еҪ“ж•°жҚ®еә“йҒҮдёҠ"иҮӘеҠЁй©ҫ驶"пјҢйҳҝйҮҢдә‘ DAS еңЁиҮӘжІ»иҜҠж–ӯзҡ„зӘҒз ҙ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
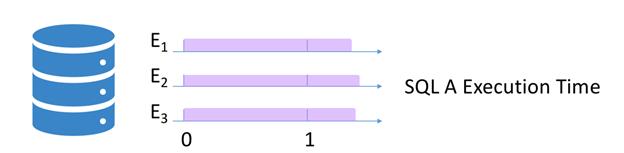
иҖҢеңЁдј—еӨҡж…ўSQLеҪ“дёӯ пјҢ жңүдёҖзұ»SQLзҡ„жү§иЎҢж—¶й—ҙжҜ”д»–еҺҶеҸІжү§иЎҢж—¶й—ҙиҰҒж…ўзҡ„еӨҡ пјҢ иҝҷж—¶еҖҷжҲ‘们е°ұеә”иҜҘеј•иө·жіЁж„ҸдәҶ пјҢ еҗҢж ·зҡ„SQLдёәд»Җд№Ҳдјҡжү§иЎҢеҸҳж…ўпјҹжҲ‘们еҸ‘зҺ°еҫҲеӨҡж•…йҡңзҡ„еүҚе…ҶйғҪдјҙйҡҸиҝҷз§ҚSQLзҡ„еҮәзҺ° пјҢ жүҖд»ҘжҲ‘们е°қиҜ•з»ҷиҝҷзұ»SQLдёӢдёҖдёӘз»ҹдёҖзҡ„е®ҡд№ү гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
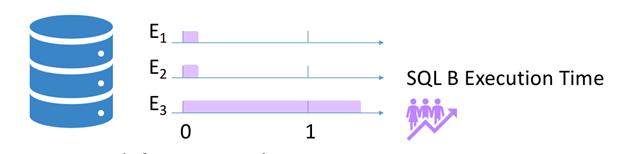
еӨ§йғЁеҲҶiSQйғҪдјҡеҪұе“Қз”ЁжҲ·дҪ“йӘҢ пјҢ з«ҷеңЁз”ЁжҲ·и§Ҷи§’ пјҢ 他们жң¬иә«жү§иЎҢзҡ„SQLзӘҒ然еҸҳж…ўдәҶ пјҢ з”ЁжҲ·жҳҜеҸҜд»Ҙж„ҹзҹҘеҲ°зҡ„ гҖӮ дҪҶжҳҜдёәд»Җд№ҲдёҚз”Ёе…¶д»–жҢҮж ҮеҸ–иЎЎйҮҸе‘ўпјҹ
Tcp-RTжҳҜдёҖдёӘдёҚй”ҷзҡ„жҢҮж Ү пјҢ д»–д№ҹеҸҜд»ҘеҸҚеә”жҹҘиҜўзҡ„RT пјҢ дҪҶжҳҜSQLжЁЎжқҝжҳҜз»ҶзІ’еәҰзҡ„жҢҮж Ү пјҢ иҖҢRTжҳҜе…ЁеұҖз»ҙеәҰзҡ„жҢҮж Ү пјҢ еҫҲеӨҡеңәжҷҜдёӢ пјҢ еҪ“з”ЁжҲ·QPSеҚҮй«ҳзҡ„ж—¶еҖҷ пјҢ Tcp-RTжҳҜдёӢйҷҚзҡ„пјӣжҹҗдәӣеңәжҷҜдёӢ пјҢ ж•ҙдҪ“RTжІЎжңүеҸҳж…ўиҖҢжҹҗзұ»SQLжЁЎжқҝжү§иЎҢеҸҳж…ўдәҶпјӣжүҖд»Ҙе…ЁеұҖз»ҙеәҰжҢҮж ҮеҫҖеҫҖжҳҜжңүеұҖйҷҗжҖ§зҡ„ пјҢ иҝҷе°ұжҳҜдёәд»Җд№ҲжҲ‘们йңҖиҰҒйҖҡиҝҮдёӢй’»иҝӣиЎҢж №еӣ е®ҡдҪҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
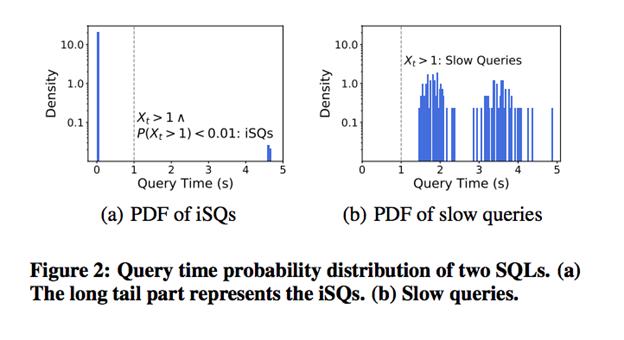
еӣ жӯӨ пјҢ еҜ№жҜ”ж…ўSQLзҡ„е®ҡд№ү пјҢ жҲ‘们з»ҷеҮәдәҶiSQзҡ„е®ҡд№ү пјҢ 并зӣёдҝЎйҖҡиҝҮiSQж–№ејҸзӯӣйҖүеҮәжқҘзҡ„SQLжӣҙиғҪдҪ“зҺ°еҮәж•°жҚ®еә“иҝҗиЎҢзҡ„зҠ¶жҖҒ гҖӮ йҖҡиҝҮSQLжү§иЎҢж—¶й—ҙ>1s,иҝҷдёӘ规еҲҷ并дёҚиғҪеё®еҠ©з”ЁжҲ·еҫҲеҘҪзҡ„зӯӣйҖүзңҹжӯЈзҡ„й—®йўҳSQL гҖӮ иҝҷйҮҢжҲ‘们йҖҡиҝҮжҰӮзҺҮзҡ„ж–№ејҸжҜ”иҫғз®ҖеҚ•дәҶе®ҡд№үдәҶiSQ пјҢ еҪ“然жҲ‘们жңӘжқҘд№ҹдјҡж №жҚ®SQLжү§иЎҢзҡ„жӣҙеӨҡзү№еҫҒ пјҢ еҖҹеҠ©жӣҙеӨҡ"ж•°жҚ®й©ұеҠЁ"зҡ„ж–№ејҸзӯӣйҖүеҮәiSQ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
Autonomous Diagnose
еӣ жӯӨжҲ‘们жүҫеҲ°дәҶдёҖдёӘж №еӣ е®ҡдҪҚзҡ„дёҖдёӘеҲҮе…ҘзӮ№ пјҢ йҖҡиҝҮжүҫеҲ°iSQдә§з”ҹзҡ„ж №еӣ жқҘиҜҠж–ӯж•°жҚ®еә“зҡ„жҖ§иғҪй—®йўҳ гҖӮ жҲ‘们еҸ‘зҺ°дј з»ҹж…ўSQLзҡ„е®ҡд№үжҳҜйҖҡиҝҮйҳҲеҖјжқҘе®ҡд№үзҡ„ пјҢ иҝҷз§Қ规еҲҷй©ұеҠЁзҡ„ж–№ејҸ并дёҚиғҪеҫҲеҘҪзҡ„её®еҠ©з”ЁжҲ·зј©е°Ҹе…ЁйҮҸSQLзҡ„иҢғеӣҙ пјҢ жҲ‘们еҸ‘зҺ°еҪ“ж•°жҚ®еә“еҮәзҺ°жҜ”иҫғйҳ»еЎһ пјҢ еҜҶйӣҶеһӢWorkload пјҢ й”Ғй—®йўҳзҡ„ж—¶еҖҷ пјҢ еёёеёёдјҡеҮәзҺ°iSQ(iSQ Intermittent Slow Queries пјҢ дә‘ж•°жҚ®еә“еҸ‘з”ҹж•…йҡңзҡ„ж—¶еҖҷ пјҢ iSQеҫҖеҫҖдјҡжҸҗеүҚеҮәзҺ° пјҢ з”ұдәҺiSQеңЁе…¶д»–ж—¶й—ҙж®өеҶ…жү§иЎҢж—¶й—ҙ并дёҚж…ў пјҢ SQLзҡ„жү§иЎҢж—¶й—ҙиҝ”еӣһзӘҒ然еўһй•ҝдјҡеҜјиҮҙдёҡеҠЎзҡ„е·ЁеӨ§еҸҳеҢ–,жҲ–иҖ…жҳҜз”ұдәҺдёҡеҠЎеҸҳеҢ–еҸ—еҪұе“Қзҡ„пјүйҖҡиҝҮеҜ№дәҺiSQзҡ„ж №еӣ е®ҡдҪҚ пјҢ жҲ‘们еҸҜд»ҘеҜ№ж•°жҚ®еә“еёёз”Ёзҡ„ж•…йҡңиҝӣиЎҢи·ҹз»ҶзІ’еәҰзҡ„ж №еӣ е®ҡдҪҚ пјҢ еҸӘжңүе°Ҷж•°жҚ®еә“зҡ„зҺ°иұЎиҝӣиЎҢеҲҶзұ» пјҢ жҲ‘们еҗҺйқўзҡ„иҮӘдҝ®еӨҚ/иҮӘдјҳеҢ–ActionsжүҚеҸҜд»ҘеҮҸе°‘actionжү§иЎҢзҡ„еҶІзӘҒ пјҢ еҗҲзҗҶзҡ„scheduleжҲ‘们зҡ„иҮӘжІ»action пјҢ жңүж•Ҳзҡ„з»ҷз”ЁжҲ·жҸҗдҫӣеҗҲзҗҶзҡ„иҮӘжІ»е»ә议并еҸ‘еҮәиҮӘжІ»action пјҢ еҪўжҲҗй—ӯзҺҜ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҢ‘жҲҳ
Anomaly Diversity
еңЁдёҺDBAжҺ’жҹҘй—®йўҳзҡ„иҝҮзЁӢдёӯ пјҢ жҲ‘们еҸ‘зҺ°жҺ’жҹҘй—®йўҳ пјҢ DBAеҫҖеҫҖиҰҒжөҸи§Ҳи¶…иҝҮ20дёӘжҢҮж Ү пјҢ йҖҡиҝҮзӣ‘жҺ§йЎөйқўзҡ„еҜ№жҜ” пјҢ д»ҘеҸҠеӨҡжҢҮж Үзҡ„ж—¶еәҸзү№еҫҒжқҘзЎ®е®ҡеӨ§иҮҙзҡ„еҺҹеӣ гҖӮ дҫӢеҰӮе°–еҲә/еқҮеҖјжјӮ移жҳҜDBAжңҖе…іжіЁзҡ„зү№еҫҒ пјҢ еҪ“然дҫӢеҰӮе‘ЁжңҹжҖ§е’Ңи¶ӢеҠҝзәҝзҡ„зү№еҫҒд№ҹжҳҜDBAе…іжіЁзҡ„ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
Labeling Overheads
DBA еңЁж ҮжіЁcaseзҡ„ж—¶еҖҷиҰҒиҠұеӨ§йҮҸзҡ„ж—¶й—ҙ пјҢ иҖҢж ҮжіЁеҫҖеҫҖжҳҜcase by case пјҢ жүҖд»ҘжҲ‘们caseзҡ„жІүж·ҖеҫҖеҫҖжҳҜйҖҡиҝҮж•…йҡңж–ҮжЎЈжҲ–иҖ…е·ҘеҚ• пјҢ жүҖд»ҘжҲ‘们жғіеҲ°еҮ дёӘзӘҒз ҙзӮ№пјҡ
- жҳҜеҗҰеҸҜд»ҘйҖҡиҝҮжЁЎеһӢжқҘжІүж·ҖжҲ‘们зҡ„case пјҢ йҖҡиҝҮеӨ§йҮҸзҡ„ж•…йҡңcaseжқҘжІүж·ҖжҲ‘们зҡ„з®—жі•жЁЎеһӢ пјҢ йҖҡиҝҮж•°жҚ®й©ұеҠЁзҡ„ж–№ејҸжқҘеҲ’еҲҶжҲ‘们зҡ„ж №еӣ еҲҶзұ»пјҹ
- жҳҜеҗҰеҸҜд»ҘеҮҸе°‘DBAеңЁж ҮжіЁиҝҮзЁӢдёӯзҡ„ж ҮжіЁж—¶й—ҙпјҹ
жЁЎеһӢзҡ„еҸҜи§ЈйҮҠжҖ§жҳҜжҲ‘们йңҖиҰҒе…іжіЁзҡ„ пјҢ дёҚеҗҢзҺ°иұЎеҜ№еә”иҝҷдёҚеҗҢж №еӣ пјҢ еҰӮдҪ•е№іиЎЎж №еӣ е®ҡдҪҚеҮҶзЎ®зҺҮдёҺж №еӣ е®ҡдҪҚеҸҜи§ЈйҮҠжҖ§д№ҹжҳҜжҲ‘们йңҖиҰҒе…іжіЁзҡ„ гҖӮ
жҺЁиҚҗйҳ…иҜ»













- дёәд»Җд№Ҳжңү"iphoneжҳҜз©·дәәжүӢжңә"зҡ„иЁҖи®әпјҹз”ЁдёҮе…ғжңәзҡ„дәәзңҹз©·еҗ—
- еҸҲзҲҶзӮёпјҒиҒ”з”ө科жҠҖдј жқҘдёҖеЈ°е·Ёе“ҚпјҢжҲ–жҠҠ8 иӢұеҜёжҷ¶еңҶеёӮеңә"зӮё"дәҶ
- йӣ·еҶӣеҶҚж¬Ўж”ҫеӨ§жӢӣпјҢе°Ҹзұі"иҪ»иЈ…дёҠйҳө"еҗҺпјҢеҚҺдёәиҝҳиғҪжүӣеҫ—дҪҸеҗ—пјҹ
- зҫҺеӣҪе…¬еҸёз ҙи§Ј"еҲ·и„ёж”Ҝд»ҳ"пјҹ用马дә‘з…§зүҮеҒҡе®һйӘҢпјҢз»“жһңеј№еҮә4дёӘеӨ§еӯ—
- иӢ№жһңж”№еҸҳз«Ӣеңә з§°macOSе®һз”ЁзЁӢеәҸAmphetamineеҸҜ继з»ӯз•ҷеңЁMacеә”з”Ёе•Ҷеә—дёӯ
- "дәҢе…«е®ҡеҫӢ"йҡҫз ҙ CPUеёӮеҚ зҺҮиӢұзү№е°”жҢҒз»ӯеҚ дјҳ
- з”ЁдәҶдёӨеҲ°дёүе№ҙзҡ„еҚҺдёәжүӢжңәпјҢдёҖй”®жү“ејҖ"ејҖеҸ‘иҖ…йҖүйЎ№"пјҢеё®еҠ©жҖ§иғҪеҠ йҖҹ
- AMP RoboticsеӢҹиө„5500дёҮзҫҺе…ғ ејҖеҸ‘AIеҜ№еҸҜеӣһ收зү©иҝӣиЎҢеҲҶжӢЈ
- 4575дёҮй«ҳеғҸзҙ &4Kй«ҳз”»иҙЁ е°јеә·Z7еҖјеҫ—йҖү
- жҜ«ж— 敬з•Ҹд№ӢеҝғпјҒеҚ—дә¬еӨ§еұ жқҖйҒҮйҡҫеҗҢиғһзәӘеҝөйҰҶиў«ж Ү"дј‘й—ІеЁұд№җеҘҪеҺ»еӨ„"пјҢзҫҺеӣўпјҡз«ӢеҚіж”№жӯЈ