дҪҝз”ЁжңәеҷЁеӯҰд№ ж•°жҚ®йӣҶжһ„е»әй”Җе”®йў„жөӢWebеә”з”ЁзЁӢеәҸ( дәҢ )
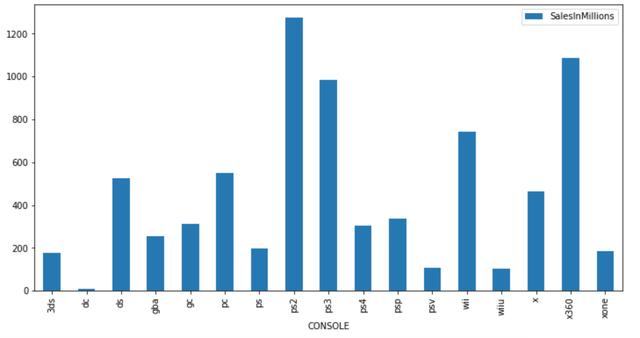
PS3е№іеҸ°зҡ„й”Җе”®йўқжңҖй«ҳ гҖӮ д№ӢеҗҺжҳҜXbox360пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
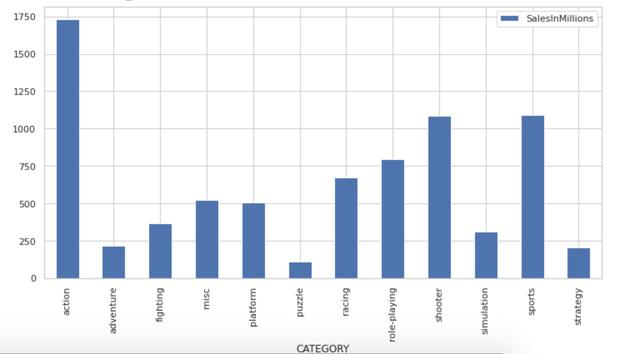
еҠЁдҪңзұ»еҲ«зҡ„й”Җе”®йўқжңҖй«ҳ пјҢ йҡҫйўҳзұ»еҲ«зҡ„й”Җе”®йўқжңҖдҪҺ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
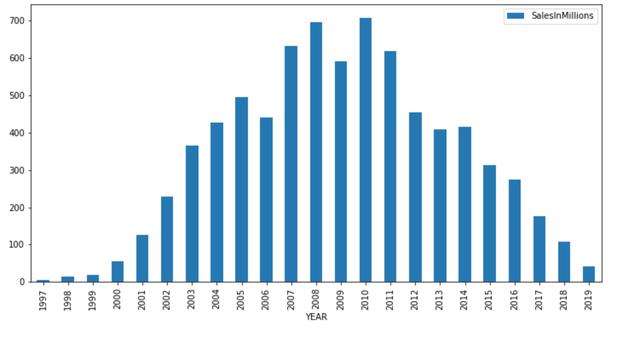
2007е№ҙеҲ°2011е№ҙзҡ„й”Җе”®йўқжңҖй«ҳпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йҖҡеёё пјҢ жҲ‘们еңЁEDAд№ӢеҗҺиҝӣиЎҢзү№еҫҒе·ҘзЁӢжҲ–зү№еҫҒйҖүжӢ©жӯҘйӘӨ гҖӮ дҪҶжҳҜ пјҢ жҲ‘们зҡ„еҠҹиғҪиҫғе°‘ пјҢ зқҖйҮҚдәҺе®һйҷ…дҪҝз”ЁжЁЎеһӢ гҖӮ еӣ жӯӨ пјҢ жҲ‘们жӯЈеңЁжңқзқҖдёӢдёҖжӯҘиҝҲиҝӣ гҖӮ дҪҶжҳҜ пјҢ иҜ·и®°дҪҸ пјҢ USER_POINTSе’ҢCRITICS_POINTSеҲ—еҸҜз”ЁдәҺжҙҫз”ҹе…¶д»–еҠҹиғҪ гҖӮ
жӯҘйӘӨ4пјҡе»әз«ӢжЁЎеһӢ
з”ұдәҺжҲ‘们具жңүи®ёеӨҡеҲҶзұ»еҠҹиғҪ пјҢ еӣ жӯӨжҲ‘们е°ҶеҜ№ж•°жҚ®йӣҶдҪҝз”ЁcatboostеӣһеҪ’жЁЎеһӢ гҖӮ з”ұдәҺcatboostеҸҜд»ҘзӣҙжҺҘдҪңз”ЁдәҺеҲҶзұ»зү№еҫҒ пјҢ еӣ жӯӨи·іиҝҮдәҶеҜ№еҲҶзұ»зү№еҫҒиҝӣиЎҢж Үзӯҫзј–з Ғзҡ„жӯҘйӘӨ гҖӮ
йҰ–е…Ҳ пјҢ жҲ‘们дҪҝз”Ёpip installе‘Ҫд»Өе®үиЈ…catboostиҪҜ件еҢ… гҖӮ
然еҗҺ пјҢ жҲ‘们еҲӣе»әдёҖдёӘеҲҶзұ»зү№еҫҒеҲ—иЎЁ пјҢ е°Ҷе…¶дј йҖ’з»ҷжЁЎеһӢ пјҢ 然еҗҺе°ҶжЁЎеһӢжӢҹеҗҲеҲ°и®ӯз»ғж•°жҚ®йӣҶдёҠпјҡ
import catboost as catcat_feat = ['CONSOLE','CATEGORY', 'PUBLISHER', 'RATING']features = list(set(train.columns)-set(['SalesInMillions']))target = 'SalesInMillions'model = cat.CatBoostRegressor(random_state=100,cat_features=cat_feat,verbose=0)model.fit(train[features],train[target])жӯҘйӘӨ5пјҡжЈҖжҹҘжЁЎеһӢзҡ„еҮҶзЎ®жҖ§
йҰ–е…Ҳ пјҢ жҲ‘д»¬ж №жҚ®жөӢиҜ•ж•°жҚ®йӣҶеҲӣе»әзңҹе®һзҡ„йў„жөӢпјҡ
y_true= pd.DataFrame(data=http://kandian.youth.cn/index/test[target], columns=['SalesInMillions'])test_temp = test.drop(columns=[target])жҺҘдёӢжқҘ пјҢ жҲ‘们еңЁжөӢиҜ•ж•°жҚ®йӣҶдёҠиҝҗиЎҢи®ӯз»ғиүҜеҘҪзҡ„жЁЎеһӢд»ҘиҺ·еҸ–жЁЎеһӢйў„жөӢ并жЈҖжҹҘжЁЎеһӢеҮҶзЎ®жҖ§
y_pred = model.predict(test_temp[features])from sklearn.metrics import mean_squared_errorfrom math import sqrtrmse = sqrt(mean_squared_error(y_true, y_pred))print(rmse)#Output: 1.5555409360901584жҲ‘们зҡ„RMSEеҖјдёә1.5 пјҢ иҝҷзӣёеҪ“дёҚй”ҷ гҖӮ жңүе…іеңЁеҮәзҺ°еӣһеҪ’й—®йўҳж—¶еҮҶзЎ®жҖ§жҢҮж Үзҡ„жӣҙеӨҡдҝЎжҒҜ пјҢ еҸҜд»ҘеҸӮиҖғжң¬ж–Ү гҖӮ
зҺ°еңЁ пјҢ жҲ‘们еҸҜд»Ҙе°ҶжЁЎеһӢдҝқеӯҳеҲ°pickleж–Ү件дёӯ пјҢ 然еҗҺе°Ҷе…¶дҝқеӯҳеңЁжң¬ең°пјҡ
import picklefilename = 'finalized_model.sav'pickle.dump(model, open(filename, 'wb'))дҝқеӯҳpickleж–Ү件еҗҺ пјҢ дҪ еҸҜд»Ҙд»ҺGoogle Colab Notebookж–Ү件йғЁеҲҶзҡ„е·Ұдҫ§иҫ№ж ҸдёӯдёӢиҪҪ并дҝқеӯҳеңЁжң¬ең° ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫйўқеӨ–жҸҗзӨә
- ж·»еҠ жӣҙеӨҡж•°жҚ®
- жҸҗй«ҳжЁЎеһӢж•ҲзҺҮ
еҰӮжһңдҪ е·Іе®ҢжҲҗжӯӨжӯҘйӘӨ пјҢ иҜ·иҪ»жӢҚдёҖдёӢиҮӘе·ұзҡ„иғҢ пјҢ еӣ дёәжҲ‘们еҲҡеҲҡе®ҢжҲҗдәҶйЎ№зӣ®зҡ„第дёҖдёӘдё»иҰҒйғЁеҲҶ гҖӮ дј‘жҒҜдёҖдјҡе„ҝ пјҢ жӢүдјёдёҖдёӢ пјҢ 然еҗҺејҖе§Ӣжң¬ж–Үзҡ„дёӢдёҖйғЁеҲҶ гҖӮ
第2йғЁеҲҶпјҡж №жҚ®жЁЎеһӢеҲӣе»әеҗҺз«ҜAPIжҲ‘们е°ҶдҪҝз”ЁPython FlaskеҲӣе»әеҗҺз«ҜAPI гҖӮ
еӣ жӯӨ пјҢ йҰ–е…ҲеңЁжң¬ең°еҲӣе»әдёҖдёӘеҗҚдёәserverзҡ„ж–Ү件еӨ№ гҖӮ еҸҰеӨ– пјҢ еҰӮжһңиҝҳжІЎжңү пјҢ иҜ·еңЁдҪ зҡ„и®Ўз®—жңәдёҠе®үиЈ…Pythonе’ҢpipиҪҜ件еҢ…з®ЎзҗҶеҷЁ гҖӮ
жҺҘдёӢжқҘ пјҢ жҲ‘们йңҖиҰҒеңЁж–Ү件еӨ№дёӯеҲӣе»әдёҖдёӘиҷҡжӢҹзҺҜеўғ гҖӮ жҲ‘еңЁLinuxдёҠдҪҝз”Ёpython3 пјҢ еӣ жӯӨжҲ‘еҲӣе»әиҷҡжӢҹзҺҜеўғзҡ„е‘Ҫд»Өдёәпјҡpython3 -m venv server гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- е”җеұұеӣӣз»ҙжҷәиғҪ科жҠҖжңүйҷҗе…¬еҸёпјҡеҸҢиҮӮжңәеҷЁдәәеј•йўҶдәәжңәеҚҸдҪңж–°зәӘе…ғ
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- еӨ§дј—еұ•зӨәEVе…¬е…ұе……з”өж–°и§ЈеҶіж–№жЎҲпјҡ移еҠЁе……з”өжңәеҷЁдәә
- жҷ®жёЎжңәеҷЁдәәиҺ·жңҖдҪіе•Ҷз”ЁжңҚеҠЎжңәеҷЁдәәеҘ–
- зҝ»иҜ‘|жңәеҷЁзҝ»иҜ‘иғҪиҫҫ60дёӘиҜӯз§Қ3000дёӘж–№еҗ‘пјҢиҝ‘ж—ҘеҸҲеӨәе…Ёзҗғдә”еҶ пјҢиҝҷ家зүӣдјҒжҳҜи°Ғпјҹ
- еҒҮжңҹејҜйҒ“и¶…иҪҰ еӣҪзҫҺеӯҰд№ вҖңзҘһеҷЁвҖқеҠ©еӯ©еӯҗеҸҳиә«вҖңеӯҰйңёвҖқ
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘