flinkж¶Ҳиҙ№kafkaзҡ„offsetдёҺcheckpoint
з”ҹдә§зҺҜеўғжңүдёӘдҪңдёҡ пјҢ йҖ»иҫ‘еҫҲз®ҖеҚ• пјҢ иҜ»еҸ–kafkaзҡ„ж•°жҚ® пјҢ 然еҗҺдҪҝз”Ёhive catalog пјҢ е®һж—¶еҶҷе…Ҙhbase пјҢ hive пјҢ redis гҖӮ дҪҝз”Ёзҡ„flinkзүҲжң¬дёә1.11.1 гҖӮ
дёәдәҶйҳІжӯўеҶҷе…Ҙhiveзҡ„ж–Ү件数йҮҸиҝҮеӨҡ пјҢ жҲ‘и®ҫзҪ®дәҶcheckpointдёә30еҲҶй’ҹ гҖӮ
env.enableCheckpointing(1000 * 60 * 30); // 1000 * 60 * 30 => 30 minutesиҫҫеҲ°зҡ„ж•Ҳжһңе°ұжҳҜжҜҸ30еҲҶй’ҹз”ҹжҲҗдёҖдёӘж–Ү件 пјҢ еҰӮдёӢпјҡ
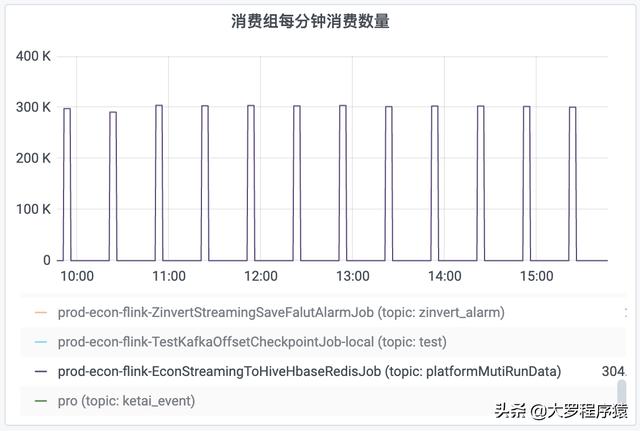
hive> dfs -ls /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/ ;Found 10 items-rw-r--r--3 hdfs hive0 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/_SUCCESS-rw-r--r--3 hdfs hive248895 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10911-rw-r--r--3 hdfs hive306900 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10912-rw-r--r--3 hdfs hive208227 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10913-rw-r--r--3 hdfs hive263586 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10911-rw-r--r--3 hdfs hive307723 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10912-rw-r--r--3 hdfs hive196777 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10913-rw-r--r--3 hdfs hive266984 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10911-rw-r--r--3 hdfs hive338992 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10912-rw-r--r--3 hdfs hive216655 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10913hive> дҪҶжҳҜ пјҢ еҗҢж—¶д№ҹи§ӮеҜҹеҲ°еҪ’еұһдәҺиҝҷдёӘдҪңдёҡзҡ„kafkaж¶Ҳиҙ№з»„з§ҜеҺӢж•°йҮҸ пјҢ жҜҸеҲҶй’ҹж¶Ҳиҙ№ж•°йҮҸ пјҢ жҳҺжҳҫе…·жңүе‘ЁжңҹжҖ§ж¶Ҳиҙ№еі°еҖј гҖӮ
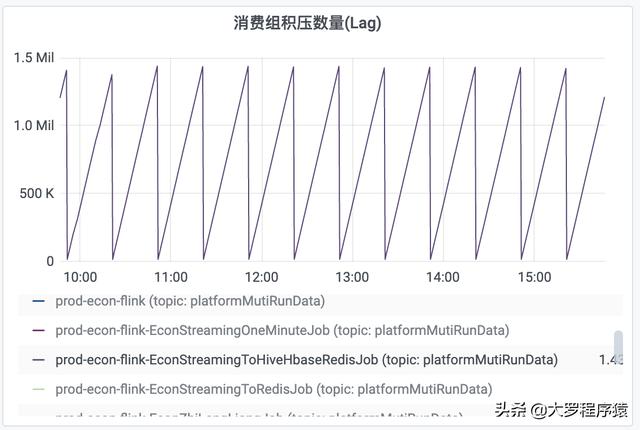
жҜ”еҰӮ пјҢ еҜ№дәҺжҜҸ30еҲҶй’ҹж—¶й—ҙй—ҙйҡ”еәҰзҡ„дёҖдёӘи§ӮеҜҹ пјҢ еүҚйқў25еҲҶй’ҹзҡ„вҖңжҜҸеҲҶй’ҹж¶Ҳиҙ№ж•°йҮҸвҖқйғҪжҳҜдёә0 пјҢ 然еҗҺ пјҢ еҗҺйқў5еҲҶй’ҹзҡ„вҖңжҜҸеҲҶй’ҹж¶Ҳиҙ№ж•°йҮҸвҖқдёә300k гҖӮ еҗҢзҗҶ пјҢ вҖңж¶Ҳиҙ№з»„з§ҜеҺӢж•°йҮҸвҖқд№ҹеҮәзҺ°еҗҢж ·жғ…еҶө пјҢ з§ҜеҺӢж•°йҮҸдёҖзӣҙйҖ’еўһ пјҢ дҪҶжҳҜеҲ°дәҶ30еҲҶй’ҹзҡ„й—ҙйҡ” пјҢ е°ұдёӢйҷҚеҲ°ж•°еҖј0 гҖӮ еҰӮеӣҫ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж¶Ҳиҙ№з»„жҜҸеҲҶй’ҹж¶Ҳиҙ№ж•°йҮҸ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
ж¶Ҳиҙ№з»„з§ҜеҺӢж•°йҮҸ
дҪҶе…¶е®һ пјҢ йҖҡиҝҮеҜ№hbase пјҢ hive пјҢ redisзҡ„и§ӮеҜҹ пјҢ ж•°жҚ®жҳҜе®һж—¶еҶҷе…Ҙзҡ„ пјҢ 并дёҚеӯҳеңЁеүҚйқў25еҲҶй’ҹжІЎжңүж¶Ҳиҙ№ж•°жҚ®зҡ„жғ…еҶө гҖӮ
жҹҘйҳ…иө„ж–ҷеҫ—зҹҘ пјҢ flinkдјҡиҮӘе·ұз»ҙжҠӨдёҖд»Ҫkafkaзҡ„offset пјҢ 然еҗҺcheckpointж—¶й—ҙзӮ№еҲ°дәҶ пјҢ еҶҚжҠҠoffsetжӣҙж–°еӣһkafka гҖӮ
дёәдәҶйӘҢиҜҒиҝҷдёӘи§ӮзӮ№ пјҢ вҖңflinkеңЁcheckpointзҡ„ж—¶еҖҷ пјҢ жүҚжҠҠж¶Ҳиҙ№kafkaзҡ„offsetжӣҙж–°еӣһkafkaвҖқ пјҢ еҗҢж—¶ пјҢ и§ӮеҜҹ пјҢ savepointжңәеҲ¶жҳҜеҗҰдјҡйҮҚеӨҚж¶Ҳиҙ№kafka пјҢ жҲ‘е°қиҜ•еҶҷдёҖдёӘзЁӢеәҸ пјҢ йҖ»иҫ‘еҫҲз®ҖеҚ• пјҢ е°ұжҳҜд»Һtopic "test"иҜ»еҸ–ж•°жҚ® пјҢ 然еҗҺеҶҷе…Ҙtopic "test2" гҖӮ зү№еҲ«иҜҙжҳҺ пјҢ иҝҷдёӘдҪңдёҡзҡ„checkpointжҳҜ1еҲҶй’ҹ гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- з ”з©¶з§°iPhone 12еӣҪиЎҢ128GBзү©ж–ҷжҲҗжң¬жҸҗй«ҳдәҶ21%пјҡиӢ№жһңеҠ еҖҚиҪ¬е«Ғз»ҷж¶Ҳиҙ№иҖ…
- з”ЁжҲ·|е…ғж—ҰеҪ“еӨ©иӢ№жһңеә”з”Ёж¶Ҳиҙ№йўқи¶…иҝҮ5.4дәҝзҫҺе…ғ еҲ·ж–°еҚ•ж—Ҙж¶Ҳиҙ№и®°еҪ•
- iPhoneзү©ж–ҷжҲҗжң¬жҸҗй«ҳдәҶ21%пјҡж¶Ҳиҙ№иҖ…д№°еҚ•
- зҙўе°јж¬Іе°Ҷж–°ж¬ҫ360 Reality Audioжү¬еЈ°еҷЁеёҰе…Ҙж¶Ҳиҙ№иҖ…家дёӯ
- е…Ёзңҹдә’иҒ”зҪ‘пјҢдә§дёҡдә’иҒ”зҪ‘е’Ңж¶Ҳиҙ№дә’иҒ”зҪ‘зҡ„иһҚеҗҲ
- ж¶Ҳиҙ№иҖ…жҠҘе‘Ҡ | зҫҺеӣўе……з”өе®қз”өйҮҸдёҚи¶ід№ҹжүЈиҙ№пјҢжҳҜиҙЁйҮҸй—®йўҳиҝҳжҳҜзі»з»ҹзјәйҷ·пјҹ
- дёӯж¶ҲеҚҸзӮ№еҗҚеӨ§ж•°жҚ®зҪ‘з»ңжқҖзҶҹ еҸҚеҜ№еҲ©з”Ёж¶Ҳиҙ№иҖ…дёӘдәәж•°жҚ®з”»еғҸ
- е®ғвҖңйӘ—дәҶвҖқж¶Ҳиҙ№иҖ…еӨҡе№ҙпјҢе·ҘеҺӮж—©е·ІеҒңдә§пјҢйқ е•Ҷж ҮдёҖе№ҙвҖңжҚһйҮ‘вҖқ12дәҝ
- иҺ«и®©е·®иҜ„и¶…й•ҝе®Ўж ёжңҹдҫөе®іж¶Ҳиҙ№иҖ…жқғзӣҠ
- дҪҺж¬Іжңӣзҡ„еҗҺеҺӮжқ‘пјҡйҒҚең°985гҖҒ211пјҢй«ҳ收е…ҘдҪҺж¶Ҳиҙ№пјҢеҒҸзҲұ996