YOLO算法最全综述:从YOLOv1到YOLOv5( 四 )
由于图片中的物体都倾向于出现在图片的中心位置 , 特别是那种比较大的物体 , 所以有一个单独位于物体中心的位置用于预测这些物体 。 YOLO的卷积层采用32这个值来下采样图片 , 所以通过选择416*416用作输入尺寸最终能输出一个13*13的Feature Map 。 使用Anchor Box会让精确度稍微下降 , 但用了它能让YOLO能预测出大于一千个框 , 同时recall达到88% , mAP达到69.2% 。
Dimension clusters(聚类提取先验框的尺度信息)
之前Anchor Box的尺寸是手动选择的 , 所以尺寸还有优化的余地 。 YOLO2尝试统计出更符合样本中对象尺寸的先验框 , 这样就可以减少网络微调先验框到实际位置的难度 。 YOLO2的做法是对训练集中标注的边框进行K-mean聚类分析 , 以寻找尽可能匹配样本的边框尺寸 。
如果我们用标准的欧式距离的k-means , 尺寸大的框比小框产生更多的错误 。 因为我们的目的是提高IOU分数 , 这依赖于Box的大小 , 所以距离度量的使用:
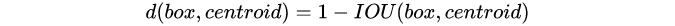 文章插图
文章插图
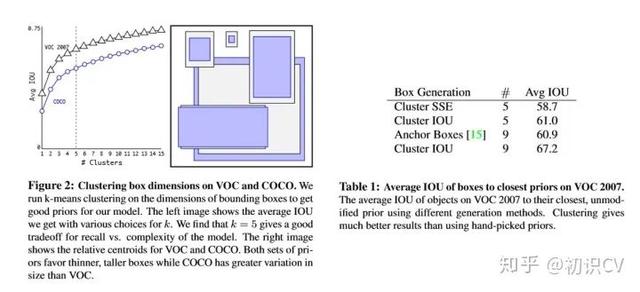
centroid是聚类时被选作中心的边框 , box就是其它边框 , d就是两者间的“距离” 。 IOU越大 , “距离”越近 。 YOLO2给出的聚类分析结果如下图所示:
通过分析实验结果(Figure 2) , 左图:在model复杂性与high recall之间权衡之后 , 选择聚类分类数K=5 。 右图:是聚类的中心 , 大多数是高瘦的Box 。
Table1是说明用K-means选择Anchor Boxes时 , 当Cluster IOU选择值为5时 , AVG IOU的值是61 , 这个值要比不用聚类的方法的60.9要高 。 选择值为9的时候 , AVG IOU更有显著提高 。 总之就是说明用聚类的方法是有效果的 。
 文章插图
文章插图
约束预测边框的位置)
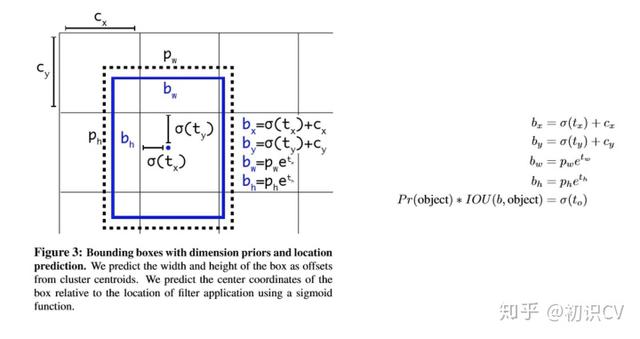
借鉴于Faster RCNN的先验框方法 , 在训练的早期阶段 , 其位置预测容易不稳定 。 其位置预测公式为:
其中 ,是预测边框的中心 ,是先验框(anchor)的中心点坐标 ,是先验框(anchor)的宽和高 ,是要学习的参数 。 注意 , YOLO论文中写的是, 根据Faster RCNN , 应该是"+" 。
由于 的取值没有任何约束 , 因此预测边框的中心可能出现在任何位置 , 训练早期阶段不容易稳定 。 YOLO调整了预测公式 , 将预测边框的中心约束在特定gird网格内 。
其中 ,是预测边框的中心和宽高 。是预测边框的置信度 , YOLO1是直接预测置信度的值 , 这里对预测参数 进行σ变换后作为置信度的值 。是当前网格左上角到图像左上角的距离 , 要先将网格大小归一化 , 即令一个网格的宽=1 , 高=1 。是先验框的宽和高 。 σ是sigmoid函数 。是要学习的参数 , 分别用于预测边框的中心和宽高 , 以及置信度 。
 文章插图
文章插图
因为使用了限制让数值变得参数化 , 也让网络更容易学习、更稳定 。
Fine-Grained Features(passthrough层检测细粒度特征)
passthrough层检测细粒度特征使mAP提升1 。
对象检测面临的一个问题是图像中对象会有大有小 , 输入图像经过多层网络提取特征 , 最后输出的特征图中(比如YOLO2中输入416*416经过卷积网络下采样最后输出是13*13) , 较小的对象可能特征已经不明显甚至被忽略掉了 。 为了更好的检测出一些比较小的对象 , 最后输出的特征图需要保留一些更细节的信息 。
YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息 。 具体来说 , 就是在最后一个pooling之前 , 特征图的大小是26*26*512 , 将其1拆4 , 直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图 , 两者叠加到一起作为输出的特征图 。
推荐阅读













- 向日葵远程控制企业版客户端更新升级,优化远控UI适配SADDC内核算法
- 在谷歌算法更新之后2020年盗版网站流量锐减三分之一
- 详解工程师不可不会的LRU缓存淘汰算法
- 今天上海这个比赛上,获奖“程序媛”讲述了自己与算法的爱恨情仇
- 算法萌新如何学好动态规划(3)
- 这场赛事的主角是算法!——首届BPAA全球算法最佳实践典范大赛在上海启动
- 谷歌AI又获重大突破!新算法无需了解规则也能自学成“棋”
- 米家飞利浦台灯3发售:199元、AA级照度+自动算法调节
- 布局AI药物研发!华为招聘药物研发算法工程师,早有准备进军医疗行业?
- 苹果拍照成像好的秘密,源于更优的软件算法