еӨ§е°Ҹе…¬еҸёйғҪйҖӮз”Ёзҡ„жһ¶жһ„йҖүеһӢе·Ҙе…·з®ұпјҲж¶өзӣ–дёҠзҷҫдёӘ组件пјү
2020е№ҙж–°зүҲ пјҢ еҜ№йғЁеҲҶ组件зҡ„жҸҸиҝ°иҝӣиЎҢдәҶжӣҙж–° гҖӮ еҰӮжһңдҪ еңЁеҒҡйҖүеһӢж–№йқўзҡ„е·ҘдҪң пјҢ жҲ–иҖ…жғідәҶи§ЈдёҖдәӣзҺ°еңЁжӯЈеңЁжөҒиЎҢзҡ„жҠҖжңҜ пјҢ йӮЈд№ҲиҝҷзҜҮж–Үз« жӯЈеҘҪйҖӮеҗҲдҪ гҖӮ
жң¬зҜҮеҶ…е®№ж¶өзӣ–14дёӘж–№йқў пјҢ ж¶үеҸҠдёҠзҷҫдёӘжЎҶжһ¶е’Ңе·Ҙе…· гҖӮ дјҡжңүдҪ е–ңж¬ўзҡ„ пјҢ еӨ§жҰӮд№ҹдјҡжңүдҪ жүҖи®ЁеҺҢзҡ„家дјҷ гҖӮ иҝҷжҳҜжҲ‘е№іеёёе·ҘдҪңдёӯжү“дәӨйҒ“жңҖеӨҡзҡ„е·Ҙе…· пјҢ еӨ§е°Ҹе…¬еҸёйғҪйҖӮз”Ё гҖӮ
дёҖгҖҒж¶ҲжҒҜйҳҹеҲ—
дәҢгҖҒзј“еӯҳ
дёүгҖҒеҲҶеә“еҲҶиЎЁ
еӣӣгҖҒж•°жҚ®еҗҢжӯҘ
дә”гҖҒйҖҡи®Ҝ
е…ӯгҖҒеҫ®жңҚеҠЎ
дёғгҖҒеҲҶеёғејҸе·Ҙе…·
е…«гҖҒзӣ‘жҺ§зі»з»ҹ
д№қгҖҒи°ғеәҰ
еҚҒгҖҒе…ҘеҸЈе·Ҙе…·
еҚҒдёҖгҖҒOLTпјҲAпјүP
еҚҒдәҢгҖҒCI/CD
еҚҒдёүгҖҒй—®йўҳжҺ’жҹҘ
еҚҒеӣӣгҖҒжң¬ең°е·Ҙе…·
дёҖгҖҒж¶ҲжҒҜйҳҹеҲ—
жҺЁиҚҗпјҡ
1.еҗһеҗҗйҮҸдјҳе…ҲйҖүжӢ©kafka
2.зЁіе®ҡжҖ§дјҳе…ҲйҖүжӢ©RocketMQ
3.зү©иҒ”зҪ‘пјҡVerneMQ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
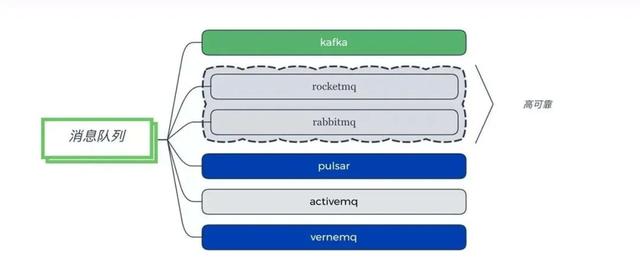
дёҖдёӘеӨ§еһӢзҡ„еҲҶеёғејҸзі»з»ҹ пјҢ йҖҡеёёйғҪдјҡејӮжӯҘеҢ– пјҢ иө°ж¶ҲжҒҜжҖ»зәҝ гҖӮ ж¶ҲжҒҜйҳҹеҲ—дҪңдёәжңҖдё»иҰҒзҡ„еҹәзЎҖ组件 пјҢ еңЁж•ҙдёӘдҪ“зі»жһ¶жһ„дёӯ пјҢ жңүзқҖеҸҠе…¶йҮҚиҰҒзҡ„дҪңз”Ё гҖӮ ејӮжӯҘйҖҡеёёж„Ҹе‘ізқҖзј–зЁӢжЁЎеһӢзҡ„ж”№еҸҳ пјҢ ж—¶ж•ҲжҖ§дјҡйҷҚдҪҺ гҖӮ
kafkaжҳҜзӣ®еүҚжңҖеёёз”Ёзҡ„ж¶ҲжҒҜйҳҹеҲ— пјҢ е°Өе…¶жҳҜеңЁеӨ§ж•°жҚ®ж–№йқў пјҢ жңүзқҖжһҒй«ҳзҡ„еҗһеҗҗйҮҸ гҖӮ иҖҢrocketmqе’Ңrabbitmq пјҢ йғҪжҳҜз”өдҝЎзә§еҲ«зҡ„ж¶ҲжҒҜйҳҹеҲ— пјҢ еңЁдёҡеҠЎдёҠз”Ёзҡ„жҜ”иҫғеӨҡ гҖӮ зӣёжҜ”иҫғиҖҢиЁҖ пјҢ ActiveMQдҪҝз”Ёзҡ„жңҖе°‘ пјҢ еұһдәҺиҫғиҖҒдёҖд»Јзҡ„ж¶ҲжҒҜжЎҶжһ¶ гҖӮ
pulsarжҳҜдёәдәҶи§ЈеҶідёҖдәӣkafkaдёҠзҡ„й—®йўҳиҖҢиҜһз”ҹзҡ„ж¶ҲжҒҜзі»з»ҹ пјҢ жҜ”иҫғе№ҙиҪ» пјҢ е·Ҙе…·й“ҫжңүйҷҗ гҖӮ жңүдәӣжҝҖиҝӣзҡ„еӣўйҳҹз»ҸиҝҮиҜ•з”Ё пјҢ еҸҚе“ҚдёҚй”ҷ пјҢ дҪҶе®һйҷ…дҪҝ用并дёҚеӨҡ гҖӮ
mqttе…·дҪ“жқҘиҜҙжҳҜдёҖз§ҚеҚҸи®® пјҢ дё»иҰҒз”ЁеңЁзү©иҒ”зҪ‘ж–№йқў пјҢ иғҪеӨҹеҸҢеҗ‘йҖҡдҝЎ пјҢ еұһдәҺж¶ҲжҒҜйҳҹеҲ—иҢғз•ҙ пјҢ жҺЁиҚҗдҪҝз”Ёvernemq гҖӮ
дәҢгҖҒзј“еӯҳ
жҺЁиҚҗпјҡ
1.е ҶеҶ…зј“еӯҳдҪҝз”Ёй»ҳи®Өзҡ„caffeine
2. еҲҶеёғејҸзј“еӯҳйҮҮз”Ёredisзҡ„clusterйӣҶзҫӨжЁЎејҸ пјҢ дҪҶиҰҒжіЁж„ҸдҪҝз”ЁйҷҗеҲ¶ гҖӮ
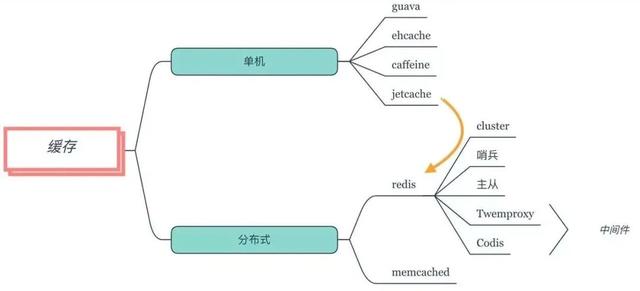
ж•°жҚ®зј“еӯҳжҳҜеҮҸе°‘ж•°жҚ®еә“еҺӢеҠӣзҡ„жңүж•ҲйҖ”еҫ„ пјҢ жңүеҚ•жңәjavaеҶ…зј“еӯҳ пјҢ е’ҢеҲҶеёғејҸзј“еӯҳд№ӢеҲҶ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҜ№дәҺеҚ•жңәжқҘиҜҙ пјҢ guavaзҡ„LoadingCacheе’ҢehcacheйғҪжҳҜдәӣзҶҹйқўеӯ” пјҢ дёҚиҝҮSpringBootйҖүжӢ©дәҶcaffeineдҪңдёәе®ғзҡ„й»ҳи®Өе ҶеҶ…зј“еӯҳ пјҢ иҝҷжҳҜеӣ дёәcaffeineзҡ„йҖҹеәҰжҜ”иҫғеҝ«зҡ„еҺҹеӣ гҖӮ
еҜ№дәҺеҲҶеёғејҸзј“еӯҳжқҘиҜҙ пјҢ дјҳе…ҲйҖүжӢ©зҡ„е°ұжҳҜredis пјҢ еҲ«зҠ№иұ« гҖӮ з”ұдәҺredisжҳҜеҚ•зәҝзЁӢзҡ„пјҲ6.0ж”ҜжҢҒеӨҡзәҝзЁӢ пјҢ дҪҶй»ҳи®ӨдёҚејҖеҗҜпјү пјҢ 并дёҚйҖӮеҗҲй«ҳиҖ—ж—¶ж“ҚдҪң гҖӮ жүҖд»ҘеҜ№дәҺдёҖдәӣж•°жҚ®йҮҸжҜ”иҫғеӨ§зҡ„зј“еӯҳ пјҢ жҜ”еҰӮеӣҫзүҮгҖҒи§Ҷйў‘зӯү пјҢ дҪҝз”ЁиҖҒзүҢзҡ„memcachedж•ҲжһңдјҡеҘҪзҡ„еӨҡ гҖӮ
JetCacheжҳҜдёҖдёӘеҹәдәҺJavaзҡ„зј“еӯҳзі»з»ҹе°ҒиЈ… пјҢ жҸҗдҫӣз»ҹдёҖзҡ„apiе’ҢжіЁи§ЈжқҘз®ҖеҢ–зј“еӯҳзҡ„дҪҝз”Ё гҖӮ зұ»дјјSpringCache пјҢ ж”ҜжҢҒжң¬ең°зј“еӯҳе’ҢеҲҶеёғејҸзј“еӯҳ пјҢ д№ҹжҳҜз®ҖеҢ–ејҖеҸ‘зҡ„еҲ©еҷЁ гҖӮ
дёүгҖҒеҲҶеә“еҲҶиЎЁ
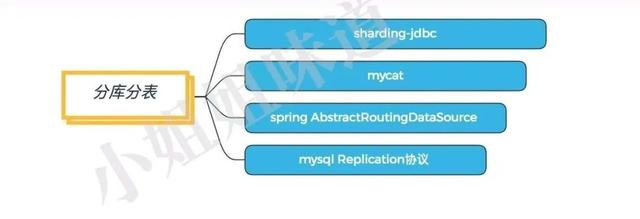
жҺЁиҚҗпјҡshardingsphereдёӯзҡ„sharding-jdbc
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҲҶеә“еҲҶиЎЁ пјҢ еҮ д№ҺжҜҸдёҖдёӘдёҠзӮ№и§„жЁЎзҡ„е…¬еҸё пјҢ йғҪдјҡжңүиҮӘе·ұзҡ„ж–№жЎҲ гҖӮ зӣ®еүҚ пјҢ жҺЁиҚҗдҪҝз”Ёй©ұеҠЁеұӮзҡ„sharding-jdbcпјҲе·Із»Ҹиҝӣе…Ҙapacheпјү пјҢ жҲ–иҖ…д»ЈзҗҶеұӮзҡ„mycat гҖӮ еҰӮжһңдҪ жІЎжңүйўқеӨ–зҡ„иҝҗз»ҙеӣўйҳҹ пјҢ еҸҲдёҚжғіиҠұй’ұд№°е…¶д»–жңәеҷЁ пјҢ йӮЈд№Ҳе°ұйҖүеүҚиҖ… гҖӮ
еҰӮжһңеҲҶеә“еҲҶиЎЁж¶үеҸҠзҡ„йЎ№зӣ®дёҚеӨҡ пјҢ springзҡ„еҠЁжҖҒж•°жҚ®жәҗжҳҜдёҖдёӘйқһеёёеҘҪзҡ„йҖүжӢ© гҖӮ е®ғзӣҙжҺҘзј–з ҒеңЁд»Јз ҒйҮҢ пјҢ зӣҙи§ӮдҪҶдёҚжҳ“жү©еұ• гҖӮ
еҰӮжһңеҸӘйңҖиҰҒиҜ»еҶҷеҲҶзҰ»пјҢ йӮЈд№Ҳmysqlе®ҳж–№й©ұеҠЁйҮҢзҡ„replicationеҚҸи®® пјҢ жҳҜжӣҙеҠ иҪ»йҮҸзә§зҡ„йҖүжӢ© гҖӮ
дёҠйқўзҡ„еҲҶеә“еҲҶ表组件 пјҢ йғҪжҳҜеӨ§жөӘж·ҳжІҷ пјҢ жңҖз»Ҳзҡ„дјҳиғңе“Ғ гҖӮ иҝҷдәӣ组件дёҚеҗҢдәҺ其他组件йҖүеһӢ пјҢ ж–№жЎҲдёҖж—ҰзЎ®е®ҡ пјҢ еҮ д№Һж— жі•еӣһйҖҖ пјҢ жүҖд»ҘиҰҒж…Һд№ӢеҸҲж…Һ гҖӮ
еҲҶеә“еҲҶиЎЁжҳҜе°Ҹcase пјҢ еҮҶеӨҮеҲҶеә“еҲҶиЎЁзҡ„йҳ¶ж®ө пјҢ жүҚжҳҜйҮҚзӮ№пјҡд№ҹе°ұжҳҜж•°жҚ®еҗҢжӯҘ гҖӮ
еӣӣгҖҒж•°жҚ®еҗҢжӯҘ
жҺЁиҚҗпјҡcanal гҖӮ
жҺЁиҚҗйҳ…иҜ»












![[еҠұеҝ—и§Ҷйў‘зҹӯзүҮ]еҒҡеҘҪдәӢпјҢеҫ®з¬‘жҢӮж»ЎдёӨи…®жүҚжҳҜжӯЈйҒ“пјҒпјҢж—©е®үеҝғиҜӯпјҡеӯҳеҘҪеҝғ](https://imgcdn.toutiaoyule.com/20200503/20200503054140414532a_t.jpeg)




- дёүжҳҹе…¬еҸёеҸ‘еёғ2021ж¬ҫж•°еӯ—еә§иҲұ йӣҶжҲҗиҜёеӨҡй«ҳ科жҠҖ
- еҸҜйқ е®һз”Ёзҡ„жңҖдҪіжӢҚжЎЈ жі•зҝјT1жү§жі•и®°еҪ•д»ӘдҪ“йӘҢиҜ„жөӢ
- е”җеұұеӣӣз»ҙжҷәиғҪ科жҠҖжңүйҷҗе…¬еҸёпјҡеҸҢиҮӮжңәеҷЁдәәеј•йўҶдәәжңәеҚҸдҪңж–°зәӘе…ғ
- DeepMindе·ЁдәҸ42дәҝгҖҒзӢ¬и§’е…ҪжғЁйҒӯ3жҠҳиҙұеҚ–пјҢAIе…¬еҸёдёәдҪ•йҡҫжңүвҖңеҘҪдёӢеңәвҖқпјҹ
- зҫҺеӘ’пјҡзҫҺеӣҪжӢүе°ҸејҹжҗһејҖж”ҫзҪ‘з»ң规иҢғж‘Ҷи„ұеҚҺдёә дҪҶжӣҙеӨҡдёӯеӣҪе…¬еҸёеҠ е…Ҙз«һдәүжҗ…й»„зҫҺж–№и®ЎеҲ’
- дёҖжұҪи§Јж”ҫйқ’еІӣе…¬еҸёпјҡжҜҸ216з§’еҲ¶йҖ дёҖиҫҶеҚЎиҪҰпјҢйҰ–еҸ°ж–°иғҪжәҗиҪ»еҚЎд»Ҡе№ҙ10жңҲдёӢзәҝ
- дј з»ҹ1/10еӨ§е°Ҹ дёғеҪ©иҷ№еҸ‘еёғжңҖе°Ҹзҡ„mini SSDзЎ¬зӣҳпјҡжҖ§иғҪйҰ–ж¬Ўе…¬ејҖ
- еҢ—зҫҺж–°жөӘеӣһеә”е®ҳзҪ‘еҹҹеҗҚеҒңз”ЁпјҒеҒңжӯўжӣҙж–°еӣ е…¬еҸёдёҡеҠЎи°ғж•ҙ
- ж·ұеңіз¬¬дёҖеҘійҰ–еҜҢпјҡжү“иҙҘйғӯеҸ°й“ӯпјҢжҲҗдёәиӢ№жһңе…¬еҸёйҮ‘зүҢдҫӣеә”е•Ҷ
- е…¬еҸё|вҖңеұ…ж°‘е·Ід№ жғҜж— дәәжңәйҖҒе’–е•ЎвҖқжҫіеӘ’з§°з–«жғ…дёӯж— дәәжңәйңҖжұӮйҮҸеӨ§еўһ