®ҖеҚ•иҪ»йҮҸ пјҢ дҪҶеҜ№2DжЎҶжЈҖжөӢе®Ңж•ҙжҖ§е’ҢйҒ“и·Ҝзҡ„еқЎеәҰжӣІзҺҮзӯүжңүиҫғејәзҡ„дҫқиө–еҒҮи®ҫ пјҢ еҜ№йҒ®жҢЎе’ҢиҪҰиҫҶйў з°ёжҜ”иҫғж•Ҹж„ҹ пјҢ з®—жі•ж¬ зјәйІҒжЈ’жҖ§ пјҢ дёҚи¶ід»Ҙеә”еҜ№еӨҚжқӮеҹҺеёӮйҒ“и·ҜдёҠзҡ„3DжЈҖжөӢд»»еҠЎ гҖӮ Apollo Lite延з»ӯгҖҢжЁЎеһӢеӯҰд№ +еҮ дҪ•жҺЁзҗҶгҖҚжЎҶжһ¶еҗҢж—¶еҜ№ж–№жі•з»ҶиҠӮиҝӣиЎҢдәҶеӨ§йҮҸжү“зЈЁеҚҮзә§ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
в–ідј з»ҹеҹәдәҺең°е№ійқўеҒҮи®ҫе’Ңзӣёдјје…ізі»и®Ўз®—2D-to-3Dзҡ„ж–№жі•жЁЎеһӢеӯҰд№ вҖ“ ж•°жҚ®е’ҢеӯҰд№ еұӮйқў пјҢ еҲ©з”ЁжҝҖе…үйӣ·иҫҫзҡ„зӮ№дә‘ж•°жҚ®е°Ҷ2Dж ҮжіЁжЎҶе’Ң3DжЈҖжөӢжЎҶе…іиҒ” пјҢ еңЁж ҮжіЁйҳ¶ж®өдёәжҜҸдёӘ2DеҢ…еӣҙжЎҶиөӢдәҲдәҶзү©зҗҶдё–з•Ңдёӯзҡ„и·қзҰ»гҖҒе°әеҜёгҖҒжңқеҗ‘гҖҒйҒ®жҢЎзҠ¶жҖҒ/жҜ”дҫӢзӯүдҝЎжҒҜ гҖӮ
йҖҡиҝҮд»Һе®үиЈ…зӣёеҗҢж‘„еғҸеӨҙпјҲCamera configurationпјү并й…ҚеӨҮй«ҳзәҝж•°жҝҖе…үйӣ·иҫҫзҡ„зҷҫеәҰL4иҮӘеҠЁй©ҫ驶иҪҰйҳҹиҺ·еҸ–жө·йҮҸж—¶з©әеҜ№йҪҗзҡ„гҖҢеӣҫеғҸ+зӮ№дә‘гҖҚж•°жҚ® пјҢ и®ӯз»ғйҳ¶ж®өDNNпјҲDeep neural networksпјүзҪ‘з»ңжЁЎеһӢд»ҺеӣҫеғҸappearanceдҝЎжҒҜеҒҡйҡңзўҚзү©з«ҜеҲ°з«Ҝзҡ„дёүз»ҙеұһжҖ§йў„жөӢ пјҢ жЁЎеһӢз«Ҝе®ҢжҲҗд»Һд»…йў„жөӢ2Dз»“жһңеҲ°еӯҰд№ 2D+3DдҝЎжҒҜзҡ„еҚҮзә§ пјҢ е°Ҷдј з»ҹвҖңеҮ дҪ•жҺЁзҗҶвҖқеҗҺеӨ„зҗҶжЁЎеқ—зҡ„д»»еҠЎеӨ§зЁӢеәҰеҗ‘жЁЎеһӢз«ҜеүҚзҪ® пјҢ вҖңж·ұеәҰеӯҰд№ +ж•°жҚ®й©ұеҠЁвҖқдёәжҸҗеҚҮйў„жөӢж•ҲжһңжҸҗдҫӣдәҶдҫҝжҚ·жңүж•Ҳзҡ„и·Ҝеҫ„е’Ңжӣҙй«ҳзҡ„еӨ©иҠұжқҝ гҖӮ
еңЁж·»еҠ жЁЎеһӢз«Ҝ3Dйў„жөӢиғҪеҠӣеӨ– пјҢ дёәз»ҷеҗҺз»ӯеҮ дҪ•зәҰжқҹйҳ¶ж®өжҸҗдҫӣдё°еҜҢзҡ„еӣҫеғҸзәҝзҙў пјҢ й’ҲеҜ№дёҚеҗҢдҪҚзҪ®/жңқеҗ‘зӣёжңәзҡ„е®үиЈ…и§ӮжөӢзү№жҖ§ пјҢ жЁЎеһӢд»ҺеӯҰд№ йҡңзўҚзү©зҹ©еҪўеҢ…еӣҙжЎҶжӢ“еұ•еҲ°йў„жөӢжӣҙеӨҡз»ҙеәҰжӣҙз»ҶзІ’еәҰзҡ„зү№еҫҒ пјҢ еҰӮиҪҰиҪ®е’ҢиҪҰеә•жҺҘең°иҪ®е»“зәҝ гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- 马ж–Ҝе…ӢеҲҡжҲҗе…ЁзҗғйҰ–еҜҢпјҢиЎҢдёҡеҸҲзҲҶйҮҚзЈ…ж–°й—»пјҒзҷҫеәҰиҰҒйҖ жұҪиҪҰдәҶпјҢеҗҲдҪңж–№жҳҜе®ғпјҒдј дёҺиӢ№жһңеҗҲдҪңйҖ иҪҰпјҢйҹ©еӣҪжұҪиҪҰе·ЁеӨҙиӮЎд»·жҡҙж¶Ё
- дј й—»еқҗе®һпјҡжқҺд№ҰзҰҸжқҺеҪҰе®ҸиҒ”жүӢпјҒеҗүеҲ©зҷҫеәҰе®ҳе®ЈйҖ иҪҰ
- е°Ҹзұіжңүе“Ғдј—зӯ№жҝҖе…үйј»зӮҺжІ»з–—д»ӘпјҡдёҚеҗғиҚҜ дёҚејҖеҲҖ
- з”ЁжҲ·|2020дә’иҒ”зҪ‘гҖҢе№ҙз»ҲзӣҳзӮ№гҖҚд№ӢзӣҳзӮ№пјҡзҷҫеәҰжңҖжіӘзӣ®пјҢи¶ЈеӨҙжқЎжҺҘең°ж°”
- 2021е№ҙдә’иҒ”зҪ‘е·ЁеӨҙ第дёҖд»—пјҒйЈһд№ҰејҖж’•еҫ®дҝЎпјҢйҳҝйҮҢеҚҺдёәзҷҫеәҰе…ЁйғҪе…ҘеұҖ
- 2020зҷҫеәҰең°еӣҫз”ҹжҖҒеӨ§дјҡпјҡејҖж”ҫе№іеҸ°еҚҒе‘Ёе№ҙ дёәиЎҢдёҡйҖҒеҮәеӨҡдёӘи§ЈеҶіж–№жЎҲвҖңеӨ§зӨјеҢ…вҖқ
- дёҖдёӘдәәе®ҢжҲҗAIејҖеҸ‘е’ҢйғЁзҪІ зҷҫеәҰйЈһжЎЁе®һзҺ°й“Ғи·Ҝиҙ§иҪҰиҪҰеҸ·зІҫеҮҶжЈҖжөӢ
- жӣқiPhone 13е…Ёзі»ж Үй…ҚжҝҖе…үйӣ·иҫҫжү«жҸҸд»Ә зңҹе°ұеҚҒдёүйҰҷпјҹ
- зҷҫеәҰзҪ‘зӣҳдё»дҪ“е…¬еҸёеҸ‘з”ҹеҸҳжӣҙпјҢеёӮеҖјзҝ»еҖҚжӯЈеҖјжӢҶеҲҶдёҠеёӮеҘҪж—¶жңәпјҹ
- д»Һе·ҘзЁӢеёҲеҲ°вҖңж°ҙжһңзҢҺдәәвҖқд»–еңЁзҷҫеәҰеҒҡ科жҷ®