дёәе•ҘеңЁиҜҙиҜқдәәиҜҶеҲ«жҠҖжңҜдёӯпјҢi-vectorеҸ–д»ЈдәҶJFA( дәҢ )
дёәдәҶйӘҢиҜҒпјҢеҒҮи®ҫдәҶи®©жң¬еҫҒдҝЎйҒ“зҹ©йҳөеҸӘеҜ№дҝЎйҒ“дҝЎжҒҜе»әжЁЎпјҢд»ҺиҖҢдҝЎйҒ“еӣ еӯҗеҪ“дё”д»…жңүдҝЎйҒ“дҝЎжҒҜпјҢдёҚеҗ«жңүиҜҙиҜқдәәдҝЎжҒҜпјӣеҰӮжһңиҝҷдёӘеҒҮи®ҫжҳҜжҲҗз«Ӣзҡ„пјҢйӮЈJFAеҰӮжһңеҸӘдҪҝз”Ё UxжқҘжү“еҲҶпјҢе°ұзҗҶеә”е…Ёй”ҷпјҢEER = 50%пјӣ
дҪҶе®һйҷ…зҡ„з»“жһңпјҡ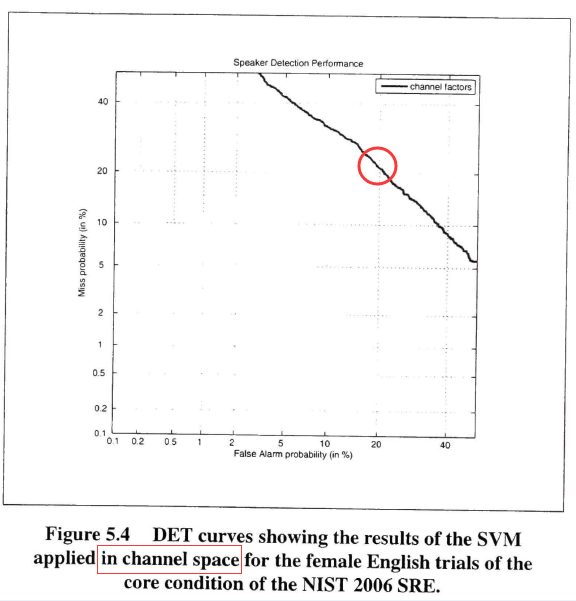
еңЁи®әж–ҮдёӯпјҢDehakе’ҢKennyе°ұеҒҡдәҶиҝҷдёӘз ”з©¶пјҢе®һйҷ…дёҠпјҢEERжҳҜжңү20%пјҢиҝҷе°ұиҜҙжҳҺдҝЎйҒ“еӣ еӯҗжҳҜеҢ…еҗ«дәҶиҜҙиҜқдәәдҝЎжҒҜгҖӮ
20%зҡ„EERпјҢиҝҷиҜҙиҜқдәәзҡ„дҝЎжҒҜйҮҸдёҖзӮ№йғҪдёҚе°‘пјҒи·қзҰ»50%еҸҜиҝңзқҖдәҶ~~дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢRestoring Lost Speaker Information from Channel FactorsпјҢKenny他们еҸҜиғҪжғіпјҲжҲ‘зҢңзҡ„пјү既然JFAиҝҷд№ҲзҗҶжғізҡ„жЁЎеһӢйғҪз•Ңе®ҡдёҚжё…пјҢйӮЈдёҚеҰӮжқҘдёҖдёӘ еҝ«еҲҖж–©д№ұйә»пјҢе…ҲжҠҠGSVиҪ¬еҢ–еҲ°дҪҺз»ҙйІҒжЈ’зҡ„зү№еҫҒпјҢжҠҠ移йҷӨдҝЎйҒ“еҪұе“Қзҡ„дәӢе„ҝжү”з»ҷеҗҺйқўеӨ„зҗҶеҗ§~~е“Ҳе“Ҳ~~зӣҙжҺҘжҠҠ Vе’ҢUеҗҲдәҢдёәдёҖпјҢжҠҠиҝҷдёӘж–°з©әй—ҙз§°д№Ӣдёәtotal variability spaceпјҢTзҹ©йҳөпјҢеҜ№еә”зҡ„еӣ еӯҗз§°д№Ӣдёәtotal factorпјҢд№ҹе°ұжҳҜi-vectorдәҶ~~дәҺжҳҜжҠҠJFAз®ҖеҢ–дёәпјҡ
д»ҺиҖҢi-vectorиҝҷдёӘжҰӮеҝөе°ұеңЁ2011е№ҙиҜһз”ҹдәҶпјӣзҺ°еңЁTзҹ©йҳөеҗҢж—¶еҜ№иҜҙиҜқдәәе’ҢдҝЎйҒ“дёӨдёӘз©әй—ҙе»әжЁЎпјҢwд№ҹдјҡеёҰжңүдҝЎйҒ“дҝЎжҒҜгҖӮдҪҶиҝҷиҝҳжІЎе®ҢпјҢ既然дҪ жҠҠ移йҷӨдҝЎйҒ“зҡ„еҪұе“ҚжҢӘеҲ°еҗҺйқўеӨ„зҗҶпјҢйӮЈеҗҺз»ӯеҪ“然иҰҒжӣҙеҠ еҒҡеҘҪi-vectorзҡ„ дҝЎйҒ“иЎҘеҒҝе·ҘдҪңдәҶгҖӮ
еңЁи®әж–ҮдёӯпјҢKennyе°ұдәӨд»ЈдәҶ3дёӘеӨ„зҗҶпјҡ
1гҖҒзұ»еҶ…еҚҸж–№е·®еҪ’дёҖеҢ–пјҢwithin-class covariance normalizationпјҢWCCNпјӣ2гҖҒзәҝжҖ§еҲӨеҲ«еҲҶжһҗпјҢlinear discriminant analysisпјҢLDAпјӣ3гҖҒжү°еҠЁеұһжҖ§жҠ•еҪұпјҢnuisance attribute projectionпјҢNAPпјӣ
еҗҺйқўиҝҳжңүжӣҙй—»еҗҚзҡ„пјҢPLDAпјҢд»Һдәәи„ёиҜҶеҲ«йӮЈиҫ№з§»жӨҚиҝҮжқҘзҡ„пјӣиҝҷдәӣз®—жі•йғҪжһҒеӨ§жҸҗеҚҮдәҶi-vectorзҡ„жҖ§иғҪгҖӮжҲ–и®ёдјҡжңүдәәжғій—®пјҢ既然жҸҗеҸ–еҮәжқҘзҡ„i-vectorиҝҳжҳҜжңүдҝЎйҒ“дҝЎжҒҜпјҢеҗҺз»ӯдҫқ然иҰҒеҒҡйўқеӨ–зҡ„еӨ„зҗҶпјҢйӮЈдёәе•ҘдёҚзӣҙжҺҘеҹәдәҺGSVеҒҡпјҹпјҹ
иҝҷдёӘй—®йўҳпјҢKennyжңүжҸҗеҲ°дәҶпјҡеҜ№i-vectorеҒҡдёҚеҜ№GSVеҒҡпјҢдё»иҰҒжҳҜеӣ дёәGSVз»ҙеәҰзӣёеҪ“й«ҳпјҢдјҡжңүдёҠдёҮз»ҙпјҲеҰӮжһңMFCCsжҳҜ39dпјҢй«ҳж–ҜеҲҶйҮҸдёә2048зҡ„иҜқпјҢGSVе°ұжңү39 * 2048 = 79,872пјүпјҢиҖҢi-vectorйҖҡеёёжҳҜ400-600пјҢиҝҷе°ұеӨ§еӨ§йҷҚдҪҺдәҶи®Ўз®—д»Јд»·пјӣ然еҗҺжҲ‘йўқеӨ–жғіеҲ°пјҢi-vectorжҳҜеҺ»жҺүдәҶйҖҡз”ЁйғЁеҲҶmзҡ„пјҢжүҖд»Ҙi-vectorзӣёжҜ”GSVеҸҜиғҪжӣҙе…·жңүеҸҜеҢәеҲҶжҖ§пјҹ
еҰӮжһңдёҠйқўжңүй”ҷQAQпјҢиҜ·зӣҙжҺҘжҲіжҲ‘пјҢжҜ•з«ҹжңүзҢңзҡ„вҖҰвҖҰеҸӮиҖғпјҡ Front-End Factor Analysis for Speaker Verification
Discriminative and generative approaches for long and shortterm speaker characteristics modeling application to speaker verification
SVM BASED SPEAKER VERIFICATION USING A GMM SUPERVECTOR KERNEL AND NAP VARIABILITY COMPENSATION иҒ”еҗҲеӣ еӯҗеҲҶжһҗдёӯзҡ„жң¬еҫҒдҝЎйҒ“з©әй—ҙжӢјжҺҘж–№жі•
в– зҪ‘еҸӢ
и°ўdalaoйӮҖгҖӮгҖӮгҖӮдҪҶжҳҜжҲ‘еҒҡCVгҖӮгҖӮгҖӮ
жҺЁиҚҗйҳ…иҜ»

















- дёәе•ҘзңӢеҲ°д№ҰжҹңдёҠзҡ„и—Ҹд№Ұдјҡжңүеҝғж—·зҘһжҖЎзҡ„ж„ҹи§ү
- дёәе•ҘзҹҘд№ҺдёҠжҷ®дҫҝжңүдёҖз§ҚгҖҗжҲ‘еңЁеҢ—дёҠе№ҝж·ұжү“е·ҘпјҢжүҖд»ҘжӢҘжңүжӣҙеҘҪзҡ„и§ҶйҮҺгҖ‘иҝҷж ·зҡ„й”ҷи§ү
- дёәе•Ҙе·Ҙе•Ҷ银иЎҢзҡ„з”ЁжҲ·дҪ“йӘҢеҰӮжӯӨд№Ӣе·®
- жұҪиҪҰ|зңӢдәҶдёӯж¶ҲеҚҸ4Sеә—жңҚеҠЎжөӢиҜ„и°ғжҹҘз»“жһңпјҢз»ҲдәҺзҹҘйҒ“жі•зі»иҪҰдёәе•ҘеҚ–дёҚеҘҪдәҶ
- дҪ дёәе•Ҙд»ҺзӘқзӘқе•ҶеҹҺзҰ»иҒҢ?
- дёәе•Ҙ5Gе’Ң2.4Gй»ҳи®Өзҡ„BSSIDжҳҜзӣёеҗҢзҡ„
- дёәе•Ҙз”өеҷЁе®һдҪ“еә—зҡ„д»·ж јжҜ”ж·ҳе®қиҙөйӮЈд№ҲеӨҡ
- зҺ°еңЁеңЁзәҝеӯҰд№ и§Ҷйў‘жңүеҫҲеӨҡдәҶпјҢдёәе•ҘеӨ§йғЁеҲҶдәәиҝҳжҳҜе–ңж¬ўдёӢиҪҪдёӢжқҘи§ӮзңӢ
- дёәе•ҘеҲ°зҺ°еңЁдҪ иҝҳжІЎжңүеҘіжңӢеҸӢ ?
- еӨ©иөҗзҡ„еЈ°йҹі|33еІҒеј йӣЁз»®дёәе•ҘжҖ»зҰ»е©ҡпјҹзңӢиҝҮиҝҷдәӣз…§зүҮе°ұжҳҺзҷҪдәҶпјҢйғҪжҳҜжҖ§ж„ҹжғ№еҫ—зҘё