YOLO算法最全综述:从YOLOv1到YOLOv5( 二 )
这种做法存在以下几个问题:
- 第一 , 8维的localization error和20维的classification error同等重要显然是不合理的;
- 第二 , 如果一个网格中没有object(一幅图中这种网格很多) , 那么就会将这些网格中的box的confidence push到0 , 相比于较少的有object的网格 , 这种做法是overpowering的 , 这会导致网络不稳定甚至发散 。
- 更重视8维的坐标预测 , 给这些损失前面赋予更大的loss weight 。
- 对没有object的box的confidence loss , 赋予小的loss weight 。
- 有object的box的confidence loss和类别的loss的loss weight正常取1 。
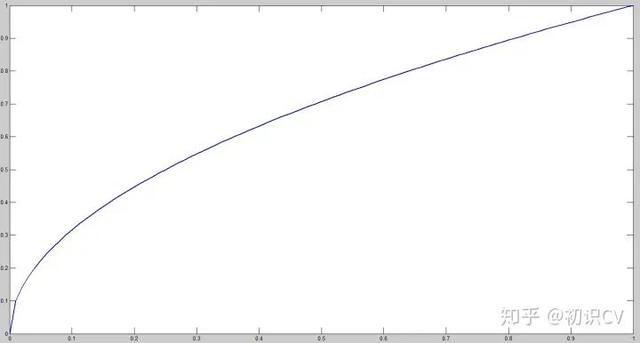
为了缓和这个问题 , 作者用了一个比较取巧的办法 , 就是将box的width和height取平方根代替原本的height和width 。 这个参考下面的图很容易理解 , 小box的横轴值较小 , 发生偏移时 , 反应到y轴上相比大box要大 。 (也是个近似逼近方式)
 文章插图
文章插图一个网格预测多个box , 希望的是每个box predictor专门负责预测某个object 。 具体做法就是看当前预测的box与ground truth box中哪个IoU大 , 就负责哪个 。 这种做法称作box predictor的specialization 。
最后整个的损失函数如下所示:
 文章插图
文章插图这个损失函数中:
- 只有当某个网格中有object的时候才对classification error进行惩罚 。
- 只有当某个box predictor对某个ground truth box负责的时候 , 才会对box的coordinate error进行惩罚 , 而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大 。
优点
- 快速 , pipline简单.
- 背景误检率低 。
- 通用性强 。 YOLO对于艺术类作品中的物体检测同样适用 。 它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法 。
- 由于输出层为全连接层 , 因此在检测时 , YOLO训练模型只支持与训练图像相同的输入分辨率 。
- 虽然每个格子可以预测B个bounding box , 但是最终只选择只选择IOU最高的bounding box作为物体检测输出 , 即每个格子最多只预测出一个物体 。 当物体占画面比例较小 , 如图像中包含畜群或鸟群时 , 每个格子包含多个物体 , 但却只能检测出其中一个 。 这是YOLO方法的一个缺陷 。
- YOLO loss函数中 , 大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式 , 但没有根本解决问题) 。 因此 , 对于小物体 , 小的IOU误差也会对网络优化过程造成很大的影响 , 从而降低了物体检测的定位准确性 。
YOLOv2相对v1版本 , 在继续保持处理速度的基础上 , 从预测更准确(Better) , 速度更快(Faster) , 识别对象更多(Stronger)这三个方面进行了改进 。 其中识别更多对象也就是扩展到能够检测9000种不同对象 , 称之为YOLO9000 。
文章提出了一种新的训练方法–联合训练算法 , 这种算法可以把这两种的数据集混合到一起 。 使用一种分层的观点对物体进行分类 , 用巨量的分类数据集数据来扩充检测数据集 , 从而把两种不同的数据集混合起来 。
推荐阅读











- 向日葵远程控制企业版客户端更新升级,优化远控UI适配SADDC内核算法
- 在谷歌算法更新之后2020年盗版网站流量锐减三分之一
- 详解工程师不可不会的LRU缓存淘汰算法
- 今天上海这个比赛上,获奖“程序媛”讲述了自己与算法的爱恨情仇
- 算法萌新如何学好动态规划(3)
- 这场赛事的主角是算法!——首届BPAA全球算法最佳实践典范大赛在上海启动
- 谷歌AI又获重大突破!新算法无需了解规则也能自学成“棋”
- 米家飞利浦台灯3发售:199元、AA级照度+自动算法调节
- 布局AI药物研发!华为招聘药物研发算法工程师,早有准备进军医疗行业?
- 苹果拍照成像好的秘密,源于更优的软件算法