дёәе•ҘеңЁиҜҙиҜқдәәиҜҶеҲ«жҠҖжңҜдёӯпјҢi-vectorеҸ–д»ЈдәҶJFA
иҝҷжҳҜдёҖдёӘеҫҲжңүеҗҜеҸ‘зҡ„й—®йўҳ~дёәдәҶжҗһжҮӮиҝҷдёӘвҖңдёәд»Җд№ҲвҖқпјҢзңӢдәҶеҘҪдёҖдәӣKennyзҡ„paperпјҢдҪҶдёҚиғҪиҜҙжүҫеҲ°дәҶзЎ®еҲҮзҡ„зӯ”жЎҲпјҢжүҖд»ҘеҗҺйқўдјҡжңүдёҖдәӣжҲ‘зҡ„зҢңжғіе’ҢеҒҮи®ҫвҖҰжғізҗҶи§ЈйЎ¶зә§еӨ§еёҲзҡ„жғіжі•пјҢжҲ‘зңҹзҡ„еҸӘиғҪйқ зҢңдәҶе•ҠQAQвҖҰвҖҰ
йҰ–е…ҲпјҢй—®йўҳжҳҜJFAдёәд»Җд№ҲиҰҒз®ҖеҢ–пјҹд»ҺеҺҹжңүзҡ„speaker factorе’Ңchannel factorз®ҖеҢ–дёәеҸӘжңүдёҖдёӘtotal factorпјҢд№ҹе°ұжҳҜзҺ°еңЁй—»еҗҚзҡ„i-vectorпјҢиҝҷдёӘз®ҖеҢ–зҡ„ж“ҚдҪңжҳҜеҮәиҮӘд»Җд№ҲйҒ“зҗҶе‘ўпјҹ
жҲ‘们е…ҲеӣһйЎҫJFAзҡ„е…¬ејҸпјҡ
1гҖҒMжҳҜ MжҳҜеҫ…иҜҶеҲ«зҡ„еҸҘеӯҗпјҢеқҮеҖјй«ҳж–Ҝи¶…зҹўйҮҸGSVпјҢе®ғжҳҜеҹәдәҺUBMжЁЎеһӢпјҢз”ЁжңҖеӨ§еҗҺйӘҢжҰӮзҺҮMAPеҺ»иҮӘйҖӮеә”еҪ“еүҚеҸҘеӯҗиҖҢдә§з”ҹзҡ„GMMжЁЎеһӢпјӣеҶҚжҠҠGMMжЁЎеһӢжҜҸдёӘй«ҳж–ҜеҲҶйҮҸзҡ„еқҮеҖјзҹўйҮҸпјҢдёІжҺҘиө·жқҘпјҢе°ұеҫ—еҲ°дәҶM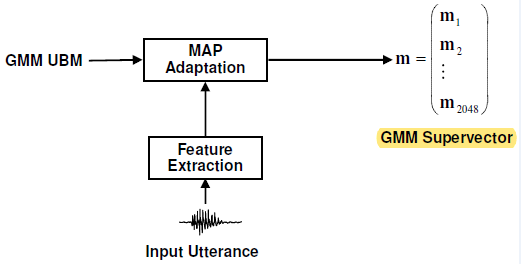
2гҖҒmжҳҜUBMзҡ„еқҮеҖји¶…зҹўйҮҸпјҢиҝҷе°ұжҳҜдёҖдёӘдёҺиҜҙиҜқдәәе’ҢдҝЎйҒ“йғҪж— е…ізҡ„йғЁеҲҶпјҢеҸҜд»ҘзңӢдҪңдёәжҳҜдёҖдёӘеҹәеә•пјӣ
3гҖҒVе’ҢDйғҪдёҺиҜҙиҜқдәәзӣёе…іпјӣ
гҖҗдёәе•ҘеңЁиҜҙиҜқдәәиҜҶеҲ«жҠҖжңҜдёӯпјҢi-vectorеҸ–д»ЈдәҶJFAгҖ‘ 4гҖҒVжҳҜиҜҙиҜқдәәз©әй—ҙзҡ„жң¬еҫҒйҹізҹ©йҳөeigenvoice matrixпјҢз”ЁдәҺжҸҸиҝ°иҜҙиҜқдәәзҡ„з©әй—ҙпјӣ
5гҖҒDжҳҜж®Ӣе·®еҜ№и§’зҹ©йҳөпјҢе’Ңzз»“еҗҲпјҢDzжҸҸиҝ°жҜҸеҸҘuttжүҖзү№жңүзҡ„дёҖдәӣж®Ӣе·®е’ҢеҷӘеЈ°(йҖҡеёёжҲ‘们дјҡеҝҪз•ҘжҺү)пјӣ
6гҖҒUжҳҜдҝЎйҒ“з©әй—ҙзҡ„жң¬еҫҒдҝЎйҒ“зҹ©йҳөпјӣ
7гҖҒyгҖҒxе’ҢzжҳҜ他们еҗ„иҮӘеҜ№еә”з©әй—ҙзҡ„еӣ еӯҗfactorпјҢйғҪжҳҜжңҚд»ҺN(0, I)еҲҶеёғзҡ„йҡҸжңәзҹўйҮҸпјӣ
然еҗҺпјҢJFAеҸҜд»ҘзңӢжҲҗиҝҷж ·еӯҗпјҡ
жҲ‘们еҫҲеҘҪзҗҶи§ЈпјҢJFAи®ҫи®Ўзҡ„еҲқиЎ·пјҢжҳҜ移йҷӨиҜҙиҜқдәәеқҮеҖји¶…зҹўйҮҸеңЁжң¬еҫҒдҝЎйҒ“з©әй—ҙзҡ„еҪұе“ҚпјҢи®© y е…·жңүеҫҲеҘҪзҡ„жҠ—дҝЎйҒ“еӨұй…ҚиғҪеҠӣпјӣдёәдәҶе®һзҺ°иҝҷдёӘзӣ®зҡ„пјҢKennyе°ұи®ҫжғіпјҢз”ЁxиҝҷдёӘдҝЎйҒ“еӣ еӯҗеҸӘеҜ№дҝЎйҒ“з©әй—ҙиҝӣиЎҢе»әжЁЎпјҢдҝғдҪҝyеҸӘе…·жңүиҜҙиҜқдәәзҡ„дҝЎжҒҜпјҢиҝҷе°ұе®ҢзҫҺжҸҗеҸ–дәҶиҜҙиҜқдәәиЎЁеҫҒ~~иҝҷдёӘideaз®ҖзӣҙPerfectпјҢеҫҲзҗҶжғі~~
дәҺжҳҜпјҢд»–е°ұжғіеҠһжі•з•Ңе®ҡејҖиҝҷдёӨдёӘз©әй—ҙпјҢе°ҪеҸҜиғҪи®© y зәҜзІ№еҢ…еҗ«иҜҙиҜқдҝЎжҒҜпјҢдәҺжҳҜд»–пјҲиҝҳжңүеҫҲеӨҡеҫҲеӨҡеӨ§зүӣпјүеҜ№и®Ўз®—JFAдёҠжҸҗеҮәдәҶдёӨдёӘж–№жі•пјҡ1гҖҒиҒ”еҗҲдј°и®Ўжі•пјӣ
2гҖҒзӢ¬з«Ӣдј°и®Ўжі•пјӣиҝҷдёӨдёӘж–№жі•дј°и®Ўзҡ„з»“жһңжҳҜзӣёиҝ‘зҡ„пјҢдёҚиҝҮеҜ№дәҺ第дёҖдёӘпјҢж—¶й—ҙе’Ңз©әй—ҙеӨҚжқӮеәҰйғҪзӣёеҪ“й«ҳпјҢйҖҡеёёеӨ§е®¶йғҪдјҡйҖүжӢ©еҗҺиҖ…жқҘи®Ўз®—JFAпјӣиҖҢеҗҺиҖ…пјҢжҳҜе…Ҳдј°и®ЎUпјҢеҶҚдј°и®ЎVпјҲиҝҷйҮҢе°ұжҳҜжҲ‘и®ӨдёәејҖе§ӢеҮәй—®йўҳзҡ„ең°ж–№пјүпјҢиҝҷж ·е°ұеҸҜд»Ҙз»ҷеҗҺйқўи®Ўз®—Vж—¶пјҢ移йҷӨдәҶдҝЎйҒ“з©әй—ҙзҡ„еҪұе“ҚпјҢиҝҷдёӘйЎәеәҸжҳҜдёәдәҶе°ҪеҸҜиғҪдҝқиҜҒVжҳҜе№ІеҮҖзҡ„пјӣ
иҖҢи®Ўз®—иҝҷдёӘUзҡ„иҝҮзЁӢпјҢжҳҜе…ҲеҜ№JFAиҝӣиЎҢз®ҖеҢ–пјҡ
s д»ЈиЎЁдәҶдёҺдҝЎйҒ“ж— е…ізҡ„иҜҙиҜқдәәеқҮеҖји¶…зҹўйҮҸпјҢжӯӨж—¶JFAйҖҖеҢ–дёәеҸӘеҜ№жң¬еҫҒдҝЎйҒ“зҡ„жЁЎеһӢеҒҮи®ҫпјӣдј°и®ЎUзҡ„иҝҮзЁӢе°ұжҳҜе…Ҳи®Ўз®—е……еҲҶз»ҹи®ЎйҮҸпјҢйӣ¶йҳ¶еҗҺйӘҢжҰӮзҺҮпјҢдёҖйҳ¶еҺ»UBMеҗҺзҡ„иҒ”еҗҲжҰӮзҺҮпјҢдәҢйҳ¶еҜ№и§’ж–№е·®зҹ©йҳөпјҢ然еҗҺдҪҝз”ЁEMйҮҚдј°и®ЎпјҢдј°и®Ўxзҡ„дёҖйҳ¶дёҺдәҢйҳ¶пјҢжӣҙж–°UпјҢд»ҘжӯӨеҸҚеӨҚ5-6ж¬Ўе°ұеҸҜд»Ҙи®Өдёә收ж•ӣдәҶпјӣ
дҪҶиҝҷдёӘ s еҸҲжҳҜеҰӮдҪ•еј„е‘ўпјҹжҲ‘еҜ№иҝҷйғЁеҲҶд№ҹзңӢдёҚз©ҝпјҢеӨ§жҰӮж–№жі•еҰӮдёӢпјҡ
е°ҶеҗҢдёҖиҜҙиҜқдәәеҗ„ж®өиҜӯйҹізҙҜеҠ пјҢ并дҪҝз”Ё MAPиҮӘйҖӮеә”пјҢжүҖеҫ—з»ҹи®ЎйҮҸеҮҸеҺ»дҝЎйҒ“еӣ зҙ еҫ—еҲ° sпјҡ
NжҳҜйӣ¶йҳ¶пјҢFжҳҜдёҖйҳ¶пјҢEжҳҜдј°и®Ўxзҡ„жңҹжңӣпјӣ
еҫ—еҲ°дәҶUд№ӢеҗҺпјҢе°ұжҳҜеҺ»дј°и®ЎVе’ҢyпјҢж–№жі•зұ»дјјпјӣжңҖеҗҺе°ұиғҪеҫ—еҲ°JFAзҡ„еҗ„дёӘеҸӮж•°еҖјпјҢеҫ…иҜҶеҲ«зҡ„uttиҪ¬еҢ–дёәGSVпјҢйҖҡиҝҮJFAи®Ўз®—еҜ№еә”зҡ„дҪҺз»ҙеӣәе®ҡз»ҙеәҰзҡ„иҜҙиҜқдәәеӣ еӯҗyпјӣеңЁз”Ёyз®—зӣёдјјжҖ§жұӮеҲҶж•°пјҢйӮЈж ·иҜҙиҜқдәәиҜҶеҲ«е°ұе®ҢжҲҗдәҶгҖӮ
дҪҶе®һйҷ…зңҹзҡ„жңүиҝҷд№Ҳperfectеҗ—пјҹпјҹе®һйҷ…зңҹзҡ„жңүиҝҷд№Ҳperfectеҗ—пјҹпјҹ
йҰ–е…ҲпјҢдҝЎйҒ“жқЎд»¶жң¬иә«жҳҜеҫҲйҡҫз”Ёж•°еӯҰе…¬ејҸжқҘжҳҺзЎ®з•Ңе®ҡе®ғпјӣиҝҷе°ұеҜјиҮҙпјҢзү№еҲ«жҳҜxиҝҷдёӘдҝЎйҒ“еӣ еӯҗпјҢеңЁеҜ№дҝЎйҒ“е»әжЁЎзҡ„еҗҢж—¶пјҢеҫҲжңүеҸҜиғҪxд№ҹеҢ…еҗ«дәҶиҜҙиҜқдәәдҝЎжҒҜпјҢиҝӣиҖҢжҠҠyзҡ„иҜҙиҜқдәәдҝЎжҒҜз»ҷеҲҶи–„дәҶгҖӮ


жҺЁиҚҗйҳ…иҜ»
















- дёәе•ҘзңӢеҲ°д№ҰжҹңдёҠзҡ„и—Ҹд№Ұдјҡжңүеҝғж—·зҘһжҖЎзҡ„ж„ҹи§ү
- дёәе•ҘзҹҘд№ҺдёҠжҷ®дҫҝжңүдёҖз§ҚгҖҗжҲ‘еңЁеҢ—дёҠе№ҝж·ұжү“е·ҘпјҢжүҖд»ҘжӢҘжңүжӣҙеҘҪзҡ„и§ҶйҮҺгҖ‘иҝҷж ·зҡ„й”ҷи§ү
- дёәе•Ҙе·Ҙе•Ҷ银иЎҢзҡ„з”ЁжҲ·дҪ“йӘҢеҰӮжӯӨд№Ӣе·®
- жұҪиҪҰ|зңӢдәҶдёӯж¶ҲеҚҸ4Sеә—жңҚеҠЎжөӢиҜ„и°ғжҹҘз»“жһңпјҢз»ҲдәҺзҹҘйҒ“жі•зі»иҪҰдёәе•ҘеҚ–дёҚеҘҪдәҶ
- дҪ дёәе•Ҙд»ҺзӘқзӘқе•ҶеҹҺзҰ»иҒҢ?
- дёәе•Ҙ5Gе’Ң2.4Gй»ҳи®Өзҡ„BSSIDжҳҜзӣёеҗҢзҡ„
- дёәе•Ҙз”өеҷЁе®һдҪ“еә—зҡ„д»·ж јжҜ”ж·ҳе®қиҙөйӮЈд№ҲеӨҡ
- зҺ°еңЁеңЁзәҝеӯҰд№ и§Ҷйў‘жңүеҫҲеӨҡдәҶпјҢдёәе•ҘеӨ§йғЁеҲҶдәәиҝҳжҳҜе–ңж¬ўдёӢиҪҪдёӢжқҘи§ӮзңӢ
- дёәе•ҘеҲ°зҺ°еңЁдҪ иҝҳжІЎжңүеҘіжңӢеҸӢ ?
- еӨ©иөҗзҡ„еЈ°йҹі|33еІҒеј йӣЁз»®дёәе•ҘжҖ»зҰ»е©ҡпјҹзңӢиҝҮиҝҷдәӣз…§зүҮе°ұжҳҺзҷҪдәҶпјҢйғҪжҳҜжҖ§ж„ҹжғ№еҫ—зҘё