YOLO算法最全综述:从YOLOv1到YOLOv5
 文章插图
文章插图
作者:初识cv , 编辑:极市平台
来源丨 , 侵删
导读
YOLO系列是基于深度学习的回归方法 , 本文详细介绍了从YOLOv1至最新YOLOv5五种方法的主要思路、改进策略以及优缺点 。 YOLO官网:
YOLO v.s Faster R-CNN1.统一网络:YOLO没有显示求取region proposal的过程 。 Faster R-CNN中尽管RPN与fast rcnn共享卷积层 , 但是在模型训练过程中 , 需要反复训练RPN网络和fast rcnn网络.相对于R-CNN系列的"看两眼"(候选框提取与分类),YOLO只需要Look Once.
【YOLO算法最全综述:从YOLOv1到YOLOv5】2. YOLO统一为一个回归问题 , 而R-CNN将检测结果分为两部分求解:物体类别(分类问题) , 物体位置即bounding box(回归问题) 。
YOLOv1论文下载:
代码下载:
核心思想:将整张图片作为网络的输入(类似于Faster-RCNN) , 直接在输出层对BBox的位置和类别进行回归 。
实现方法
- 将一幅图像分成SxS个网格(grid cell) , 如果某个object的中心 落在这个网格中 , 则这个网格就负责预测这个object 。
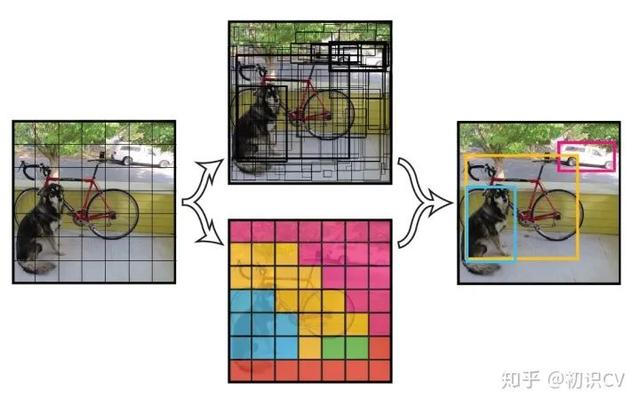 文章插图
文章插图- 每个网络需要预测B个BBox的位置信息和confidence(置信度)信息 , 一个BBox对应着四个位置信息和一个confidence信息 。 confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息:
- 每个bounding box要预测(x, y, w, h)和confidence共5个值 , 每个网格还要预测一个类别信息 , 记为C类 。 则SxS个网格 , 每个网格要预测B个bounding box还要预测C个categories 。 输出就是S x S x (5*B+C)的一个tensor 。 (注意:class信息是针对每个网格的 , confidence信息是针对每个bounding box的 。 )
- 举例说明: 在PASCAL VOC中 , 图像输入为448x448 , 取S=7 , B=2 , 一共有20个类别(C=20) 。 则输出就是7x7x30的一个tensor 。 整个网络结构如下图所示:
 文章插图
文章插图- 在test的时候 , 每个网格预测的class信息和bounding box预测的confidence信息相乘 , 就得到每个bounding box的class-specific confidence score:
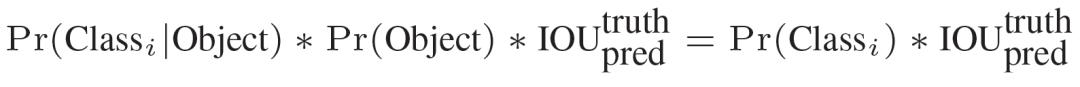 文章插图
文章插图等式左边第一项就是每个网格预测的类别信息 , 第二三项就是每个bounding box预测的confidence 。 这个乘积即encode了预测的box属于某一类的概率 , 也有该box准确度的信息 。
- 得到每个box的class-specific confidence score以后 , 设置阈值 , 滤掉得分低的boxes , 对保留的boxes进行NMS处理 , 就得到最终的检测结果 。
(1) 给个一个输入图像 , 首先将图像划分成7*7的网格
(2) 对于每个网格 , 我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
(3) 根据上一步可以预测出7*7*2个目标窗口 , 然后根据阈值去除可能性比较低的目标窗口 , 最后NMS去除冗余窗口即可
损失函数在实现中 , 最主要的就是怎么设计损失函数 , 让这个三个方面得到很好的平衡 。 作者简单粗暴的全部采用了sum-squared error loss来做这件事 。
推荐阅读






![[达达带你看世界]东北人最下饭的十道小咸菜,你吃过吗?贼下饭!想想都流口水!](http://ttbs.guangsuss.com/image/7bdd22d439da728f277b7b372786b133)


![[泰国资讯指南]尚泰告知商户书信:准备5月1日开门营业](https://imgcdn.toutiaoyule.com/20200420/20200420154018099232a_t.jpeg)

- 向日葵远程控制企业版客户端更新升级,优化远控UI适配SADDC内核算法
- 在谷歌算法更新之后2020年盗版网站流量锐减三分之一
- 详解工程师不可不会的LRU缓存淘汰算法
- 今天上海这个比赛上,获奖“程序媛”讲述了自己与算法的爱恨情仇
- 算法萌新如何学好动态规划(3)
- 这场赛事的主角是算法!——首届BPAA全球算法最佳实践典范大赛在上海启动
- 谷歌AI又获重大突破!新算法无需了解规则也能自学成“棋”
- 米家飞利浦台灯3发售:199元、AA级照度+自动算法调节
- 布局AI药物研发!华为招聘药物研发算法工程师,早有准备进军医疗行业?
- 苹果拍照成像好的秘密,源于更优的软件算法