жўҜеәҰзӣҙж–№еӣҫ(HOG)з”ЁдәҺеӣҫеғҸеӨҡеҲҶзұ»е’ҢеӣҫеғҸжҺЁиҚҗ( дёү )
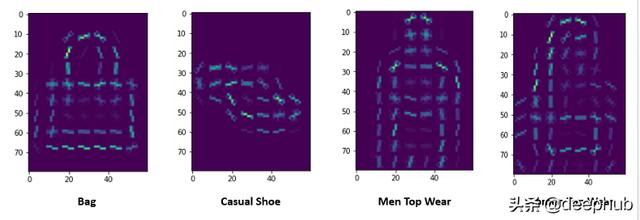
дёӢйқўжҳҜдёҖдәӣHOGеӣҫеғҸзҡ„еҸҜи§ҶеҢ–иЎЁзӨә:
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еңЁе»әжЁЎдёӯдҪҝз”ЁжўҜеәҰж–№еҗ‘зҡ„жғіжі•жҳҜеӣ дёәиҝҷз§Қж–№жі•дәәзұ»зҘһз»Ҹзі»з»ҹзҡ„е·ҘдҪңж–№ејҸзӣёдјј гҖӮ еҪ“дәәзұ»зңӢеҲ°жҹҗдёҖзү©дҪ“ж—¶ пјҢ еӨ§и„‘зҡ®еұӮдјҡеј•иө·дәә们зҡ„жіЁж„Ҹ пјҢ жҲ–иҖ…дәәзұ»дёәдәҶзңӢеҫ—жӣҙжё…жҘҡиҖҢж”№еҸҳи§ӮеҜҹзҡ„и§’еәҰ
з”ұдәҺжҳҜеӨҡеҲҶзұ»й—®йўҳ пјҢ иҖҢдё”зұ»еҶ…еҲҶеёғд№ҹдёҚеқҮеҢҖ пјҢ е»әи®®йҮҮз”ЁеҲҶеұӮжҠҪж · гҖӮ
X_train, X_test, y_train, y_test = train_test_split(hog_features,df_labels['class'],test_size=0.2,stratify=df_labels['class'])print('Training data and target sizes: \n{}, {}'.format(X_train.shape,y_train.shape))print('Test data and target sizes: \n{}, {}'.format(X_test.shape,y_test.shape))=============================================Training data and target sizes: (15998, 1728), (15998,)Test data and target sizes: (4000, 1728), (4000,)жңҖеҗҺ пјҢ е°Ҷж•°жҚ®дҪҝз”ЁеҲҶзұ»еҷЁеӨ„зҗҶ гҖӮ й’ҲеҜ№иҜҘй—®йўҳ пјҢ еҲҶеҲ«йҮҮз”ЁдәҶж”ҜжҢҒеҗ‘йҮҸжңәгҖҒйҡҸжңәжЈ®жһ—е’ҢKNNз®—жі• гҖӮ еңЁжүҖжңүжңҖиҝ‘йӮ»жҹҘжүҫз®—жі•(balltreeгҖҒkdtreeе’Ңbrute force)дёӯ пјҢ KNNзҡ„иЎЁзҺ°йғҪдјҳдәҺе…¶д»–еҲҶзұ»еҷЁ гҖӮ жңҖеҗҺ пјҢ дҪҝз”Ё"иҙӘе©Ә"жҗңзҙў пјҢ еӣ дёәе®ғзҡ„и®Ўз®—йҖҹеәҰжҜ”balltreeе’Ңkdtreeеҝ«еҫ—еӨҡ гҖӮ
KNNеҲҶзұ»еҷЁзҡ„д»Јз ҒзүҮж®ө
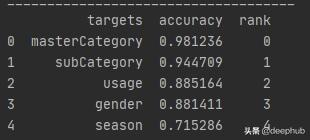
test_accuracy = []scaler = StandardScaler()X_scaled = scaler.fit_transform(X_train)classifier = KNeighborsClassifier(n_neighbors=3,algorithm='brute')classifier.fit(X_scaled, y_train)test_accuracy = classifier.score(scaler.transform(X_test), y_test)print(test_accuracy)еңЁmasterCategoryдёӯ пјҢ дё»иҰҒеҢ…жӢ¬д»ҘдёӢдә”дёӘзұ»еҲ«:["жңҚйҘ°"гҖҒ"й…ҚйҘ°"гҖҒ"йһӢеұҘ"гҖҒ"дёӘдәәжҠӨзҗҶ"гҖҒ"е…Қиҙ№зү©е“Ғ"] гҖӮ жүҖжңүеұһдәҺе…¶д»–зұ»еҲ«зҡ„и®°еҪ•иў«е‘ҪеҗҚдёә"е…¶д»–" гҖӮ
йҖҡиҝҮжӣҙж”№Jupyter笔记жң¬дёӯзҡ„еҲ—еҗҚ пјҢ еҸҜд»ҘеҜ№д»»дҪ•еҲ—зұ»еһӢиҝӣиЎҢеҲҶзұ» гҖӮ
дёӢйқўжҳҜдёҖдәӣжңүеҠ©дәҺиҜ„дј°жЁЎеһӢжҖ§иғҪзҡ„ж•°еӯ— гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
list_of_categories = categories +['Others']print("Classification Report: \n Target: %s \n Labels: %s \n Classifier: %s:\n%s\n"% (target,list_of_categories,classifier, metrics.classification_report(y_test, y_pred)))df_report = pd.DataFrame(metrics.confusion_matrix(y_test, y_pred),columns = list_of_categories )df_report.index = [list_of_categories]df_report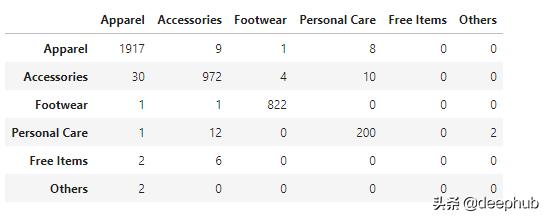 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жңҖеҗҺ пјҢ и®©жҲ‘们еҜ№жөӢиҜ•еӣҫеғҸиҝӣиЎҢжҺЁж–ӯ
#test image with idtest_data_location = root+'/test/'img = cv.imread(test_data_location+'1570.jpg',cv.IMREAD_GRAYSCALE) #load at gray scaleimage = cv.resize(img, (60, 80),interpolation =cv.INTER_LINEAR)ppcr = 8ppcc = 8hog_images_test = []hog_features_test = []blur = cv.GaussianBlur(image,(5,5),0)fd_test,hog_img = hog(blur, orientations=8, pixels_per_cell=(ppcr,ppcc),cells_per_block=(2,2),block_norm= 'L2',visualize=True)hog_images_test.append(hog_img)hog_features_test.append(fd)hog_features_test = np.array(hog_features_test)y_pred_user = classifier.predict(scaler.transform(hog_features_test))#print(plt.imshow(hog_images_test))print(y_pred_user)print("Predicted MaterCategory: ", mapper[mapper['class']==int(y_pred_user)]['masterCategory'])дёҖдәӣе»әи®®!
scaler_global = MinMaxScaler()final_features_scaled = scaler_global.fit_transform(hog_features)neighbors = NearestNeighbors(n_neighbors=20, algorithm='brute')neighbors.fit(final_features_scaled)distance,potential = neighbors.kneighbors(scaler_global.transform(hog_features_test))print("Potential Neighbors Found!")neighbors = []for i in potential[0]:neighbors.append(i)recommendation_list = list(df_labels.iloc[neighbors]['id'])recommendation_list











![[з»ҝиұҶ]з”·дәәжғіиҰҒй•ҝеҜҝпјҢ5件вҖңиҖ—йҳівҖқзҡ„дәӢиҰҒвҖңиҲҚејғвҖқпјҢдёҖдәӣдәәиЎЁзӨәеҫҲйҡҫеҒҡеҲ°](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/26fa2bbcc60faf5ef39679c3f1999fd3.jpg)




