YOLO算法最全综述:从YOLOv1到YOLOv5( 三 )
联合训练算法的基本思路就是:同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ) , 用检测数据集的数据学习物体的准确位置 , 用分类数据集的数据来增加分类的类别量、提升健壮性 。
YOLO9000就是使用联合训练算法训练出来的 , 他拥有9000类的分类信息 , 这些分类信息学习自ImageNet分类数据集 , 而物体位置检测则学习自COCO检测数据集 。
 文章插图
文章插图
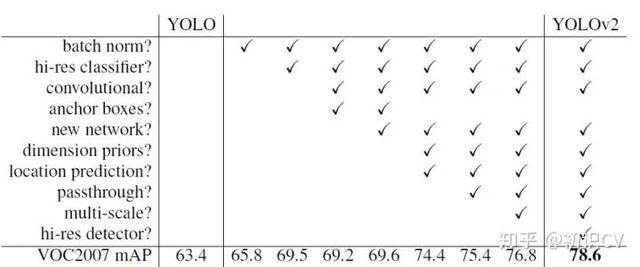
YOLOv2相比YOLOv1的改进策略
改进:Batch Normalization(批量归一化)
mAP提升2.4% 。
批归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题 , 降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性 , 并且每个batch分别进行归一化的时候 , 起到了一定的正则化效果(YOLO2不再使用dropout) , 从而能够获得更好的收敛速度和收敛效果 。
通常 , 一次训练会输入一批样本(batch)进入神经网络 。 批规一化在神经网络的每一层 , 在网络(线性变换)输出后和激活函数(非线性变换)之前增加一个批归一化层(BN) , BN层进行如下变换:①对该批样本的各特征量(对于中间层来说 , 就是每一个神经元)分别进行归一化处理 , 分别使每个特征的数据分布变换为均值0 , 方差1 。 从而使得每一批训练样本在每一层都有类似的分布 。 这一变换不需要引入额外的参数 。 ②对上一步的输出再做一次线性变换 , 假设上一步的输出为Z , 则Z1=γZ + β 。 这里γ、β是可以训练的参数 。 增加这一变换是因为上一步骤中强制改变了特征数据的分布 , 可能影响了原有数据的信息表达能力 。 增加的线性变换使其有机会恢复其原本的信息 。
关于批规一化的更多信息可以参考 Batch Normalization原理与实战 。
High resolution classifier(高分辨率图像分类器)
mAP提升了3.7% 。
图像分类的训练样本很多 , 而标注了边框的用于训练对象检测的样本相比而言就比较少了 , 因为标注边框的人工成本比较高 。 所以对象检测模型通常都先用图像分类样本训练卷积层 , 提取图像特征 。 但这引出的另一个问题是 , 图像分类样本的分辨率不是很高 。 所以YOLO v1使用ImageNet的图像分类样本采用 224*224 作为输入 , 来训练CNN卷积层 。 然后在训练对象检测时 , 检测用的图像样本采用更高分辨率的 448*448 的图像作为输入 。 但这样切换对模型性能有一定影响 。
所以YOLO2在采用 224*224 图像进行分类模型预训练后 , 再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch) , 使网络特征逐渐适应 448*448 的分辨率 。 然后再使用 448*448 的检测样本进行训练 , 缓解了分辨率突然切换造成的影响 。
Convolution with anchor boxes(使用先验框)
召回率大幅提升到88% , 同时mAP轻微下降了0.2 。
YOLOV1包含有全连接层 , 从而能直接预测Bounding Boxes的坐标值 。 Faster R-CNN的方法只用卷积层与Region Proposal Network来预测Anchor Box的偏移值与置信度 , 而不是直接预测坐标值 。 作者发现通过预测偏移量而不是坐标值能够简化问题 , 让神经网络学习起来更容易 。
借鉴Faster RCNN的做法 , YOLO2也尝试采用先验框(anchor) 。 在每个grid预先设定一组不同大小和宽高比的边框 , 来覆盖整个图像的不同位置和多种尺度 , 这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象 , 以及微调边框的位置 。
之前YOLO1并没有采用先验框 , 并且每个grid只预测两个bounding box , 整个图像98个 。 YOLO2如果每个grid采用9个先验框 , 总共有13*13*9=1521个先验框 。 所以最终YOLO去掉了全连接层 , 使用Anchor Boxes来预测 Bounding Boxes 。 作者去掉了网络中一个Pooling层 , 这让卷积层的输出能有更高的分辨率 。 收缩网络让其运行在416*416而不是448*448 。
推荐阅读













- 向日葵远程控制企业版客户端更新升级,优化远控UI适配SADDC内核算法
- 在谷歌算法更新之后2020年盗版网站流量锐减三分之一
- 详解工程师不可不会的LRU缓存淘汰算法
- 今天上海这个比赛上,获奖“程序媛”讲述了自己与算法的爱恨情仇
- 算法萌新如何学好动态规划(3)
- 这场赛事的主角是算法!——首届BPAA全球算法最佳实践典范大赛在上海启动
- 谷歌AI又获重大突破!新算法无需了解规则也能自学成“棋”
- 米家飞利浦台灯3发售:199元、AA级照度+自动算法调节
- 布局AI药物研发!华为招聘药物研发算法工程师,早有准备进军医疗行业?
- 苹果拍照成像好的秘密,源于更优的软件算法