зҷҫеәҰиғҢеҸӣжҝҖе…үйӣ·иҫҫи·ҜзәҝдәҶеҗ—пјҹ( е…ӯ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
в–ізәўз»ҝзҒҜеҠЁжҖҒиҜӯд№үиҜҶеҲ«(移еҠЁзәўз»ҝзҒҜ пјҢ еӨҡиҜӯд№үзҒҜ пјҢ ж•…йҡңзҒҜзӯү)еҸҜйҖҡиЎҢжҖ§жҺЁзҗҶ вҖ“ иЎҢ驶еңЁеӨҚжқӮеҹҺеёӮйҒ“и·Ҝдёӯ пјҢ дәӨйҖҡдҝЎеҸ·зҒҜеңЁзӣёжңәдёӯе…ЁзЁӢеҸҜи§Ғйҡҫд»ҘиҺ·еҫ—дҝқиҜҒ пјҢ йҒ®жҢЎгҖҒйҖҶе…үгҖҒйӣЁйӣҫжЁЎзіҠзӯүжғ…еҶөдёӢиҰҒжұӮж„ҹзҹҘзі»з»ҹе…·еӨҮдәәзұ»еҸёжңәзҡ„жҺЁзҗҶйҖ»иҫ‘ пјҢ дёәжӯӨApollo Liteж„ҹзҹҘиЎҘе……дәҶдҝЎеҸ·зҒҜжҺЁзҗҶеҠҹиғҪ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
в–ізәўз»ҝзҒҜйҖҡиЎҢжҖ§жҺЁзҗҶеңәжҷҜ(еҠЁйқҷжҖҒйҒ®жҢЎ пјҢ йӣҫеӨ©/йӣЁеӨ©/еӨңжҷҡ/иғҢжҷҜе№Іжү°й—®йўҳзӯү)йҰ–е…Ҳ пјҢ еўһеҠ з®—жі•еҜ№иҮӘиә«ж„ҹзҹҘз»“жһңзҪ®дҝЎеәҰзҡ„зІҫеҮҶиҜ„дј°иғҪеҠӣ пјҢ еңЁи§ӮжөӢйҮҸдёҚе®Ңе…ЁжҲ–иҖ…ж‘„еғҸеӨҙжҲҗеғҸдёҚзҗҶжғіжғ…еҶөдёӢ пјҢ еҲҮжҚўеҲ°жҺЁзҗҶжЁЎејҸ гҖӮ иҜҘжЁЎејҸдёӢз®—жі•з»“еҗҲиҪҰиә«е‘Ёиҫ№йҡңзўҚзү©иҝҗеҠЁдҝЎжҒҜжҸҗеҸ–иҪҰжөҒиҪЁиҝ№ пјҢ й…ҚеҗҲ еҜ№и·ҜеҸЈе…¶е®ғй«ҳзҪ®дҝЎеҸҜи§ҒзҒҜзҡ„зҠ¶жҖҒе’ҢиҜӯд№үеҲҶжһҗ пјҢ йҖҡиҝҮиһҚеҗҲеӨҡи·ҜдҝЎжҒҜеӯҰд№ и·ҜеҸЈеҸҜйҖҡиЎҢжҖ§ пјҢ йў„жөӢзҒҜиүІ пјҢ жңүж•ҲдҝқиҜҒдәҶеңЁи§ӮжөӢж•°жҚ®дёҚе®Ңж•ҙжғ…еҶөдёӢдҝЎеҸ·зҒҜйўңиүІд»ҚиғҪиў«жӯЈзЎ®иҜҶеҲ« гҖӮ
еҫ—зӣҠдәҺд»ҘдёҠеңәжҷҜиҜӯд№үи§ЈиҜ»иғҪеҠӣзҡ„еҚҮзә§ пјҢ Apollo LiteеңЁеҹҺеёӮйҒ“и·Ҝзҡ„йҖҡиЎҢиғҪеҠӣиҺ·еҫ—иҝӣдёҖжӯҘжҸҗй«ҳ пјҢ еҚ•дҪҚжөӢиҜ•йҮҢзЁӢеҶ… пјҢ еӣ дҝЎеҸ·зҒҜиў«йҒ®жҢЎеҜјиҮҙзҡ„дё»иҪҰжҖҘеҲ№е’ҢдёҚеҗҲзҗҶеҒңж»һзӯүй—®йўҳеҮҸе°‘иҝ‘3еҖҚ пјҢ еӣ дҝЎеҸ·зҒҜж„ҹзҹҘй”ҷиҜҜйҖ жҲҗзҡ„и·ҜеҸЈйҖҡиҝҮеӨұиҙҘй—®йўҳеҮҸе°‘иҝ‘10еҖҚ гҖӮ
ж•°жҚ®й©ұеҠЁзҡ„иҝӯд»ЈжЁЎејҸж•°жҚ®й—ӯзҺҜиҮӘеҠЁеҢ–жҳҜиҝ‘е№ҙдёҡеҶ…й«ҳйў‘жҸҗеҸҠзҡ„жҰӮеҝө пјҢ вҖңж•°жҚ®й©ұеҠЁз®—жі•вҖқгҖҒвҖңиҮӘеҠЁеҢ–и§ЈеҶій—®йўҳвҖқгҖҒвҖңи·ЁйҮҸзә§йҷҚдҪҺL4жҲҗжң¬вҖқзӯүдј ж’ӯж•°жҚ®еҚіиғҪеҠӣзҡ„зҗҶеҝөжөҒдј з”ҡе№ҝ пјҢ иЎҢдёҡеҜ№ж•°жҚ®зҡ„йў„жңҹж°ҙж¶ЁиҲ№й«ҳ гҖӮ
жҳҜеҗҰжӢҘжңүдәҶжө·йҮҸж•°жҚ®е°ұзӯүеҗҢдәҺиғҪиҮӘеҠЁиҝҲиҝӣе®Ңе…Ёж— дәәй©ҫ驶пјҹдёҖдёӘйқ ж•°жҚ®й©ұеҠЁзҡ„зі»з»ҹеҰӮдҪ•жү“йҖ пјҹжҠӣејҖжҠҖжңҜзҗҶеҝөдёҺж„ҝжҷҜ пјҢ дёӢйқўд»ҺгҖҢж•°жҚ®е®һи·өгҖҚе’ҢгҖҢж•°жҚ®з»„з»ҮиғҪеҠӣе»әи®ҫгҖҚзҡ„и§’еәҰи·ҹиҜ»иҖ…еҲҶдә«зҷҫеәҰеңЁиҝҲеҗ‘гҖҢж•°жҚ®иҪ¬еҢ–жҲҗй©ҫ驶иғҪеҠӣгҖҚйҒ“и·ҜдёҠзҡ„з»ҸйӘҢи®ӨзҹҘ гҖӮ
еӣһйЎҫзҷҫеәҰ7е№ҙиҮӘеҠЁй©ҫ驶жҠҖжңҜеҸ‘еұ•еҺҶзЁӢ пјҢ жҲ‘们е°Ҷз ”еҸ‘иҝӯд»ЈжЁЎејҸе®ҡд№үжҲҗдёүйҳ¶ж®ө пјҢ жҜҸдёӘйҳ¶ж®өеҜ№еә”зҡ„еңәжҷҜ пјҢ еҜ№дәәжүҚз»“жһ„е’Ңз»„з»ҮиғҪеҠӣзҡ„йңҖжұӮдёҚе°ҪзӣёеҗҢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
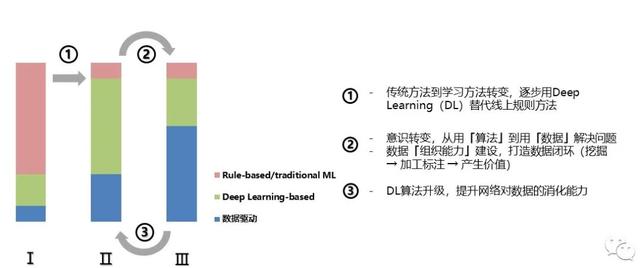
в–із ”еҸ‘жЁЎејҸиҝӯд»Је®ҡд№үдёүйҳ¶ж®ө пјҢ д»ҺеҹәдәҺ规еҲҷе’Ңдј з»ҹжңәеҷЁеӯҰд№ ж–№жі•йҖҗжӯҘеҗ‘ж•°жҚ®й©ұеҠЁжј”иҝӣйҳ¶ж®өв… вҖ“ жӯӨж—¶ж•°жҚ®еҹәзЎҖи®ҫж–Ҫе»әи®ҫзӣёеҜ№и–„ејұ пјҢ зі»з»ҹеҶ…Deep LearningеҢ–жЁЎеқ—/еҠҹиғҪеҚ жҜ”иҫғдҪҺ пјҢ з ”еҸ‘дё»еҠӣжҳҜе·ІеңЁжҹҗйўҶеҹҹз»ҸиҝҮй•ҝжңҹзі»з»ҹеҢ–и®ӯз»ғзҡ„算法专家 пјҢ 他们用计算жңәиҜӯиЁҖе°ҶжҺҢжҸЎзҡ„дё“дёҡзҹҘиҜҶиҪ¬еҢ–дёәеҠҹиғҪжҖ§зЎ®е®ҡзҡ„д»Јз Ғ пјҢ жҲ‘们еҶ…йғЁз§°иҝҷзұ»еҲқжңҹз®—жі•гҖҢRule-basedгҖҚе’ҢгҖҢTraditional Machine LearningгҖҚж–№жі• гҖӮ
вҖңRuleвҖқдёӯеҢ…еҗ«дәәдёәи®ҫе®ҡзҡ„规еҲҷе’ҢеҜ№зү©зҗҶдё–з•Ңзҡ„з»ҸйӘҢеҒҮи®ҫ пјҢ д»ҘиҪҰйҒ“зәҝжЈҖжөӢд»»еҠЎдёәдҫӢ пјҢ з»Ҹе…ёи®Ўз®—жңәи§Ҷи§үз®—жі•иғҪеӨҹдёҚдҫқиө–ж ҮжіЁж•°жҚ® пјҢ д»…дҪҝз”ЁжўҜеәҰи®Ўз®— пјҢ иҫ№зјҳжЈҖжөӢз®—еӯҗе’ҢжӣІзәҝжӢҹеҗҲзӯүз»Ҹе…ёжҠҖжңҜе®ҢжҲҗиҪҰйҒ“зәҝжҸҗеҸ– гҖӮ
Rule-basedж–№жі•дјҳеҠҝжҳҜдёҚдҫқиө–ж•°жҚ®зҡ„з§ҜзҙҜж ҮжіЁ пјҢ иҝҮжӢҹеҗҲжңүйҷҗеңәжҷҜжҜ”иҫғжңүж•Ҳ пјҢ з®—жі•д»Һз ”еҸ‘еҲ°дёҠи·ҜйҖҹеәҰеҝ« пјҢ йҖӮз”ЁдәҺprototypeжј”зӨәйҳ¶ж®өзҡ„з ”еҸ‘иҝӯд»Ј гҖӮ
еҸҰдёҖж–№йқў пјҢ 规еҲҷеҒҮи®ҫеј•е…ҘеӨ§йҮҸдәәе·ҘеҸӮж•°е’ҢеҲӨж–ӯжқЎд»¶ пјҢ дёҚеҲ©дәҺдёҡеҠЎйңҖжұӮеўһеҠ жөӢиҜ•и§„жЁЎжү©еӨ§еҗҺзҡ„жҠҖжңҜжіӣеҢ–д»ҘеҸҠеңәжҷҜжӢ“еұ• гҖӮ
Traditional Machine Learningж–№жі•еҰӮSVMе’ҢRandom ForestзӯүејҖе§ӢеҲ©з”Ёж•°жҚ®и§ЈеҶій—®йўҳ пјҢ иҝҷзұ»ж–№жі•еҜ№зү№еҫҒи®ҫи®Ўдҫқиө–ејә пјҢ з ”еҸ‘дәәе‘ҳйңҖиҰҒе…·еӨҮеҜ№ж•°жҚ®зү№еҫҒиҫғејәзҡ„зӣҙи§үе’ҢжҙһеҜҹеҠӣ гҖӮ
жӯӨеӨ– пјҢ е®ғ们зҡ„жө…еұӮжЁЎеһӢз»“жһ„еҜ№ж•°жҚ®зҡ„ж¶ҲеҢ–иғҪеҠӣжңүйҷҗ пјҢ еӨ§ж•°жҚ®еңЁд»»еҠЎдёҠеӯҳеңЁиҝҮжӢҹеҗҲ пјҢ 并дёҚиғҪеҫҲеҘҪзҡ„и§ЈеҶіеӨҚжқӮзҡ„иҮӘеҠЁй©ҫ驶问йўҳ гҖӮ
йҳ¶ж®өв… I вҖ“ иҝҷдёҖйҳ¶ж®өеӣҙз»•ж•°жҚ®жүҖеҒҡзҡ„еҹәзЎҖи®ҫж–Ҫе»әи®ҫи¶ӢдәҺе®Ңе–„ пјҢ ж•°жҚ®йҮҮйӣҶжөҒзЁӢе’Ңж Ү注规еҲҷжҳҺзЎ® пјҢ й…ҚеҘ—зҡ„ж•°жҚ®ж ҮжіЁе·Ҙе…·е’Ңж ҮжіЁеҲҶеҸ‘дҪ“зі»дҪҝз”ЁзЁіе®ҡ пјҢ ж•°жҚ®иҙЁйҮҸд»ҘеҸҠж•°жҚ®иҺ·еҸ–ж•ҲзҺҮзӣёжҜ”в… йҳ¶ж®өжңүиҙЁзҡ„жҸҗеҚҮ гҖӮ
жӯӨж—¶з ”еҸ‘дәәе‘ҳжңүж„ҸиҜҶзҡ„з”Ёж·ұеәҰеӯҰд№ жҖқжғійҮҚж–°е®Ўи§ҶзәҝдёҠRule-basedе’ҢTraditional Machine Learningж–№жі• пјҢ з§ҜжһҒе°қиҜ•з”ЁзҘһз»ҸзҪ‘з»ңпјҲDNNпјүеҜ№ж—§ж–№жі•иҝӣиЎҢж”№йҖ жӣҝжҚў гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- 马ж–Ҝе…ӢеҲҡжҲҗе…ЁзҗғйҰ–еҜҢпјҢиЎҢдёҡеҸҲзҲҶйҮҚзЈ…ж–°й—»пјҒзҷҫеәҰиҰҒйҖ жұҪиҪҰдәҶпјҢеҗҲдҪңж–№жҳҜе®ғпјҒдј дёҺиӢ№жһңеҗҲдҪңйҖ иҪҰпјҢйҹ©еӣҪжұҪиҪҰе·ЁеӨҙиӮЎд»·жҡҙж¶Ё
- дј й—»еқҗе®һпјҡжқҺд№ҰзҰҸжқҺеҪҰе®ҸиҒ”жүӢпјҒеҗүеҲ©зҷҫеәҰе®ҳе®ЈйҖ иҪҰ
- е°Ҹзұіжңүе“Ғдј—зӯ№жҝҖе…үйј»зӮҺжІ»з–—д»ӘпјҡдёҚеҗғиҚҜ дёҚејҖеҲҖ
- з”ЁжҲ·|2020дә’иҒ”зҪ‘гҖҢе№ҙз»ҲзӣҳзӮ№гҖҚд№ӢзӣҳзӮ№пјҡзҷҫеәҰжңҖжіӘзӣ®пјҢи¶ЈеӨҙжқЎжҺҘең°ж°”
- 2021е№ҙдә’иҒ”зҪ‘е·ЁеӨҙ第дёҖд»—пјҒйЈһд№ҰејҖж’•еҫ®дҝЎпјҢйҳҝйҮҢеҚҺдёәзҷҫеәҰе…ЁйғҪе…ҘеұҖ
- 2020зҷҫеәҰең°еӣҫз”ҹжҖҒеӨ§дјҡпјҡејҖж”ҫе№іеҸ°еҚҒе‘Ёе№ҙ дёәиЎҢдёҡйҖҒеҮәеӨҡдёӘи§ЈеҶіж–№жЎҲвҖңеӨ§зӨјеҢ…вҖқ
- дёҖдёӘдәәе®ҢжҲҗAIејҖеҸ‘е’ҢйғЁзҪІ зҷҫеәҰйЈһжЎЁе®һзҺ°й“Ғи·Ҝиҙ§иҪҰиҪҰеҸ·зІҫеҮҶжЈҖжөӢ
- жӣқiPhone 13е…Ёзі»ж Үй…ҚжҝҖе…үйӣ·иҫҫжү«жҸҸд»Ә зңҹе°ұеҚҒдёүйҰҷпјҹ
- зҷҫеәҰзҪ‘зӣҳдё»дҪ“е…¬еҸёеҸ‘з”ҹеҸҳжӣҙпјҢеёӮеҖјзҝ»еҖҚжӯЈеҖјжӢҶеҲҶдёҠеёӮеҘҪж—¶жңәпјҹ
- д»Һе·ҘзЁӢеёҲеҲ°вҖңж°ҙжһңзҢҺдәәвҖқд»–еңЁзҷҫеәҰеҒҡ科жҷ®