еҪ“ж•°жҚ®еә“йҒҮдёҠ"иҮӘеҠЁй©ҫ驶"пјҢйҳҝйҮҢдә‘ DAS еңЁиҮӘжІ»иҜҠж–ӯзҡ„зӘҒз ҙ( дёү )
Large-scale
д»ҺйӣҶеӣўеҲ°йҳҝйҮҢдә‘ пјҢ жҲ‘们管жҺ§зҡ„е®һдҫӢж•°д»ҺеҮ дёҮеҲ°и¶…иҝҮ50дёҮе®һдҫӢ пјҢ жҲ‘们еҜ№зҰ»зәҝи®Ўз®—й“ҫи·ҜдёҺе®һж—¶и®Ўз®—й“ҫи·Ҝжңүе·ЁеӨ§зҡ„жҢ‘жҲҳ пјҢ иҝҷйҮҢжҲ‘们жҠҠз®—жі•йғЁзҪІеҲ°жҲ‘们DASMindз®—жі•жңҚеҠЎ пјҢ еә•еұӮеҖҹеҠ©дёҺеҮҪж•°и®Ўз®—зҡ„еј№жҖ§жү©еұ•иғҪеҠӣ пјҢ жңҖеӨ§зЁӢеәҰзҡ„иҠӮзңҒиө„жәҗе’ҢдҝқйҡңжҲ‘们жөҒи®Ўз®—зҡ„зЁіе®ҡжҖ§ гҖӮ
Multiple Database Engines
жҲ‘们зӣ®еүҚе·Із»Ҹж”ҜжҢҒMySQL/PolarDB зӯүе…ізі»еһӢж•°жҚ®еә“ пјҢ д№ҹиҰҒж”ҜжҢҒRedis/Mongo зӯүNoSQLж•°жҚ®еә“ пјҢ жҲ‘们еёҢжңӣйҖҡиҝҮдёҖдёӘе…·жңүйІҒжЈ’жҖ§зҡ„ж–№ејҸ пјҢ жқҘжІүж·ҖDBAзҡ„з»ҸйӘҢ пјҢ иҖҢдёҚжҳҜй’ҲеҜ№жҜҸдёҖдёӘж•°жҚ®еә“еҚ•зӢ¬и®ҫи®ЎдёҖеҘ—规еҲҷејҸзҡ„ж №еӣ е®ҡдҪҚж–№жі• пјҢ е°ҪеҸҜиғҪзҡ„йҷҚдҪҺжҲ‘们跨引ж“Һж ҮжіЁcaseжІүж·Җз»ҸйӘҢзҡ„жҲҗжң¬ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж–№жЎҲ
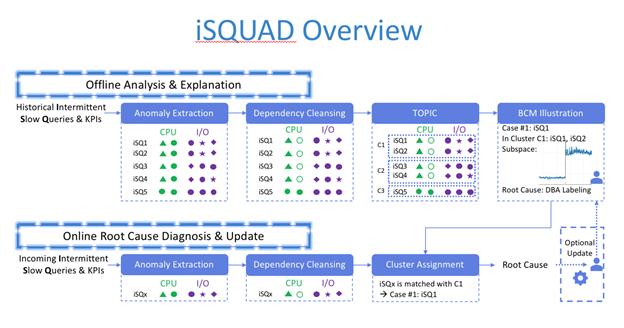
iSQUAD Overview
жҲ‘们и®ҫи®ЎдәҶiSQUADиҝҷеҘ—жЎҶжһ¶е№¶еөҢе…ҘеҲ°DASз®—жі•жңҚеҠЎDASMindеҪ“дёӯ пјҢ ж–№жЎҲеҲҶдёәзҰ»зәҝе’ҢеңЁзәҝдёӨжқЎй“ҫи·Ҝ гҖӮ
зҰ»зәҝпјҡйҖҡиҝҮеҜ№еҺҶеҸІiSQж•°жҚ®зҡ„жҺўжөӢ пјҢ жқҘи§ҰеҸ‘ејӮеёёжҠҪеҸ–жЁЎеқ— пјҢ жҠҪеҸ–ејӮеёёзҡ„зү№еҫҒ пјҢ еңЁйҖҡиҝҮиҝҮж»ӨйҮҚеӨҚжҢҮж Ү пјҢ е°ҶжҜҸдёӘiSQеҜ№еә”зҡ„patternиҝӣиЎҢиҒҡзұ» пјҢ иҺ·еҫ—дё°еҜҢзҡ„cluster пјҢ иҝҷдәӣclusterйҖҡиҝҮBCMжЁЎеқ—зҡ„зү№еҫҒеӯҗз©әй—ҙзҡ„жҠҪеҸ–еҗҺ пјҢ з”ЁжқҘз»ҷDBAиҝӣиЎҢж ҮжіЁ пјҢ ж ҮжіЁзҡ„ж ·жң¬жІүж·ҖеҮәpatternзҡ„жЁЎеһӢ пјҢ 并жҸҗдҫӣз»ҷеңЁзәҝе®һж—¶ж №еӣ е®ҡдҪҚжЁЎеқ—еҒҡеҲҶжһҗ пјҢ иҝҷж ·еңЁзәҝй“ҫи·Ҝд»Һд№ӢеүҚдәҶ1-5-10(1еҲҶй’ҹеҸ‘зҺ°ејӮеёё пјҢ 5еҲҶй’ҹе®ҡдҪҚеҲҶзұ» пјҢ 10еҲҶй’ҹеҸ‘еҮәaction)зҡ„ж–№ејҸеҫ—еҲ°дәҶеҚҮзә§ пјҢ жҲ‘们жҠҠејӮеёёеҸ‘зҺ°е’Ңж №еӣ е®ҡдҪҚеҲҶзұ»иҝҷ6еҲҶй’ҹж—¶й—ҙеҺӢзј©еҲ°дәҶ1еҲҶй’ҹд»ҘеҶ… пјҢ еҒҡеҲ°дәҶе®һж—¶ж №еӣ е®ҡдҪҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
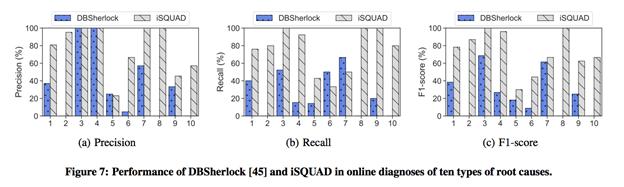
еҜ№дәҺж•ҙдҪ“iSQAUDзҡ„еңЁзәҝиҜҠж–ӯж•Ҳжһң пјҢ жҲ‘们еҜ№жҜ”дәҶSIGMOD 2016 Dbsherlock: A performancediagnostic tool for transactional databases гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жң¬ж–№жЎҲзі»з»ҹеӣҫ пјҢ еҲҶдёә4дёӘжЁЎеқ—пјҡ
1) ејӮеёёжЈҖжөӢжЁЎеқ—(Anomaly Extract)пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
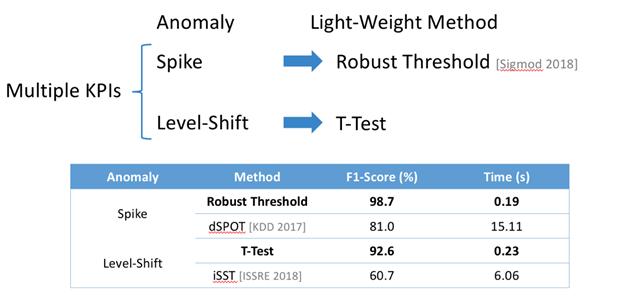
йҖҡиҝҮеҜ№еӨҡжҢҮж Үж—¶еәҸеәҸеҲ—ејӮеёёжЈҖжөӢ пјҢ йҖҡиҝҮ Robust Threshold йІҒжЈ’жҖ§зҡ„йҳҲеҖјйў„жөӢж–№жі• пјҢ з»“еҗҲж—¶еәҸеәҸеҲ—е‘ЁжңҹжҖ§зҡ„ж–№жі• пјҢ з”ҹжҲҗеҠЁжҖҒйҳҲеҖј пјҢ жқҘеҲӨе®ҡжҜҸдёӘжҢҮж Үзҡ„дёҠйҷҗиҫ№з•Ң пјҢ 并解жһҗеҮәзӣёеә”зү№еҫҒжҳҜеҗҰдёәspike/meanshift/,жӯӨж–№жі•еҜ№жҜ”T-Testзӯүдј з»ҹж–№жі•еҜ№жӣҙеҠ е®һз”Ёе’Ңеҝ«йҖҹзҡ„еҲӨж–ӯжҢҮж ҮжіўеҠЁж–№еҗ‘ пјҢ дёӢеӣҫдёҺдј з»ҹT-Testж–№жі•еҜ№жҜ”пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еңЁе®һйҷ…дёҡеҠЎеңәжҷҜдёӯ Robust Threshold пјҢ еҜ№дәҺзЁіе®ҡзҡ„ж—¶еәҸеәҸеҲ—еҸҜд»ҘеҫҲеҘҪжЈҖжөӢеҮәspike/meanshift зү№еҫҒ пјҢ дҪҶжҳҜдёҡеҠЎеңәжҷҜеҫҖеҫҖжҳҜеӨҚжқӮзҡ„ пјҢ еҜ№дәҺAdditive Model/Multiplicative Model/Weak-Seasonality, жҲ‘们DASдә§е“ҒйҮҮз”ЁжӣҙеҠ дё°еҜҢејӮеёёжЈҖжөӢз®—жі•еә“еҺ»иҜҶеҲ«еӨҡдёӘдёҚеҗҢзҡ„ж—¶еәҸзү№еҫҒ пјҢ е…ідәҺејӮеёёжЈҖжөӢзҡ„ж–№жі•е°ҶеңЁеҗҺз»ӯж–Үз« иҜҰз»Ҷеұ•ејҖ гҖӮ жң¬paperзқҖйҮҚеҜ№spikeе’Ңmeanshiftзү№еҫҒиҝӣиЎҢдәҶжЈҖжөӢ гҖӮ
2) е…іиҒ”еҲҶжһҗ, жҢҮж Үдҫқиө–е…ізі»иҝҮж»ӨжЁЎеқ—(Dependencies cleaning)пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
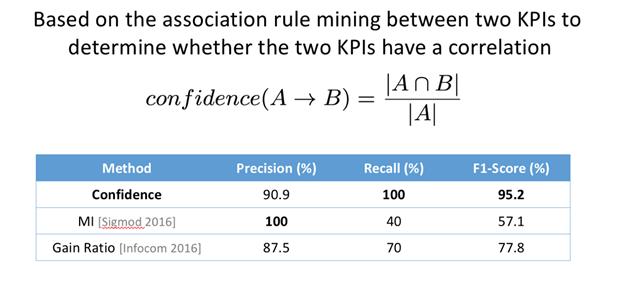
еӨҡжҢҮж ҮеӯҳеңЁдҫқиө– пјҢ йҖҡиҝҮеӨ§йҮҸеҺҶеҸІж•°жҚ®е…іиҒ”еҲҶжһҗ пјҢ жҠҠејӮеёёж–№еҗ‘жҖ»жҳҜжіўеҠЁзӣёеҗҢзҡ„жҢҮж Үжё…зҗҶжҺү пјҢ з•ҷдёӢе…ій”®жҢҮж Ү пјҢ еҜ№жҜ”DBAз»Ҹеёёе…іжіЁзҡ„жҢҮж Ү пјҢ жңүдёҖе®ҡзҡ„зӣёдјјжҖ§йҖҡиҝҮAејӮеёё/BејӮеёёзҡ„е…іиҒ”жҖ§жҺЁеҜјеҮә пјҢ ABдёӨдёӘжҢҮж ҮжҳҜеҗҰе…іиҒ” пјҢ жӯӨзұ»е…іиҒ”еҲҶжһҗж–№жі•з”ЁеҫҲеӨҡ пјҢ 并жңӘеҜ№жӯӨж–№жі•еҚ•зӢ¬е’Ңдј з»ҹж–№жі•дҪңеҜ№жҜ”пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»













- дёәд»Җд№Ҳжңү"iphoneжҳҜз©·дәәжүӢжңә"зҡ„иЁҖи®әпјҹз”ЁдёҮе…ғжңәзҡ„дәәзңҹз©·еҗ—
- еҸҲзҲҶзӮёпјҒиҒ”з”ө科жҠҖдј жқҘдёҖеЈ°е·Ёе“ҚпјҢжҲ–жҠҠ8 иӢұеҜёжҷ¶еңҶеёӮеңә"зӮё"дәҶ
- йӣ·еҶӣеҶҚж¬Ўж”ҫеӨ§жӢӣпјҢе°Ҹзұі"иҪ»иЈ…дёҠйҳө"еҗҺпјҢеҚҺдёәиҝҳиғҪжүӣеҫ—дҪҸеҗ—пјҹ
- зҫҺеӣҪе…¬еҸёз ҙи§Ј"еҲ·и„ёж”Ҝд»ҳ"пјҹ用马дә‘з…§зүҮеҒҡе®һйӘҢпјҢз»“жһңеј№еҮә4дёӘеӨ§еӯ—
- иӢ№жһңж”№еҸҳз«Ӣеңә з§°macOSе®һз”ЁзЁӢеәҸAmphetamineеҸҜ继з»ӯз•ҷеңЁMacеә”з”Ёе•Ҷеә—дёӯ
- "дәҢе…«е®ҡеҫӢ"йҡҫз ҙ CPUеёӮеҚ зҺҮиӢұзү№е°”жҢҒз»ӯеҚ дјҳ
- з”ЁдәҶдёӨеҲ°дёүе№ҙзҡ„еҚҺдёәжүӢжңәпјҢдёҖй”®жү“ејҖ"ејҖеҸ‘иҖ…йҖүйЎ№"пјҢеё®еҠ©жҖ§иғҪеҠ йҖҹ
- AMP RoboticsеӢҹиө„5500дёҮзҫҺе…ғ ејҖеҸ‘AIеҜ№еҸҜеӣһ收зү©иҝӣиЎҢеҲҶжӢЈ
- 4575дёҮй«ҳеғҸзҙ &4Kй«ҳз”»иҙЁ е°јеә·Z7еҖјеҫ—йҖү
- жҜ«ж— 敬з•Ҹд№ӢеҝғпјҒеҚ—дә¬еӨ§еұ жқҖйҒҮйҡҫеҗҢиғһзәӘеҝөйҰҶиў«ж Ү"дј‘й—ІеЁұд№җеҘҪеҺ»еӨ„"пјҢзҫҺеӣўпјҡз«ӢеҚіж”№жӯЈ