YOLO算法最全综述:从YOLOv1到YOLOv5( 六 )
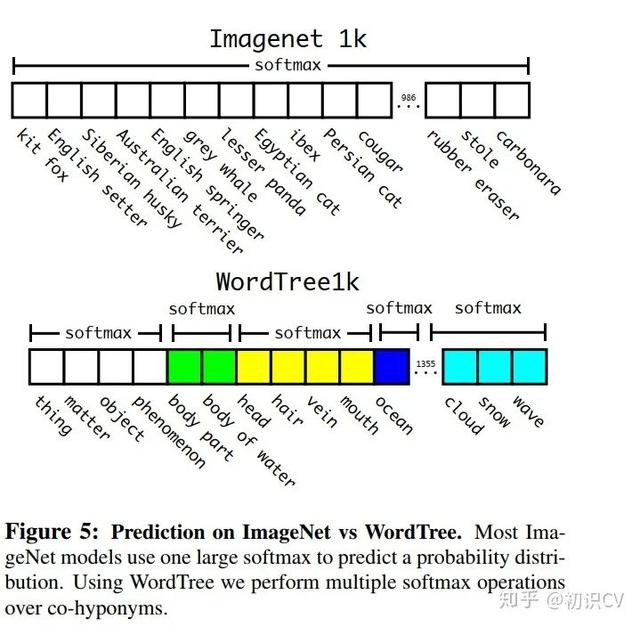
softmax操作也同时应该采用分组操作 , 下图上半部分为ImageNet对应的原生Softmax , 下半部分对应基于WordTree的Softmax:
 文章插图
文章插图
通过上述方案构造WordTree , 得到对应9418个分类 , 通过重采样保证Imagenet和COCO的样本数据比例为4:1 。
YOLOv3论文地址:
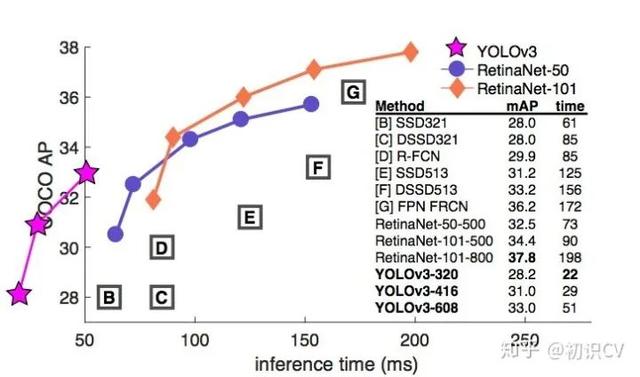
YOLO v3的模型比之前的模型复杂了不少 , 可以通过改变模型结构的大小来权衡速度与精度 。
速度对比如下:
 文章插图
文章插图
简而言之 , YOLOv3 的先验检测(Prior detection)系统将分类器或定位器重新用于执行检测任务 。 他们将模型应用于图像的多个位置和尺度 。 而那些评分较高的区域就可以视为检测结果 。 此外 , 相对于其它目标检测方法 , 我们使用了完全不同的方法 。 我们将一个单神经网络应用于整张图像 , 该网络将图像划分为不同的区域 , 因而预测每一块区域的边界框和概率 , 这些边界框会通过预测的概率加权 。 我们的模型相比于基于分类器的系统有一些优势 。 它在测试时会查看整个图像 , 所以它的预测利用了图像中的全局信息 。 与需要数千张单一目标图像的 R-CNN 不同 , 它通过单一网络评估进行预测 。 这令 YOLOv3 非常快 , 一般它比 R-CNN 快 1000 倍、比 Fast R-CNN 快 100 倍 。
改进之处
- 多尺度预测 (引入FPN) 。
- 更好的基础分类网络(darknet-53, 类似于ResNet引入残差结构) 。
- 分类器不在使用Softmax , 分类损失采用binary cross-entropy loss(二分类交叉损失熵)
- Softmax使得每个框分配一个类别(score最大的一个) , 而对于
Open Images这种数据集 , 目标可能有重叠的类别标签 , 因此Softmax不适用于多标签分类 。
- Softmax可被独立的多个logistic分类器替代 , 且准确率不会下降 。
多尺度预测每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3个尺度.
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息.
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
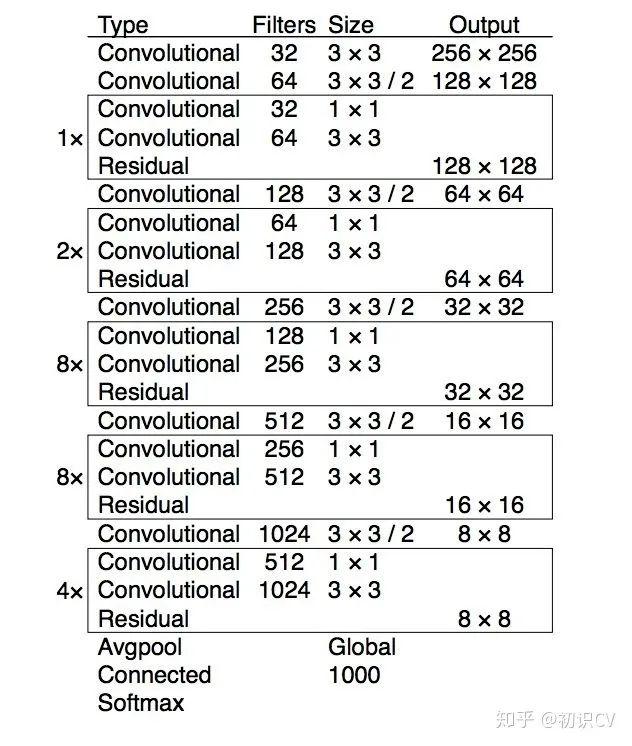
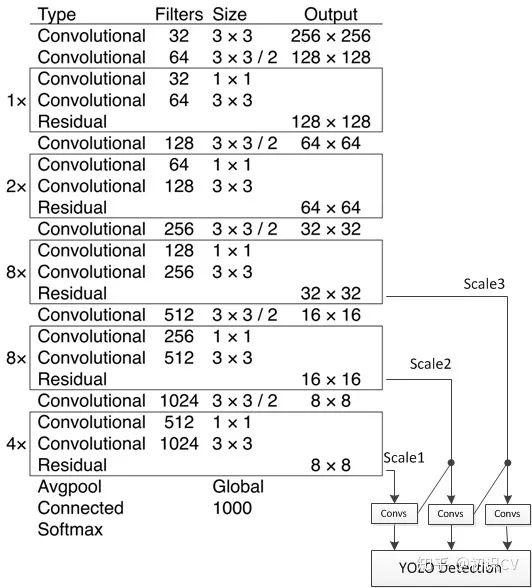
基础网络 Darknet-53
 文章插图
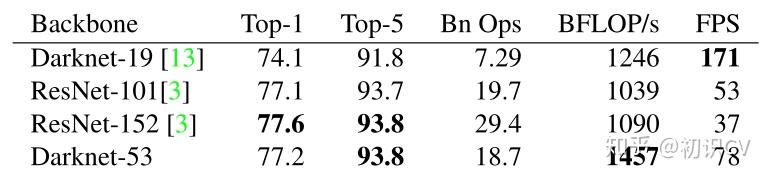
文章插图darknet-53仿ResNet, 与ResNet-101或ResNet-152准确率接近,但速度更快.对比如下:
 文章插图
文章插图主干架构的性能对比检测结构如下:
 文章插图
文章插图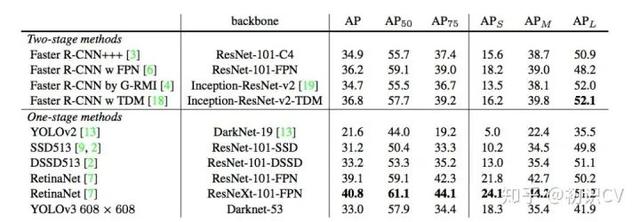 文章插图
文章插图YOLOv3在mAP@0.5及小目标APs上具有不错的结果,但随着IOU的增大,性能下降,说明YOLOv3不能很好地与ground truth切合.
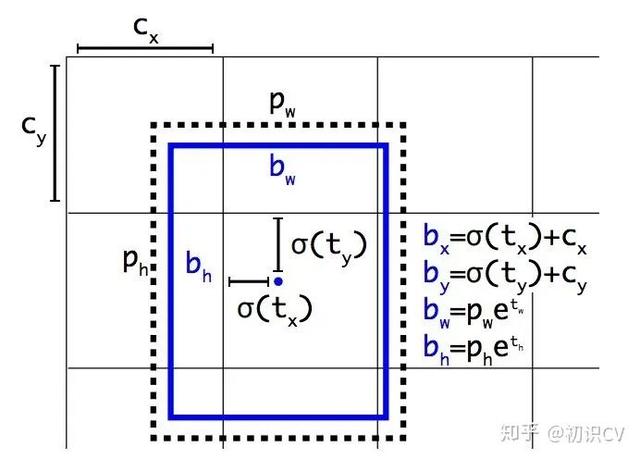
边框预测
 文章插图
文章插图图 2:带有维度先验和定位预测的边界框 。 我们边界框的宽和高以作为离聚类中心的位移 , 并使用 Sigmoid 函数预测边界框相对于滤波器应用位置的中心坐标 。
推荐阅读











- 向日葵远程控制企业版客户端更新升级,优化远控UI适配SADDC内核算法
- 在谷歌算法更新之后2020年盗版网站流量锐减三分之一
- 详解工程师不可不会的LRU缓存淘汰算法
- 今天上海这个比赛上,获奖“程序媛”讲述了自己与算法的爱恨情仇
- 算法萌新如何学好动态规划(3)
- 这场赛事的主角是算法!——首届BPAA全球算法最佳实践典范大赛在上海启动
- 谷歌AI又获重大突破!新算法无需了解规则也能自学成“棋”
- 米家飞利浦台灯3发售:199元、AA级照度+自动算法调节
- 布局AI药物研发!华为招聘药物研发算法工程师,早有准备进军医疗行业?
- 苹果拍照成像好的秘密,源于更优的软件算法