еҪ“ж•°жҚ®еә“йҒҮдёҠ"иҮӘеҠЁй©ҫ驶"пјҢйҳҝйҮҢдә‘ DAS еңЁиҮӘжІ»иҜҠж–ӯзҡ„зӘҒз ҙ( еӣӣ )
3) ејӮеёёеәҸеҲ—иҒҡзұ»жЁЎеқ—(TOPIC)пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йҖҡиҝҮејӮеёёжҢҮж Үзҡ„зӣёдјјеәҰиҒҡзұ»е®ҢжҲҗiSQ1е’ҢiSQ2зҡ„зӣёдјјеәҰеҢ№й…Қ пјҢ еҰӮжһңдёӨдёӘiSQзҡ„зӣёдјјеәҰеҢ№й…ҚеҫҲй«ҳ пјҢ и®Өе®ҡдёәдёҖзұ»ејӮеёёеәҸеҲ—зӣёдјјеәҰз®—жі•SijиЎЁзӨәiSQ iдёҺiSQ jзҡ„зӣёдјјеәҰ пјҢTиЎЁзӨәжҢҮж Үзұ»еҲ« пјҢ |Kit,Kjt| иЎЁзӨәжҜҸдёӘжҢҮж Үд№Ӣй—ҙзҡ„зӣёдјјеәҰ пјҢ
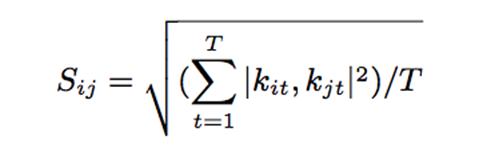 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
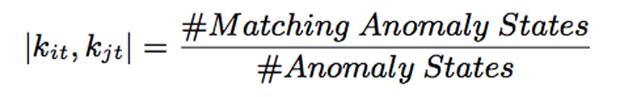 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
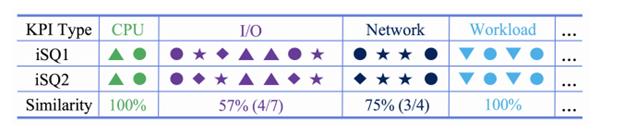
е…іиҒ”еҢ№й…Қзҡ„з®—жі•еҰӮдёӢ пјҢ йҖҡиҝҮKDTreeзҡ„еҠ йҖҹ пјҢ з»“еҗҲеұӮж¬ЎиҒҡзұ»е®ҢжҲҗеӨҡжҢҮж ҮејӮеёёеәҸеҲ—зҡ„зӣёдјјеәҰеҢ№й…Қ пјҢ зӣёдјјеәҰзҡ„йҳҲеҖјеҸӮж•°и°ғж•ҙеҸҜд»ҘеҹәдәҺжө·йҮҸж•°жҚ®еҲҶзұ»иҺ·еҫ— гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
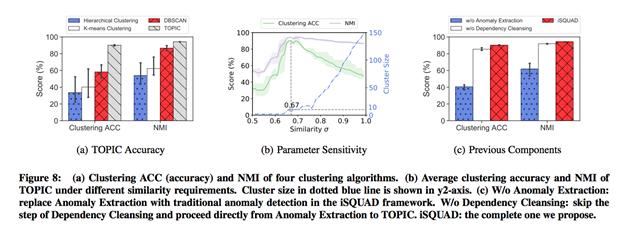
иҒҡзұ»ж–№жі•жҲ‘们еҗҢж—¶д№ҹиҝӣиЎҢдәҶеӨҡдёӘж–№жі•еҒҡдәҶеҜ№жҜ” пјҢ TopicиЎЁзҺ°иҫғеҘҪ гҖӮ еҗҢж—¶д№ҹеҜ№ејӮеёёжҠҪеҸ–жЁЎеқ— пјҢ е’Ңе…іиҒ”еҲҶжһҗжЁЎеқ—зҡ„дҪңз”ЁеҗҢж—¶еҒҡдәҶзӣёеә”зҡ„еҜ№жҜ”пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
4) иҙқеҸ¶ж–ҜжЎҲдҫӢжЁЎеһӢжЁЎеқ— BCM illustration
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
BCMдҪңдёәеҹәдәҺе®һдҫӢзҡ„ж–№жі•дё»иҰҒжҳҜйҖҡиҝҮдёҖдәӣд»ЈиЎЁжҖ§зҡ„ж ·жң¬жқҘи§ЈйҮҠиҒҡзұ»/еҲҶзұ»з»“жһңзҡ„ж–№жі• гҖӮ йҖҡиҝҮи§ӮеҜҹд»ЈиЎЁжҖ§зҡ„ж ·жң¬ пјҢ жҲ‘们еҸҜд»Ҙзӣҙи§Ӯеҫ—иҺ·еҫ—е…¶еҜ№еә”ж—Ҹзұ»зҡ„ж ·жң¬е®Ҹи§Ӯзү№еҫҒ гҖӮ йҖҡиҝҮTopicеҜ№ејӮеёёеәҸеҲ—зҡ„иҒҡзұ»дә§еҮәзҡ„з»“жһңиҝҳйңҖиҰҒеўһеҠ еәҸеҲ—зҡ„еҸҜи§ЈйҮҠжҖ§ пјҢ йҖҡиҝҮBCMиҝӣиЎҢзӣёе…іж•°жҚ®зҡ„ж•ҙеҗҲ пјҢ иҝӣиҖҢе°ҶејӮеёёеәҸеҲ—(Patterns)иҝӣиЎҢж•ҙеҗҲ гҖӮ
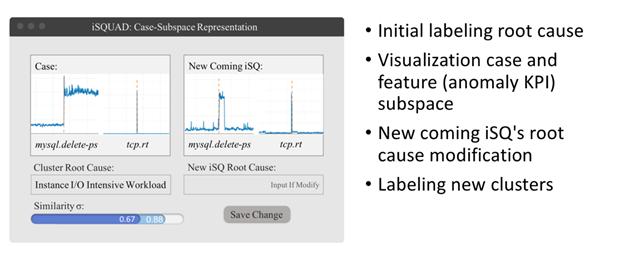
дёӢеӣҫжҳҜDBAж ҮжіЁж—¶еҖҷзҡ„жЎҲдҫӢ пјҢ йҖҡиҝҮж ҮжіЁеҺҶеҸІзҡ„жЎҲдҫӢ пјҢ жқҘеҜ№зҺ°жңүзҡ„iSQиҝӣиЎҢеҲӨе®ҡпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дҫӢеҰӮ mysql.cpu_usage +,mysql.select_ps+, mysql.qps+ ејӮеёё пјҢ BCMеҸҜд»ҘйҖҡиҝҮзӣёдјјжҢҮж ҮеәҸеҲ—дә§еҮә пјҢ CPUIntensiveWorkload, иҝҷж ·зҡ„иҒҡзұ»з»“жһң пјҢ еҪ“ејӮеёёеәҸеҲ—дёҚеңЁжҲ‘们已зҹҘиҒҡзұ»еәҸеҲ—йҮҢйқўж—¶ пјҢ йҖҡиҝҮDBAзҡ„ж ҮжіЁ пјҢ еҸҜд»Ҙж ҮжіЁеҮәжӣҙеӨҡзҡ„ејӮеёёеәҸеҲ— пјҢ жҲ‘们зҡ„еҗҺз«ҜжЎҲдҫӢеә“дјҡи¶ҠжқҘи¶Ҡдё°еҜҢ пјҢ иҒҡзұ»ж•Ҳжһңдјҡи¶ҠжқҘи¶ҠжҳҺжҳҫ пјҢ жҖ»еҲҶзұ»еҰӮдёӢеӣҫ
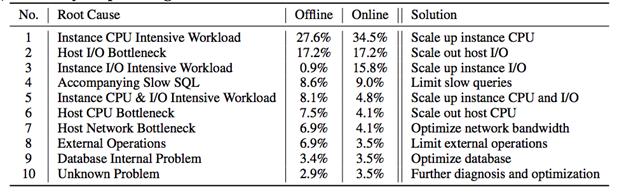
жҲ‘们жңҖз»Ҳе®һзҺ°дәҶд»Һж №еӣ еҲҶзұ»еҲ°Solutionзҡ„еҲқжӯҘжҳ е°„ пјҢ DASзҡ„еҶізӯ–дёӯеҝғдјҡж №жҚ®дёҚеҗҢж №еӣ е’Ңе…¶зҺ°иұЎзҡ„patterns пјҢ жқҘеҲҶеҸ‘иҮӘжІ»Actionж¶ҲжҒҜеҲ°еҗ„дёӘиҮӘжІ»дёҡеҠЎжЁЎеқ— пјҢ ж‘Ҷи„ұдәҶеҚ•зәҜдҫқйқ 规еҲҷй©ұеҠЁзҡ„ж–№ејҸ пјҢ йҖҡиҝҮж•°жҚ®еңЁеҗ„дёҡеҠЎеңәжҷҜзҡ„еҶ…еҫӘзҺҜ пјҢ жҲ‘们зҡ„жЁЎеһӢд№ҹеҗҢж—¶еңЁдёҚж–ӯжӣҙж–°е’Ңиҝӯд»Ј пјҢ еҪ“ж–°зҡ„ж №еӣ е’ҢеңәжҷҜеҮәзҺ°ж—¶ пјҢ жҲ‘们зҡ„еҲҶзұ»дјҡи¶ҠжқҘи¶Ҡз»Ҷ пјҢ еҗҢж—¶еҸҜд»ҘйҖӮеә”еӨҡз§ҚдёҡеҠЎеңәжҷҜе’ҢиҮӘжІ»еңәжҷҜзҡ„ж №еӣ е®ҡдҪҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
AutonomousDiagnose зҡ„е®һи·ө
жҲ‘们HAзҡ„SQLжҳҜдёҖдёӘжҜ”иҫғе…ёеһӢзҡ„еңәжҷҜ пјҢ жҲ‘们йҖҡеёёдҪҝз”ЁжҺўжҙ»SQLеҺ»жҺўжөӢж•°жҚ®еә“е®һдҫӢзҡ„еҝғи·іеҺ»дҝқиҜҒж•°жҚ®еә“зҡ„еҸҜз”ЁжҖ§ гҖӮ
дҪҶжҳҜеҪ“иҝҷдёӘжҺўжҙ»SQLеҸҳдёәiSQзҡ„ж—¶еҖҷ пјҢ ж•°жҚ®еә“йҖҡеёёдјҡеҮәзҺ°дёҘйҮҚжҪңеңЁзҡ„й—®йўҳ гҖӮ еҜ№дәҺж•°жҚ®еә“ж— еҫҒе…Ҷ"зӘҒ然жҢӮжҺү"зҡ„й—®йўҳ пјҢ жҲ‘们еҫҲйҡҫйҖҡиҝҮж•°жҚ®жқҘжҺЁз®—еҮәж—¶й—ҙ пјҢ HAйҖҡеёёйҖҡиҝҮжҺўжҙ»SQLжқҘи§ЈеҶі"зӘҒ然жҢӮжҺү"зҡ„й—®йўҳ пјҢ дҪҶжҳҜеңЁreviewйҳҝйҮҢйӣҶеӣўе’ҢйҳҝйҮҢдә‘еӨ§йҮҸзҡ„ж•…йҡңcaseеҗҺ пјҢ жҲ‘们еҫҖеҫҖеҫҲйҡҫеҸ–еҲӨж–ӯж•°жҚ®еә“"еҚҠжӯ»дёҚжҙ»"зҡ„еңәжҷҜ пјҢ еӣ дёәжҺўжҙ»RTзҡ„иҝһжҺҘиҝҳжҳҜеҸҜз”Ёзҡ„ пјҢ дҪҶжҳҜSQLзҡ„RTдјҡеҸҳж…ў пјҢ иҖҢдј з»ҹеҹәдәҺ规еҲҷзҡ„зӣ‘жҺ§ж—¶еҫҲйҡҫиғҪжЈҖжөӢеҮәиҝҷдёҖзұ»й—®йўҳзҡ„ пјҢ жҲ‘们иҝҷдёӨе№ҙзәҝдёҠеҫҲеӨҡж•…йҡңйғҪжҳҜиҝҷз§ҚзҺ°иұЎ пјҢ иҖҢдёҖзӣҙжІЎжңүеҫҲеҘҪзҡ„и§ЈеҶіеҠһжі• гҖӮ йҖҡиҝҮжҺўжҙ»SQLеҸҳдёәiSQзҡ„жЈҖжөӢ пјҢ жҲ‘们еҸҜд»Ҙз«ҷеңЁз”ЁжҲ·и§Ҷ角第дёҖж—¶й—ҙеҸ‘зҺ°SQLиҜ·жұӮеҸҳж…ўзҡ„зҺ°иұЎ пјҢ дёҖдёӘ"зӣ‘жҺ§жЈҖжөӢ"зҡ„й—®йўҳе°ұиҪ¬еҢ–жҲҗдәҶдёҖдёӘ"йў„жөӢжҖ§з»ҙжҠӨ"зҡ„й—®йўҳ, жҸҗеүҚеҸ‘зҺ°жҪңеңЁй—®йўҳ并е®ҡдҪҚж №еӣ еҸ‘иө·иҮӘжІ»action гҖӮ
жҺЁиҚҗйҳ…иҜ»













- дёәд»Җд№Ҳжңү"iphoneжҳҜз©·дәәжүӢжңә"зҡ„иЁҖи®әпјҹз”ЁдёҮе…ғжңәзҡ„дәәзңҹз©·еҗ—
- еҸҲзҲҶзӮёпјҒиҒ”з”ө科жҠҖдј жқҘдёҖеЈ°е·Ёе“ҚпјҢжҲ–жҠҠ8 иӢұеҜёжҷ¶еңҶеёӮеңә"зӮё"дәҶ
- йӣ·еҶӣеҶҚж¬Ўж”ҫеӨ§жӢӣпјҢе°Ҹзұі"иҪ»иЈ…дёҠйҳө"еҗҺпјҢеҚҺдёәиҝҳиғҪжүӣеҫ—дҪҸеҗ—пјҹ
- зҫҺеӣҪе…¬еҸёз ҙи§Ј"еҲ·и„ёж”Ҝд»ҳ"пјҹ用马дә‘з…§зүҮеҒҡе®һйӘҢпјҢз»“жһңеј№еҮә4дёӘеӨ§еӯ—
- иӢ№жһңж”№еҸҳз«Ӣеңә з§°macOSе®һз”ЁзЁӢеәҸAmphetamineеҸҜ继з»ӯз•ҷеңЁMacеә”з”Ёе•Ҷеә—дёӯ
- "дәҢе…«е®ҡеҫӢ"йҡҫз ҙ CPUеёӮеҚ зҺҮиӢұзү№е°”жҢҒз»ӯеҚ дјҳ
- з”ЁдәҶдёӨеҲ°дёүе№ҙзҡ„еҚҺдёәжүӢжңәпјҢдёҖй”®жү“ејҖ"ејҖеҸ‘иҖ…йҖүйЎ№"пјҢеё®еҠ©жҖ§иғҪеҠ йҖҹ
- AMP RoboticsеӢҹиө„5500дёҮзҫҺе…ғ ејҖеҸ‘AIеҜ№еҸҜеӣһ收зү©иҝӣиЎҢеҲҶжӢЈ
- 4575дёҮй«ҳеғҸзҙ &4Kй«ҳз”»иҙЁ е°јеә·Z7еҖјеҫ—йҖү
- жҜ«ж— 敬з•Ҹд№ӢеҝғпјҒеҚ—дә¬еӨ§еұ жқҖйҒҮйҡҫеҗҢиғһзәӘеҝөйҰҶиў«ж Ү"дј‘й—ІеЁұд№җеҘҪеҺ»еӨ„"пјҢзҫҺеӣўпјҡз«ӢеҚіж”№жӯЈ