ElasticsearchжҹҘиҜўйҖҹеәҰдёәд»Җд№Ҳиҝҷд№Ҳеҝ«пјҹ( дёү )
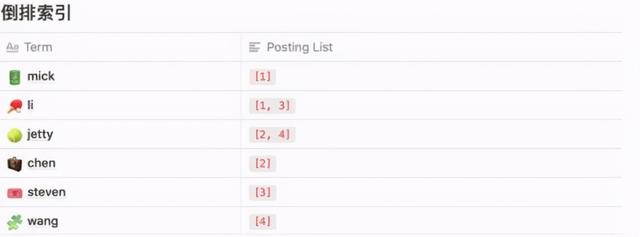
еҖ’жҺ’зҙўеј•йӮЈеҰӮжһңеҸҚиҝҮжқҘжҲ‘жғіжҹҘиҜў name дёӯеҢ…еҗ«дәҶ li зҡ„ж•°жҚ®жңүе“Әдәӣ?иҝҷж ·еҰӮдҪ•й«ҳж•ҲжҹҘиҜўе‘ў?
д»…д»…йҖҡиҝҮдёҠж–ҮжҸҗеҲ°зҡ„жӯЈжҺ’зҙўеј•жҳҫ然иө·дёҚеҲ°д»Җд№ҲдҪңз”Ё пјҢ еҸӘиғҪдҫқж¬Ўе°ҶжүҖжңүж•°жҚ®йҒҚеҺҶеҗҺеҲӨж–ӯеҗҚз§°дёӯжҳҜеҗҰеҢ…еҗ« li ;иҝҷж ·ж•ҲзҺҮеҚҒеҲҶдҪҺдёӢ гҖӮ
дҪҶеҰӮжһңжҲ‘们йҮҚж–°жһ„е»әдёҖдёӘзҙўеј•з»“жһ„пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҪ“иҰҒжҹҘиҜў name дёӯеҢ…еҗ« li зҡ„ж•°жҚ®ж—¶ пјҢ еҸӘйңҖиҰҒйҖҡиҝҮиҝҷдёӘзҙўеј•з»“жһ„жҹҘиҜўеҲ° Posting List дёӯжүҖеҢ…еҗ«зҡ„ж•°жҚ® пјҢ еҶҚйҖҡиҝҮжҳ е°„зҡ„ж–№ејҸжҹҘиҜўеҲ°жңҖз»Ҳзҡ„ж•°жҚ® гҖӮ
иҝҷдёӘзҙўеј•з»“жһ„е…¶е®һе°ұжҳҜеҖ’жҺ’зҙўеј• гҖӮ
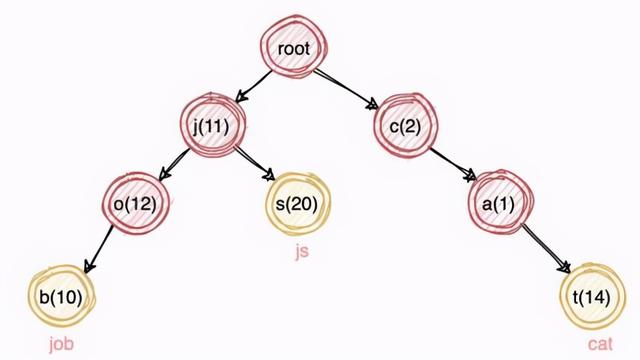
Term DictionaryдҪҶеҰӮдҪ•й«ҳж•Ҳзҡ„еңЁиҝҷдёӘзҙўеј•з»“жһ„дёӯжҹҘиҜўеҲ° li е‘ў пјҢ з»“еҗҲжҲ‘们д№ӢеүҚзҡ„з»ҸйӘҢ пјҢ еҸӘиҰҒжҲ‘们е°Ҷ Term жңүеәҸжҺ’еҲ— пјҢ дҫҝеҸҜд»ҘдҪҝз”ЁдәҢеҸүж ‘жҗңзҙўж ‘зҡ„ж•°жҚ®з»“жһ„еңЁ o(logn) дёӢжҹҘиҜўеҲ°ж•°жҚ® гҖӮ
е°ҶдёҖдёӘж–Үжң¬жӢҶеҲҶжҲҗдёҖдёӘдёҖдёӘзӢ¬з«ӢTerm зҡ„иҝҮзЁӢе…¶е®һе°ұжҳҜжҲ‘们常иҜҙзҡ„еҲҶиҜҚ гҖӮ
иҖҢе°ҶжүҖжңү Term еҗҲ并еңЁдёҖиө·е°ұжҳҜдёҖдёӘ Term Dictionary пјҢ д№ҹеҸҜд»ҘеҸ«еҒҡеҚ•иҜҚиҜҚе…ё гҖӮ
иӢұж–Үзҡ„еҲҶиҜҚзӣёеҜ№з®ҖеҚ• пјҢ еҸӘйңҖиҰҒйҖҡиҝҮз©әж јгҖҒж ҮзӮ№з¬ҰеҸ·е°Ҷж–Үжң¬еҲҶйҡ”дҫҝиғҪжӢҶиҜҚ пјҢ дёӯж–ҮеҲҷзӣёеҜ№еӨҚжқӮ пјҢ дҪҶд№ҹжңүи®ёеӨҡејҖжәҗе·Ҙе…·еҒҡж”ҜжҢҒ(з”ұдәҺдёҚжҳҜжң¬ж–ҮйҮҚзӮ№ пјҢ еҜ№еҲҶиҜҚж„ҹе…ҙи¶Јзҡ„еҸҜд»ҘиҮӘиЎҢжҗңзҙў) гҖӮ
еҪ“жҲ‘们зҡ„ж–Үжң¬йҮҸе·ЁеӨ§ж—¶ пјҢ еҲҶиҜҚеҗҺзҡ„ Term д№ҹдјҡеҫҲеӨҡ пјҢ иҝҷж ·дёҖдёӘеҖ’жҺ’зҙўеј•зҡ„ж•°жҚ®з»“жһ„еҰӮжһңеӯҳж”ҫдәҺеҶ…еӯҳйӮЈиӮҜе®ҡжҳҜдёҚеӨҹеӯҳзҡ„ пјҢ дҪҶеҰӮжһңеғҸ MySQL йӮЈж ·еӯҳж”ҫдәҺзЈҒзӣҳ пјҢ ж•ҲзҺҮд№ҹжІЎйӮЈд№Ҳй«ҳ гҖӮ
Term IndexжүҖд»ҘжҲ‘们еҸҜд»ҘйҖүжӢ©дёҖдёӘжҠҳдёӯзҡ„ж–№жі• пјҢ ж—ўз„¶ж— жі•е°Ҷж•ҙдёӘ Term Dictionary ж”ҫе…ҘеҶ…еӯҳдёӯ пјҢ йӮЈжҲ‘们еҸҜд»Ҙдёә Term Dictionary еҲӣе»әдёҖдёӘзҙўеј•з„¶еҗҺж”ҫе…ҘеҶ…еӯҳдёӯ гҖӮ
иҝҷж ·дҫҝеҸҜд»Ҙй«ҳж•Ҳзҡ„жҹҘиҜў Term DictionaryпјҢ жңҖеҗҺеҶҚйҖҡиҝҮ Term Dictionary жҹҘиҜўеҲ° Posting List гҖӮ
зӣёеҜ№дәҺ MySQL дёӯзҡ„ B+ж ‘жқҘиҜҙд№ҹдјҡеҮҸе°‘дәҶеҮ ж¬ЎзЈҒзӣҳ IO гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷдёӘ Term Index жҲ‘们еҸҜд»ҘдҪҝз”Ёиҝҷж ·зҡ„ Trie ж ‘ пјҢ д№ҹе°ұжҳҜжҲ‘们常иҜҙзҡ„еӯ—е…ёж ‘жқҘеӯҳж”ҫ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
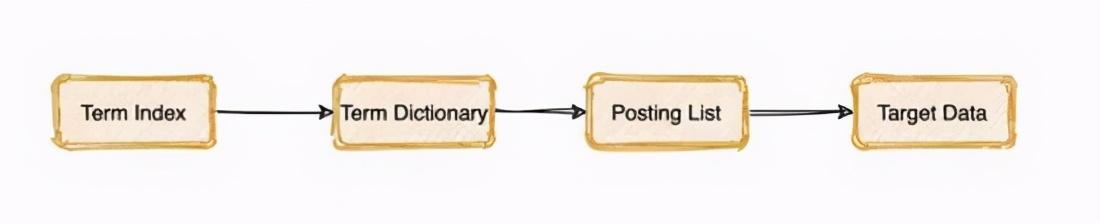
еҰӮжһңжҲ‘们жҳҜд»Ҙ j ејҖеӨҙзҡ„ Term иҝӣиЎҢжҗңзҙў пјҢ йҰ–е…Ҳ第дёҖжӯҘе°ұжҳҜйҖҡиҝҮеңЁеҶ…еӯҳдёӯзҡ„ Term Index жҹҘиҜўеҮәд»Ҙ j жү“еӨҙзҡ„ Term еңЁ Term Dictionary еӯ—е…ёж–Ү件дёӯзҡ„е“ӘдёӘдҪҚзҪ®(иҝҷдёӘдҪҚзҪ®еҸҜд»ҘжҳҜдёҖдёӘж–Ү件жҢҮй’Ҳ пјҢ еҸҜиғҪжҳҜдёҖдёӘеҢәй—ҙиҢғеӣҙ) гҖӮ
зҙ§жҺҘзқҖеңЁе°ҶиҝҷдёӘдҪҚзҪ®еҢәй—ҙдёӯзҡ„жүҖжңү Term еҸ–еҮә пјҢ з”ұдәҺе·Із»ҸжҺ’еҘҪеәҸ пјҢ дҫҝеҸҜйҖҡиҝҮдәҢеҲҶжҹҘжүҫеҝ«йҖҹе®ҡдҪҚеҲ°е…·дҪ“дҪҚзҪ®;иҝҷж ·дҫҝеҸҜжҹҘиҜўеҮә Posting List гҖӮ
жңҖз»ҲйҖҡиҝҮ Posting List дёӯзҡ„дҪҚзҪ®дҝЎжҒҜдҫҝеҸҜеңЁеҺҹе§Ӣж–Ү件дёӯе°Ҷзӣ®ж Үж•°жҚ®жЈҖзҙўеҮәжқҘ гҖӮ
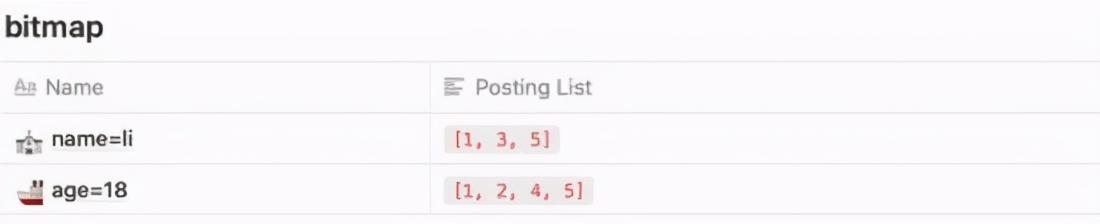
жӣҙеӨҡдјҳеҢ–еҪ“然 Elasticsearch иҝҳеҒҡдәҶи®ёеӨҡй’ҲеҜ№жҖ§зҡ„дјҳеҢ– пјҢ еҪ“жҲ‘们еҜ№дёӨдёӘеӯ—ж®өиҝӣиЎҢжЈҖзҙўж—¶ пјҢ е°ұеҸҜд»ҘеҲ©з”Ё Bitmap иҝӣиЎҢдјҳеҢ– гҖӮ
жҜ”еҰӮзҺ°еңЁйңҖиҰҒжҹҘиҜў name=li and age=18 зҡ„ж•°жҚ® пјҢ иҝҷж—¶жҲ‘们йңҖиҰҒйҖҡиҝҮиҝҷдёӨдёӘеӯ—ж®өе°Ҷеҗ„иҮӘзҡ„з»“жһң Posting List еҸ–еҮә гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жңҖз®ҖеҚ•зҡ„ж–№жі•жҳҜеҲҶеҲ«йҒҚеҺҶдёӨдёӘйӣҶеҗҲ пјҢ еҸ–еҮәйҮҚеӨҚзҡ„ж•°жҚ® пјҢ дҪҶиҝҷдёӘжҳҺжҳҫж•ҲзҺҮдҪҺдёӢ гҖӮ
иҝҷж—¶жҲ‘们дҫҝеҸҜдҪҝз”Ё Bitmap зҡ„ж–№ејҸиҝӣиЎҢеӯҳеӮЁ(иҝҳиҠӮзңҒеӯҳеӮЁз©әй—ҙ) пјҢ еҗҢж—¶еҲ©з”Ёе…ҲеӨ©зҡ„дҪҚдёҺи®Ўз®—дҫҝеҸҜеҫ—еҮәз»“жһң гҖӮ
[1, 3, 5] ? 10101[1, 2, 4, 5] ? 11011 иҝҷж ·дёӨдёӘдәҢиҝӣеҲ¶ж•°з»„жұӮдёҺдҫҝеҸҜеҫ—еҮәз»“жһңпјҡ
10001 ? [1, 5] жңҖз»ҲеҸҚи§ЈеҮә Posting List дёә [1, 5] пјҢ иҝҷж ·зҡ„ж•ҲзҺҮиҮӘ然жҳҜиҰҒй«ҳдёҠи®ёеӨҡ гҖӮ еҗҢж ·зҡ„жҹҘиҜўйңҖжұӮеңЁ MySQL дёӯ并没жңүзү№ж®ҠдјҳеҢ– пјҢ еҸӘжҳҜе…Ҳе°Ҷж•°жҚ®йҮҸе°Ҹзҡ„ж•°жҚ®зӯӣйҖүеҮәжқҘд№ӢеҗҺеҶҚзӯӣйҖү第дәҢдёӘеӯ—ж®ө пјҢ ж•ҲзҺҮиҮӘ然д№ҹе°ұжІЎжңү ES й«ҳ гҖӮ
еҪ“然еңЁжңҖж–°зүҲзҡ„ ES дёӯд№ҹдјҡеҜ№ Posting List иҝӣиЎҢеҺӢзј© пјҢ е…·дҪ“еҺӢ缩规еҲҷеҸҜд»ҘжҹҘзңӢе®ҳж–№ж–ҮжЎЈ пјҢ иҝҷйҮҢе°ұдёҚе…·дҪ“д»Ӣз»ҚдәҶ гҖӮ
жҺЁиҚҗйҳ…иҜ»




















- iQOO 7е®ҳж–№зҫҺеӣҫиөҸпјҡдёүз§Қй…ҚиүІгҖҒйҖҹеәҰзҫҺеӯҰи®ҫи®Ўдј жүҝ
- AIжҲҳз–«гҖҒзңҹ5GжқҘдәҶпјҢеҚҒеӨ§жңҖзғӯ门科жҠҖеә”з”Ёжј”з»ҺйҖҹеәҰдёҺжё©еәҰ
- йҰ–ж¬ҫ7GB/s SSDпјҒдёүжҳҹ980PRO 1TBиҜ„жөӢпјҡж°ёжҒ’зҡ„1.8GB/sзј“еӨ–еҶҷе…ҘйҖҹеәҰ
- е°Ҹзұі11 PK е°Ҹзұі10пјҡдј иҫ“йҖҹеәҰжҸҗеҚҮ1.6еҖҚ
- 4GйҖҹеәҰеҸҳж…ўпјҹиҝҗиҗҘе•Ҷиҝҷжіўж“ҚдҪңпјҢи®©5Gз§’еҸҳвҖңзңҹйҰҷзҺ°еңәвҖқ
- 专家д»Ӣз»ҚеҰӮдҪ•еҲӨж–ӯжҷәиғҪжүӢжңәиў«е…ҘдҫөпјҡиҝҗиЎҢйҖҹеәҰеҸҳж…ўгҖҒз”өжұ ж¶ҲиҖ—иҝҮеҝ«д»ҘеҸҠеҚЎйЎҝ
- 马еҢ–и…ҫиҝҷжӢӣеӨӘй«ҳжҳҺпјҒзҪ‘еҸӢпјҡеҸӘиҰҒжҲ‘ж”№еҗҚзҡ„йҖҹеәҰеӨҹеҝ«пјҢзҰҒд»Өе°ұиҝҪдёҚдёҠжҲ‘
- жҖҺж ·жҸҗй«ҳиӢ№жһң6зҡ„иҝҗиЎҢйҖҹеәҰпјҹжңүиҝҷдәӣй—®йўҳе°ұеҲ«ж•‘дәҶпјҢдҪ з”ЁдәҶеҮ е№ҙдәҶпјҹ
- з”ЁжҲ·|4GйҖҹеәҰж…ўдәҶпјҒ5Gд№ҹйҡҫйҖғвҖңзңҹйҰҷе®ҡеҫӢвҖқ
- еҒҘеә·е®қпјҢдҝқеҒҘеә·дёҚдҝқйҡҗз§Ғпјҹ