жўҜеәҰзӣҙж–№еӣҫ(HOG)з”ЁдәҺеӣҫеғҸеӨҡеҲҶзұ»е’ҢеӣҫеғҸжҺЁиҚҗ
д»Ӣз»ҚжңәеҷЁеӯҰд№ зҡ„зҘһеҘҮд№ӢеӨ„еңЁдәҺ пјҢ жҲ‘们еҜ№еҺҹзҗҶзҡ„жҰӮеҝөе’ҢжҖқи·ҜзҗҶи§Јеҫ—и¶ҠеӨҡ пјҢ е®ғе°ұеҸҳеҫ—и¶Ҡе®№жҳ“ гҖӮ еңЁжң¬ж–Үдёӯ пјҢ жҲ‘们е°Ҷз ”з©¶еңЁеӣҫеғҸеҲҶзұ»е’ҢеӣҫеғҸжҺЁиҚҗдёӯдҪҝз”Ёе®ҡеҗ‘жўҜеәҰзӣҙж–№еӣҫзҡ„ж–№жі• гҖӮ
ж•°жҚ®йӣҶ ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жқҘжәҗ:Kaggle FashionеӣҫеғҸеҲҶзұ»ж•°жҚ®йӣҶ(Small)
kaggle/paramaggarwal/fashion-product-images-small
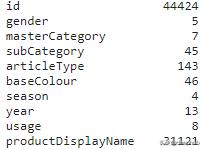
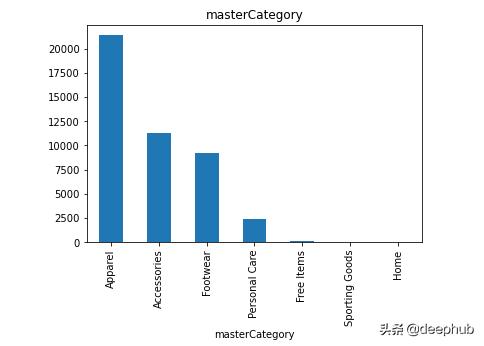
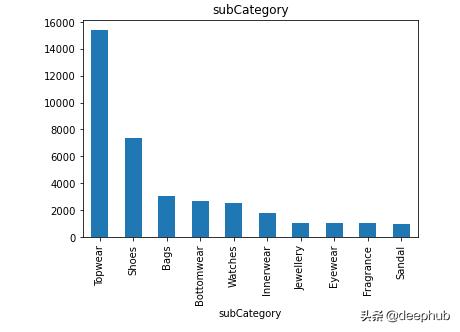
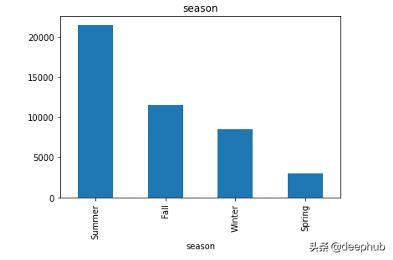
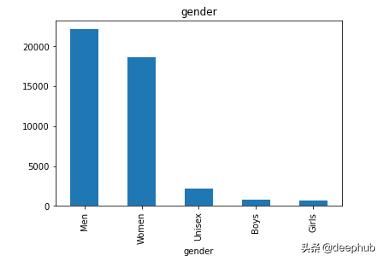
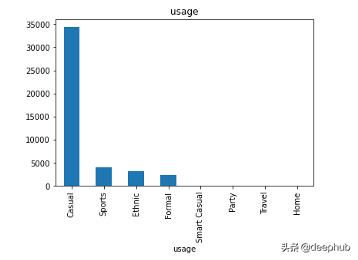
ж•°жҚ®йӣҶжңүдё»зұ»еҲ«гҖҒеӯҗзұ»еҲ«гҖҒжҖ§еҲ«гҖҒеӯЈиҠӮе’ҢжҜҸдёӘеӣҫеғҸзҡ„ж Үзӯҫ гҖӮ зӣ®зҡ„жҳҜе°Ҷж•°жҚ®йӣҶз”ЁдәҺеӣҫеғҸеҲҶзұ»е’ҢжҺЁиҚҗ гҖӮ и®©жҲ‘们е…ҲзңӢзңӢж•°жҚ®еҲҶеёғ!
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҜҸдёӘеҲ—зҡ„жғҹдёҖеҖј гҖӮ еҜ№дәҺжҜҸдёӘжҖ§еҲ« пјҢ masterCategoryгҖҒsubCategoryгҖҒgenderгҖҒusageе’ҢseasonеҲ—дҪҝз”ЁKNNеҲҶзұ»еҷЁиҝӣиЎҢеӣҫеғҸеҲҶзұ» пјҢ 然еҗҺдҪҝз”ЁKдёӘжңҖиҝ‘йӮ»ж•°жҚ®иҝӣиЎҢеӣҫеғҸжҺЁиҚҗ
иҝҷдёӘи®ҫи®Ўзҡ„зӣ®ж ҮжҳҜжҸҗеҮәдёҖдёӘи§ЈеҶіж–№жЎҲ пјҢ е°ҶжүҖжңүзҡ„зұ»еҲ«еҲҶдёәдёҚеҗҢзҡ„зұ»(зұ»жҳҜеңЁдёӢйқўзҡ„еӣҫиЎЁдёӯжҸҗеҲ°зҡ„еҲҶеёғ) гҖӮ 然еҗҺжһ„е»әжҺЁиҚҗеј•ж“Һ пјҢ ж №жҚ®з”ЁжҲ·йҖүжӢ©зҡ„жөӢиҜ•еӣҫеғҸ пјҢ з»ҷеҮәжңҖеҢ№й…Қзҡ„nе№…еӣҫеғҸ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҜҸеҲ—дёӢдёҚеҗҢзұ»зҡ„ж•°жҚ®(еҸӘжҳҫзӨәеүҚ10дёӘ)
еҲҶзұ»е’ҢжҺЁиҚҗжҳҜе»әз«ӢеңЁдёҖз§ҚеұҖйғЁзү№еҫҒжҸҗеҸ–е’ҢжҸҸиҝ°ж–№жі•дёҠзҡ„ пјҢ еҚіе®ҡеҗ‘жўҜеәҰзӣҙж–№еӣҫ(Histogram of Oriented Gradients, HOG) гҖӮ дҪҝз”ЁдёҚеҗҢзҡ„зү№еҫҒжЈҖжөӢеҷЁ(дҫӢеҰӮ:SIFT, Shi-Thomas, ORB, FASTзӯү) пјҢ жҲ‘们еҸҜд»Ҙе®ҡдҪҚзү№еҫҒ пјҢ 并еңЁеӨҡе№…еӣҫеғҸд№Ӣй—ҙеҢ№й…ҚжҸҗеҸ–зҡ„зү№еҫҒ гҖӮ дҪҶжҳҜдёәдәҶдҪҝз”ЁиҝҷдәӣдҝЎжҒҜжқҘи®ӯз»ғдёҖдёӘжЁЎеһӢ пјҢ жҲ‘们йңҖиҰҒжҸҗеҸ–дёҖз»ҙеҗ‘йҮҸеҪўејҸзҡ„зү№еҫҒ(еҰӮ[x1,x2 пјҢ .. пјҢ xn]) гҖӮ HOG("Histogram of Oriented Gradients for Human Detection\"вҖ”вҖ”Dalal & Triggs, 2005)зҡ„жғіжі•е°ұжҳҜеҹәдәҺеҗҢж ·зҡ„еҺҹзҗҶ гҖӮ дёӢйқўи®©жҲ‘们зңӢзңӢHOGжҳҜеҰӮдҪ•е·ҘдҪңзҡ„ пјҢ д»ҘеҸҠеҰӮдҪ•еңЁPythonдёӯй…ҚзҪ®е®ғ гҖӮ
жіЁж„Ҹ:HOGжңҖеҲқжҳҜз”ұDalal & Triggs(2005)еҸ‘жҳҺзҡ„ пјҢ 他们дҪҝз”Ёзү№е®ҡзҡ„еҸӮж•°жқҘиҺ·еҫ—жңҖдҪізҡ„дәәдҪ“жЈҖжөӢжҖ§иғҪ гҖӮ дҪҶжҳҜ пјҢ иҝҷдәӣеҸӮж•°дёҚжҳҜйҖҡз”Ёзҡ„ пјҢ е№¶дё”ж №жҚ®еӣҫеғҸзұ»еһӢзҡ„дёҚеҗҢиҖҢеҸҳеҢ– гҖӮ
и®Ўз®—HOGзҡ„жӯҘйӘӨ:HOGжҳҜдёҖз§Қе°ҶеӣҫеғҸиҪ¬жҚўдёәжўҜеәҰзӣҙж–№еӣҫ пјҢ 然еҗҺдҪҝз”Ёзӣҙж–№еӣҫеҲ¶дҪңз”ЁдәҺи®ӯз»ғжЁЎеһӢзҡ„дёҖз»ҙзҹ©йҳөзҡ„жҠҖжңҜ гҖӮ
еңЁжҲ‘们计算д№ӢеүҚ пјҢ и®©жҲ‘们е…ҲеҜје…Ҙзӣёе…іеә“!
import osimport numpy as npimport pandas as pdimport cv2 as cvfrom pathlib import Pathimport warningsfrom skimage.feature import hogimport tqdmfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn import metricsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import MinMaxScalerfrom sklearn.neighbors import NearestNeighborswarnings.filterwarnings("ignore")pd.options.display.max_columns = None然еҗҺиҜ»еҸ–еӣҫзүҮ
all_images = []#labels = []def load_image(ids,path=image_folder):img = cv.imread(image_folder+ids+'.jpg',cv.IMREAD_GRAYSCALE) #load at gray scale#img = cv.cvtColor(img, cv.COLOR_BGR2GRAY) #convert to gray scalereturn img,ids#20k samples were taken for modelingfor ids in tqdm(list(styles.id)[:20000]):img,ids = load_image(str(ids))if img is not None:all_images.append([img,int(ids)])#labels.append(ids)len(all_images)














