ElasticsearchжҹҘиҜўйҖҹеәҰдёәд»Җд№Ҳиҝҷд№Ҳеҝ«пјҹ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
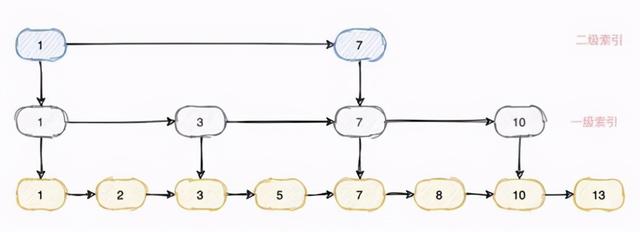
жҲ‘们еҸҜд»ҘдёәжңҖеә•еұӮзҡ„ж•°жҚ®жҸҗеҸ–еҮәдёҖзә§зҙўеј•гҖҒдәҢзә§зҙўеј• пјҢ ж №жҚ®ж•°жҚ®йҮҸзҡ„дёҚеҗҢ пјҢ жҲ‘们еҸҜд»ҘжҸҗеҸ–еҮә N зә§зҙўеј• гҖӮ еҪ“жҲ‘们жҹҘиҜўж—¶дҫҝеҸҜд»ҘеҲ©з”ЁиҝҷйҮҢзҡ„зҙўеј•еҸҳзӣёзҡ„е®һзҺ°дәҶдәҢеҲҶжҹҘжүҫ гҖӮ
еҒҮи®ҫзҺ°еңЁиҰҒжҹҘиҜў id=13 зҡ„ж•°жҚ® пјҢ еҸӘйңҖиҰҒйҒҚеҺҶ 1вҶ’7вҶ’10вҶ’13 еӣӣдёӘиҠӮзӮ№дҫҝеҸҜд»ҘжҹҘиҜўеҲ°ж•°жҚ® пјҢ еҪ“ж•°и¶ҠеӨҡж—¶ пјҢ ж•ҲзҺҮжҸҗеҚҮдјҡжӣҙжҳҺжҳҫ гҖӮ
еҗҢж—¶еҢәй—ҙжҹҘиҜўд№ҹжҳҜж”ҜжҢҒ пјҢ е’ҢеҲҡжүҚзҡ„жҹҘиҜўеҚ•дёӘиҠӮзӮ№зұ»дјј пјҢ еҸӘйңҖиҰҒжҹҘиҜўеҲ°иө·е§ӢиҠӮзӮ№ пјҢ 然еҗҺдҫқж¬ЎеҫҖеҗҺйҒҚеҺҶ(й“ҫиЎЁжңүеәҸ)еҲ°зӣ®ж ҮиҠӮзӮ№дҫҝиғҪе°Ҷж•ҙдёӘиҢғеӣҙзҡ„ж•°жҚ®жҹҘиҜўеҮәжқҘ гҖӮ
еҗҢж—¶з”ұдәҺжҲ‘们еңЁзҙўеј•дёҠдёҚдјҡеӯҳеӮЁзңҹжӯЈзҡ„ж•°жҚ® пјҢ еҸӘжҳҜеӯҳж”ҫдёҖдёӘжҢҮй’Ҳ пјҢ зӣёеҜ№дәҺжңҖеә•еұӮеӯҳж”ҫж•°жҚ®зҡ„й“ҫиЎЁжқҘиҜҙеҚ з”Ёзҡ„з©әй—ҙдҫҝеҸҜд»ҘеҝҪз•ҘдёҚи®ЎдәҶ гҖӮ
е№іиЎЎдәҢеҸүж ‘зҡ„дјҳеҢ–дҪҶе…¶е®һ MySQL дёӯзҡ„ InnoDB 并没жңүйҮҮз”Ёи·іиЎЁ пјҢ иҖҢжҳҜдҪҝз”Ёзҡ„дёҖдёӘеҸ«еҒҡ B+ ж ‘зҡ„ж•°жҚ®з»“жһ„ гҖӮ
иҝҷдёӘж•°жҚ®з»“жһ„дёҚеғҸжҳҜдәҢеҸүж ‘йӮЈж ·еӨ§еӯҰиҖҒеёҲеҪ“еҒҡеҹәзЎҖж•°жҚ®з»“жһ„з»Ҹеёёи®ІеҲ° пјҢ з”ұдәҺиҝҷзұ»ж•°жҚ®з»“жһ„йғҪжҳҜеңЁе®һйҷ…е·ҘзЁӢдёӯж №жҚ®йңҖжұӮеңәжҷҜеңЁеҹәзЎҖж•°жҚ®з»“жһ„дёӯжј”еҢ–иҖҢжқҘ гҖӮ
жҜ”еҰӮиҝҷйҮҢзҡ„ B+ ж ‘е°ұеҸҜд»Ҙи®ӨдёәжҳҜз”ұе№іиЎЎдәҢеҸүж ‘жј”еҢ–иҖҢжқҘ гҖӮ еҲҡжүҚжҲ‘们жҸҗеҲ°дәҢеҸүж ‘зҡ„еҢәй—ҙжҹҘиҜўж•ҲзҺҮдёҚй«ҳ пјҢ й’ҲеҜ№иҝҷдёҖзӮ№дҫҝеҸҜиҝӣиЎҢдјҳеҢ–пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
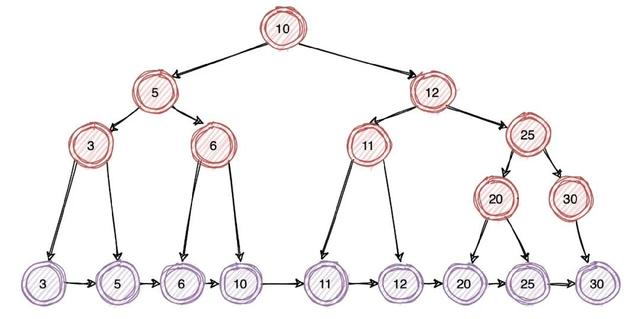
еңЁеҺҹжңүдәҢеҸүж ‘зҡ„еҹәзЎҖдёҠдјҳеҢ–еҗҺпјҡжүҖжңүзҡ„йқһеҸ¶еӯҗйғҪдёҚеӯҳж”ҫж•°жҚ® пјҢ еҸӘжҳҜдҪңдёәеҸ¶еӯҗиҠӮзӮ№зҡ„зҙўеј• пјҢ ж•°жҚ®е…ЁйғЁйғҪеӯҳж”ҫеңЁеҸ¶еӯҗиҠӮзӮ№ гҖӮ
иҝҷж ·жүҖжңүеҸ¶еӯҗиҠӮзӮ№зҡ„ж•°жҚ®йғҪжҳҜжңүеәҸеӯҳж”ҫзҡ„ пјҢ дҫҝиғҪеҫҲеҘҪзҡ„ж”ҜжҢҒеҢәй—ҙжҹҘиҜў гҖӮ еҸӘйңҖиҰҒе…ҲйҖҡиҝҮжҹҘиҜўеҲ°иө·е§ӢиҠӮзӮ№зҡ„дҪҚзҪ® пјҢ 然еҗҺеңЁеҸ¶еӯҗиҠӮзӮ№дёӯдҫқж¬ЎеҫҖеҗҺйҒҚеҺҶеҚіеҸҜ гҖӮ
еҪ“ж•°жҚ®йҮҸе·ЁеӨ§ж—¶ пјҢ еҫҲжҳҺжҳҫзҙўеј•ж–Ү件жҳҜдёҚиғҪеӯҳж”ҫдәҺеҶ…еӯҳдёӯ пјҢ иҷҪ然йҖҹеәҰеҫҲеҝ«дҪҶж¶ҲиҖ—зҡ„иө„жәҗд№ҹдёҚе°Ҹ;жүҖд»Ҙ MySQL дјҡе°Ҷзҙўеј•ж–Ү件зӣҙжҺҘеӯҳж”ҫдәҺзЈҒзӣҳдёӯ гҖӮ
иҝҷзӮ№е’ҢеҗҺж–ҮжҸҗеҲ° Elasticsearch зҡ„зҙўеј•з•ҘжңүдёҚеҗҢ гҖӮ з”ұдәҺзҙўеј•еӯҳж”ҫдәҺзЈҒзӣҳдёӯ пјҢ жүҖд»ҘжҲ‘们иҰҒе°ҪеҸҜиғҪзҡ„еҮҸе°‘дёҺзЈҒзӣҳзҡ„ IO(зЈҒзӣҳ IO зҡ„ж•ҲзҺҮдёҺеҶ…еӯҳдёҚеңЁдёҖдёӘж•°йҮҸзә§) гҖӮ
йҖҡиҝҮдёҠеӣҫеҸҜд»ҘзңӢеҮә пјҢ жҲ‘们иҰҒжҹҘиҜўдёҖжқЎж•°жҚ®иҮіе°‘еҫ—иҝӣиЎҢ 4 ж¬ЎIO пјҢ еҫҲжҳҺжҳҫиҝҷдёӘ IO ж¬Ўж•°жҳҜдёҺж ‘зҡ„й«ҳеәҰеҜҶеҲҮзӣёе…ізҡ„ пјҢ ж ‘зҡ„й«ҳеәҰи¶ҠдҪҺ IO ж¬Ўж•°е°ұдјҡи¶Ҡе°‘ пјҢ еҗҢж—¶жҖ§иғҪд№ҹдјҡи¶ҠеҘҪ гҖӮ
йӮЈжҖҺж ·жүҚиғҪйҷҚдҪҺж ‘зҡ„й«ҳеәҰе‘ў?
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
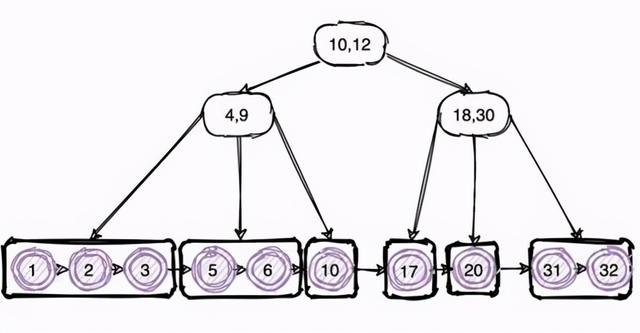
жҲ‘们еҸҜд»Ҙе°қиҜ•жҠҠдәҢеҸүж ‘еҸҳдёәдёүеҸүж ‘ пјҢ иҝҷж ·ж ‘зҡ„й«ҳеәҰе°ұдјҡдёӢйҷҚеҫҲеӨҡ пјҢ иҝҷж ·жҹҘиҜўж•°жҚ®ж—¶зҡ„ IO ж¬Ўж•°иҮӘ然д№ҹдјҡйҷҚдҪҺ пјҢ еҗҢж—¶жҹҘиҜўж•ҲзҺҮд№ҹдјҡжҸҗй«ҳи®ёеӨҡ гҖӮ иҝҷе…¶е®һе°ұжҳҜ B+ ж ‘зҡ„з”ұжқҘ гҖӮ
дҪҝз”Ёзҙўеј•зҡ„дёҖдәӣе»әи®®е…¶е®һйҖҡиҝҮдёҠеӣҫеҜ№ B+ж ‘зҡ„зҗҶи§Ј пјҢ д№ҹиғҪдјҳеҢ–ж—Ҙеёёе·ҘдҪңзҡ„дёҖдәӣе°Ҹз»ҶиҠӮ;жҜ”еҰӮдёәд»Җд№ҲйңҖиҰҒжңҖеҘҪжҳҜжңүеәҸйҖ’еўһзҡ„?
еҒҮи®ҫжҲ‘们еҶҷе…Ҙзҡ„дё»й”®ж•°жҚ®жҳҜж— еәҸзҡ„ пјҢ йӮЈд№ҲжңүеҸҜиғҪеҗҺеҶҷе…Ҙж•°жҚ®зҡ„ id е°ҸдәҺд№ӢеүҚеҶҷе…Ҙзҡ„ пјҢ иҝҷж ·еңЁз»ҙжҠӨ B+ж ‘зҙўеј•ж—¶дҫҝжңүеҸҜиғҪйңҖиҰҒ移еҠЁе·Із»ҸеҶҷеҘҪж•°жҚ® гҖӮ
еҰӮжһңжҳҜжҢүз…§йҖ’еўһеҶҷе…Ҙж•°жҚ®ж—¶еҲҷдёҚдјҡжңүиҝҷдёӘиҖғиҷ‘ пјҢ жҜҸж¬ЎеҸӘйңҖиҰҒдҫқж¬ЎеҶҷе…ҘеҚіеҸҜ гҖӮ жүҖд»ҘжҲ‘们жүҚдјҡиҰҒжұӮж•°жҚ®еә“дё»й”®е°ҪйҮҸжҳҜи¶ӢеҠҝйҖ’еўһзҡ„ пјҢ дёҚиҖғиҷ‘еҲҶиЎЁзҡ„жғ…еҶөж—¶жңҖеҗҲзҗҶзҡ„е°ұжҳҜиҮӘеўһдё»й”® гҖӮ
ж•ҙдҪ“жқҘзңӢжҖқи·Ҝе’Ңи·іиЎЁзұ»дјј пјҢ еҸӘжҳҜй’ҲеҜ№дҪҝз”ЁеңәжҷҜеҒҡдәҶзӣёе…ізҡ„и°ғж•ҙ(жҜ”еҰӮж•°жҚ®е…ЁйғЁеӯҳеӮЁдәҺеҸ¶еӯҗиҠӮзӮ№) гҖӮ
ES зҙўеј•MySQL иҒҠе®ҢдәҶ пјҢ зҺ°еңЁжқҘзңӢзңӢ Elasticsearch жҳҜеҰӮдҪ•жқҘдҪҝз”Ёзҙўеј•зҡ„ гҖӮ
жӯЈжҺ’зҙўеј•еңЁ ES дёӯйҮҮз”Ёзҡ„жҳҜдёҖз§ҚеҗҚеҸ«еҖ’жҺ’зҙўеј•зҡ„ж•°жҚ®з»“жһ„;еңЁжӯЈејҸи®ІеҖ’жҺ’зҙўеј•д№ӢеүҚе…ҲжқҘиҒҠиҒҠе’Ңд»–зӣёеҸҚзҡ„жӯЈжҺ’зҙўеј• гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
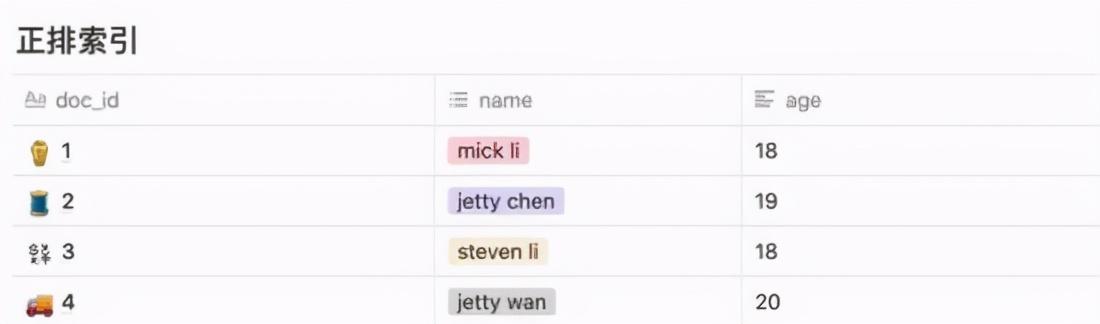
д»ҘдёҠеӣҫдёәдҫӢ пјҢ жҲ‘们еҸҜд»ҘйҖҡиҝҮ doc_id жҹҘиҜўеҲ°е…·дҪ“еҜ№иұЎзҡ„ж–№ејҸз§°дёәдҪҝз”ЁжӯЈжҺ’зҙўеј• пјҢ е…¶е®һд№ҹиғҪзҗҶи§ЈдёәдёҖз§Қж•ЈеҲ—иЎЁ гҖӮ
жң¬иҙЁжҳҜйҖҡиҝҮ key жқҘжҹҘжүҫ value гҖӮ жҜ”еҰӮйҖҡиҝҮ doc_id=4 дҫҝиғҪеҫҲеҝ«жҹҘиҜўеҲ° name=jetty wang пјҢ age=20 иҝҷжқЎж•°жҚ® гҖӮ
жҺЁиҚҗйҳ…иҜ»








![[з»ҝиұҶ]з”·дәәжғіиҰҒй•ҝеҜҝпјҢ5件вҖңиҖ—йҳівҖқзҡ„дәӢиҰҒвҖңиҲҚејғвҖқпјҢдёҖдәӣдәәиЎЁзӨәеҫҲйҡҫеҒҡеҲ°](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/26fa2bbcc60faf5ef39679c3f1999fd3.jpg)








- iQOO 7е®ҳж–№зҫҺеӣҫиөҸпјҡдёүз§Қй…ҚиүІгҖҒйҖҹеәҰзҫҺеӯҰи®ҫи®Ўдј жүҝ
- AIжҲҳз–«гҖҒзңҹ5GжқҘдәҶпјҢеҚҒеӨ§жңҖзғӯ门科жҠҖеә”з”Ёжј”з»ҺйҖҹеәҰдёҺжё©еәҰ
- йҰ–ж¬ҫ7GB/s SSDпјҒдёүжҳҹ980PRO 1TBиҜ„жөӢпјҡж°ёжҒ’зҡ„1.8GB/sзј“еӨ–еҶҷе…ҘйҖҹеәҰ
- е°Ҹзұі11 PK е°Ҹзұі10пјҡдј иҫ“йҖҹеәҰжҸҗеҚҮ1.6еҖҚ
- 4GйҖҹеәҰеҸҳж…ўпјҹиҝҗиҗҘе•Ҷиҝҷжіўж“ҚдҪңпјҢи®©5Gз§’еҸҳвҖңзңҹйҰҷзҺ°еңәвҖқ
- 专家д»Ӣз»ҚеҰӮдҪ•еҲӨж–ӯжҷәиғҪжүӢжңәиў«е…ҘдҫөпјҡиҝҗиЎҢйҖҹеәҰеҸҳж…ўгҖҒз”өжұ ж¶ҲиҖ—иҝҮеҝ«д»ҘеҸҠеҚЎйЎҝ
- 马еҢ–и…ҫиҝҷжӢӣеӨӘй«ҳжҳҺпјҒзҪ‘еҸӢпјҡеҸӘиҰҒжҲ‘ж”№еҗҚзҡ„йҖҹеәҰеӨҹеҝ«пјҢзҰҒд»Өе°ұиҝҪдёҚдёҠжҲ‘
- жҖҺж ·жҸҗй«ҳиӢ№жһң6зҡ„иҝҗиЎҢйҖҹеәҰпјҹжңүиҝҷдәӣй—®йўҳе°ұеҲ«ж•‘дәҶпјҢдҪ з”ЁдәҶеҮ е№ҙдәҶпјҹ
- з”ЁжҲ·|4GйҖҹеәҰж…ўдәҶпјҒ5Gд№ҹйҡҫйҖғвҖңзңҹйҰҷе®ҡеҫӢвҖқ
- еҒҘеә·е®қпјҢдҝқеҒҘеә·дёҚдҝқйҡҗз§Ғпјҹ