дҪҝз”ЁжңәеҷЁеӯҰд№ ж•°жҚ®йӣҶжһ„е»әй”Җе”®йў„жөӢWebеә”з”ЁзЁӢеәҸ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
д»Ӣз»Қдә’иҒ”зҪ‘дёҠжңүеҫҲеӨҡиө„жәҗеҸҜд»ҘжүҫеҲ°е…ідәҺжңәеҷЁеӯҰд№ ж•°жҚ®йӣҶзҡ„и§Ғи§Је’Ңи®ӯз»ғжЁЎеһӢ пјҢ дҪҶжҳҜе…ідәҺеҰӮдҪ•дҪҝз”ЁиҝҷдәӣжЁЎеһӢжһ„е»әе®һйҷ…еә”з”ЁзЁӢеәҸзҡ„ж–Үз« еҫҲе°‘ гҖӮ
еӣ жӯӨ пјҢ д»ҠеӨ©жҲ‘们е°ҶйҖҡиҝҮйҰ–е…ҲдҪҝз”Ёhackathonдёӯзҡ„ж•°жҚ®йӣҶжқҘи®ӯз»ғи§Ҷйў‘жёёжҲҸй”Җе”®йў„жөӢжЁЎеһӢ пјҢ 然еҗҺдҪҝз”Ёз»ҸиҝҮи®ӯз»ғзҡ„жЁЎеһӢжқҘеҲӣе»әдёҖдёӘеҹәжң¬еә”з”ЁзЁӢеәҸ пјҢ ж №жҚ®з”ЁжҲ·иҫ“е…ҘдёәжҲ‘们жҸҗдҫӣй”Җе”®йў„жөӢжқҘеӯҰд№ жӯӨиҝҮзЁӢ гҖӮ
жң¬ж–ҮеҲҶдёәеӨҡдёӘйғЁеҲҶ пјҢ дҪ еҸҜд»ҘдёҖдёӘжҺҘдёҖдёӘең°еӯҰд№ пјҢ иҖҢдёҚеҝ…дёҖеҸЈж°”е®ҢжҲҗе®ғ гҖӮ д»ҺжҲ‘第дёҖж¬ЎйҖүжӢ©ж•°жҚ®йӣҶд»ҘжқҘ пјҢ жҲ‘иҠұдәҶж•ҙж•ҙдёҖе‘Ёзҡ„ж—¶й—ҙжқҘе®ҢжҲҗеә”з”ЁзЁӢеәҸ гҖӮ еӣ жӯӨ пјҢ иҜ·иҠұж—¶й—ҙдё“жіЁдәҺеӯҰд№ жһ„е»әеә”з”ЁзЁӢеәҸзҡ„еҗ„дёӘж–№йқў пјҢ иҖҢдёҚжҳҜеҸӘжіЁж„ҸжңҖз»Ҳдә§е“Ғ гҖӮ
第1йғЁеҲҶпјҡз”ҹжҲҗжЁЎеһӢжҲ‘们е°ҶдҪҝз”ЁеңЁMachine HackзҪ‘з«ҷдёҠиҝҗиЎҢзҡ„и§Ҷйў‘жёёжҲҸй”Җе”®йў„жөӢhackathonдёӯзҡ„ж•°жҚ®йӣҶ гҖӮ йҰ–е…Ҳ пјҢ еңЁMachineHackдёҠеҲӣе»әдёҖдёӘеёҗжҲ· пјҢ 然еҗҺеңЁжӯӨй“ҫжҺҘдёҠжіЁеҶҢhackathon гҖӮ
дёӢдёҖжӯҘе°ҶеңЁGoogle Colab Notebookдёӯд»Ӣз»Қ пјҢ дҪ еҸҜд»Ҙд»Һд»ҘдёӢй“ҫжҺҘжү“ејҖе’Ңе…ӢйҡҶиҜҘNotebookпјҡ
from google.colab import filesuploaded = files.upload()for fn in uploaded.keys():print('User uploaded file "{name}" with length {length} bytes'.format(name=fn, length=len(uploaded[fn])))еңЁдёӢдёҖдёӘд»Јз ҒеҚ•е…ғдёӯ пјҢ жҲ‘们еҜје…ҘжүҖйңҖзҡ„pythonеҢ… гҖӮ е®ғ们дёӯзҡ„еӨ§еӨҡж•°е·Ійў„е…Ҳе®үиЈ…еңЁGoogle Colabдёӯ пјҢ еӣ жӯӨж— йңҖе®үиЈ…е®ғ们дёӯзҡ„д»»дҪ•дёҖдёӘ гҖӮеӣ дёәжҲ‘д»¬ж— жі•еңЁhackathonз»“жқҹеҗҺжҸҗдәӨжөӢиҜ•ж•°жҚ®иҝӣиЎҢиҜ„дј° пјҢ еӣ жӯӨжң¬ж–Үе…¶дҪҷйғЁеҲҶд»…е°Ҷж•°жҚ®з”ЁдәҺTrain.csv гҖӮ иҜ·и®°дҪҸ пјҢ Train.csvзҡ„иЎҢж•°е°‘дәҺйҖҡеёёз”ЁдәҺжӯЈзЎ®и®ӯз»ғжЁЎеһӢзҡ„иЎҢж•° гҖӮ дҪҶжҳҜ пјҢ еҮәдәҺеӯҰд№ зӣ®зҡ„ пјҢ жҲ‘们еҸҜд»ҘдҪҝз”ЁиЎҢж•°иҫғе°‘зҡ„ж•°жҚ®йӣҶ гҖӮ
зҺ°еңЁи®©жҲ‘们ж·ұе…Ҙз ”з©¶и§ЈеҶіжӯӨжңәеҷЁеӯҰд№ й—®йўҳвҖҰ
жӯҘйӘӨ1пјҡиҜҶеҲ«зӣ®ж Үе’ҢзӢ¬з«Ӣзү№еҫҒ
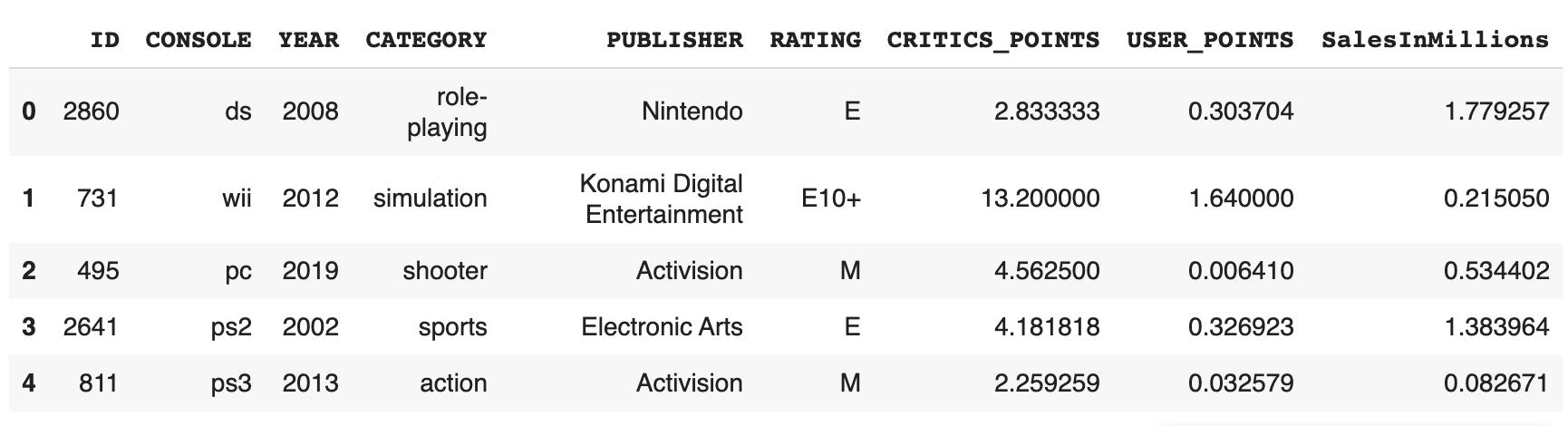
йҰ–е…Ҳ пјҢ и®©жҲ‘们е°ҶTrain.csvеҜје…Ҙpandasж•°жҚ®жЎҶдёӯ пјҢ 然еҗҺиҝҗиЎҢdf.head()д»ҘжҹҘзңӢж•°жҚ®йӣҶдёӯзҡ„еҲ— гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫд»Һж•°жҚ®жЎҶдёӯ пјҢ жҲ‘们еҸҜд»ҘзңӢеҲ°зӣ®ж ҮеҲ—жҳҜSalesInMillions пјҢ е…¶дҪҷеҲ—жҳҜзӢ¬з«Ӣзү№еҫҒ
жӯҘйӘӨ2пјҡжё…зҗҶиө„ж–ҷйӣҶ
йҰ–е…Ҳ пјҢ жҲ‘们йҖҡиҝҮиҝҗиЎҢinput.isnull().sum()е‘Ҫд»ӨжЈҖжҹҘnullеҖј гҖӮ
input.isnull().sum()#Output:ID0CONSOLE0YEAR0CATEGORY0PUBLISHER0RATING0CRITICS_POINTS0USER_POINTS0SalesInMillions0dtype: int64жҲ‘们еҸҜд»ҘзңӢеҲ°ж•°жҚ®йӣҶдёӯжІЎжңүз©әеҖј гҖӮ жҺҘдёӢжқҘ пјҢ жҲ‘们еҸҜд»ҘйҖҡиҝҮиҝҗиЎҢд»ҘдёӢе‘Ҫд»ӨеҲ йҷӨдёҚеҝ…иҰҒзҡ„еҲ—ID пјҢ еӣ дёәе®ғеңЁзӣ®ж Үй”Җе”®дёӯдёҚиө·дҪңз”Ёпјҡinput = input.drop(columns=['ID'])жҺҘдёӢжқҘ пјҢ жҲ‘们еҸҜд»ҘдҪҝз”Ёtrain_test_splitе‘Ҫд»Өе°Ҷж•°жҚ®жЎҶеҲҶдёәи®ӯз»ғе’ҢжөӢиҜ•ж•°жҚ®йӣҶпјҡ
train, test = train_test_split(input, test_size=0.2, random_state=42, shuffle=True)жӯҘйӘӨ3пјҡжҺўзҙўжҖ§ж•°жҚ®еҲҶжһҗжҸҸиҝ°жҖ§з»ҹи®ЎдҝЎжҒҜ
дҪҝз”Ёdf.shapeе‘Ҫд»ӨжҲ‘们еҸҜд»ҘжүҫеҲ°ж•°жҚ®йӣҶдёӯзҡ„жҖ»иЎҢж•° пјҢ 并且еҸҜд»ҘдҪҝз”Ёе‘Ҫд»Өdf.nunique()еңЁжҜҸдёӘеҲ—дёӯжҹҘжүҫе”ҜдёҖеҖј гҖӮ
CONSOLE17YEAR23CATEGORY12PUBLISHER184RATING6CRITICS_POINTS1499USER_POINTS1877SalesInMillions2804еңЁEDAйғЁеҲҶдёӯ пјҢ жҲ‘们дҪҝз”Ёpandas profilingе’ҢmatplotlibеҢ…з”ҹжҲҗеҗ„з§ҚеҲ—зҡ„еӣҫеҪў пјҢ 并и§ӮеҜҹе®ғ们дёҺзӣ®ж ҮеҲ—зҡ„е…ізі» гҖӮд»ҺEDAиҺ·еҫ—зҡ„дёҖдәӣи§Ғи§ЈжҳҜпјҡ
жҺЁиҚҗйҳ…иҜ»

















- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- е”җеұұеӣӣз»ҙжҷәиғҪ科жҠҖжңүйҷҗе…¬еҸёпјҡеҸҢиҮӮжңәеҷЁдәәеј•йўҶдәәжңәеҚҸдҪңж–°зәӘе…ғ
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- еӨ§дј—еұ•зӨәEVе…¬е…ұе……з”өж–°и§ЈеҶіж–№жЎҲпјҡ移еҠЁе……з”өжңәеҷЁдәә
- жҷ®жёЎжңәеҷЁдәәиҺ·жңҖдҪіе•Ҷз”ЁжңҚеҠЎжңәеҷЁдәәеҘ–
- зҝ»иҜ‘|жңәеҷЁзҝ»иҜ‘иғҪиҫҫ60дёӘиҜӯз§Қ3000дёӘж–№еҗ‘пјҢиҝ‘ж—ҘеҸҲеӨәе…Ёзҗғдә”еҶ пјҢиҝҷ家зүӣдјҒжҳҜи°Ғпјҹ
- еҒҮжңҹејҜйҒ“и¶…иҪҰ еӣҪзҫҺеӯҰд№ вҖңзҘһеҷЁвҖқеҠ©еӯ©еӯҗеҸҳиә«вҖңеӯҰйңёвҖқ
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘