ElasticsearchжҹҘиҜўйҖҹеәҰдёәд»Җд№Ҳиҝҷд№Ҳеҝ«пјҹ
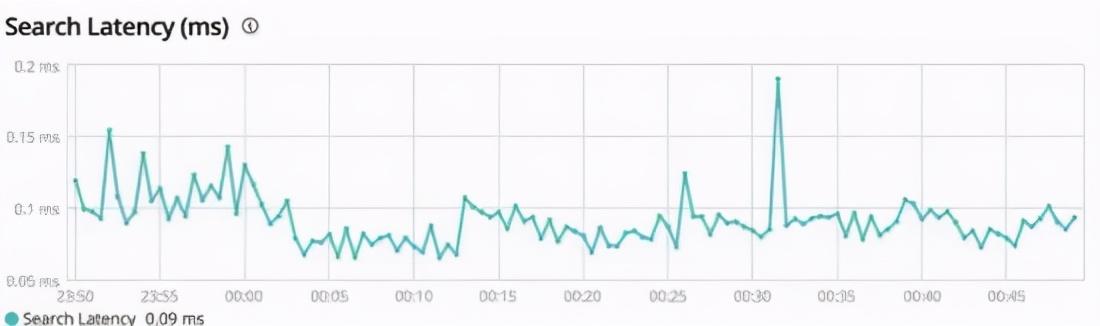
иҝҷж®өж—¶й—ҙеңЁз»ҙжҠӨдә§е“Ғзҡ„жҗңзҙўеҠҹиғҪ пјҢ жҜҸж¬ЎеңЁз®ЎзҗҶеҸ°зңӢеҲ° Elasticsearch иҝҷд№Ҳй«ҳж•Ҳзҡ„жҹҘиҜўж•ҲзҺҮжҲ‘йғҪеҫҲеҘҪеҘҮд»–жҳҜеҰӮдҪ•еҒҡеҲ°зҡ„ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷз”ҡиҮіжҜ”еңЁжҲ‘жң¬ең°дҪҝз”Ё MySQL йҖҡиҝҮдё»й”®зҡ„жҹҘиҜўйҖҹеәҰиҝҳеҝ« гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дёәжӯӨжҲ‘жҗңзҙўдәҶзӣёе…іиө„ж–ҷпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷзұ»й—®йўҳзҪ‘дёҠеҫҲеӨҡзӯ”жЎҲ пјҢ еӨ§жҰӮж„ҸжҖқе‘ўеҰӮдёӢпјҡES жҳҜеҹәдәҺ Lucene зҡ„е…Ёж–ҮжЈҖзҙўеј•ж“Һ пјҢ е®ғдјҡеҜ№ж•°жҚ®иҝӣиЎҢеҲҶиҜҚеҗҺдҝқеӯҳзҙўеј• пјҢ ж“…й•ҝз®ЎзҗҶеӨ§йҮҸзҡ„зҙўеј•ж•°жҚ® пјҢ зӣёеҜ№дәҺ MySQL жқҘиҜҙдёҚж“…й•ҝз»Ҹеёёжӣҙж–°ж•°жҚ®еҸҠе…іиҒ”жҹҘиҜў гҖӮ
иҜҙзҡ„дёҚжҳҜеҫҲйҖҸеҪ» пјҢ жІЎжңүи§Јжһҗзӣёе…ізҡ„еҺҹзҗҶ;дёҚиҝҮ既然еҸҚеӨҚжҸҗеҲ°дәҶзҙўеј• пјҢ йӮЈжҲ‘们е°ұд»Һзҙўеј•зҡ„и§’еәҰжқҘеҜ№жҜ”дёӢдёӨиҖ…зҡ„е·®ејӮ гҖӮ
MySQL зҙўеј•е…Ҳд»Һ MySQL иҜҙиө· пјҢ зҙўеј•иҝҷдёӘиҜҚжғіеҝ…еӨ§е®¶д№ҹжҳҜзғӮзҶҹдәҺеҝғ пјҢ йҖҡеёёеӯҳеңЁдәҺдёҖдәӣжҹҘиҜўзҡ„еңәжҷҜ пјҢ жҳҜе…ёеһӢзҡ„з©әй—ҙжҚўж—¶й—ҙзҡ„жЎҲдҫӢ гҖӮ д»ҘдёӢеҶ…е®№д»Ҙ InnoDB еј•ж“ҺдёәдҫӢ гҖӮ
еёёи§Ғзҡ„ж•°жҚ®з»“жһ„еҒҮи®ҫз”ұжҲ‘们иҮӘе·ұжқҘи®ҫи®Ў MySQL зҡ„зҙўеј• пјҢ еӨ§жҰӮдјҡжңүе“ӘдәӣйҖүжӢ©е‘ў?
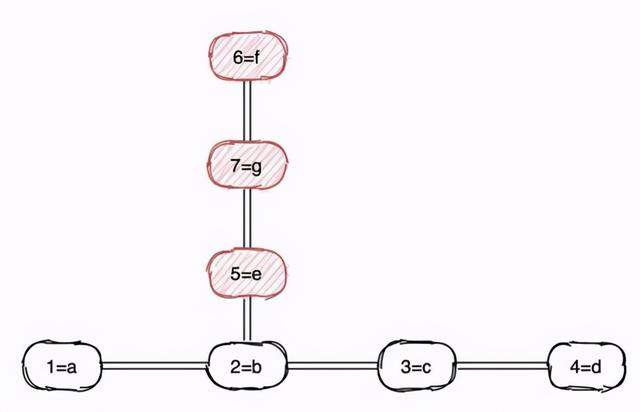
в‘ ж•ЈеҲ—иЎЁйҰ–е…ҲжҲ‘们еә”еҪ“жғіеҲ°зҡ„жҳҜж•ЈеҲ—иЎЁ пјҢ иҝҷжҳҜдёҖдёӘйқһеёёеёёи§Ғдё”й«ҳж•Ҳзҡ„жҹҘиҜўгҖҒеҶҷе…Ҙзҡ„ж•°жҚ®з»“жһ„ пјҢ еҜ№еә”еҲ° Java дёӯе°ұжҳҜ HashMap гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иҝҷдёӘж•°жҚ®з»“жһ„еә”иҜҘдёҚйңҖиҰҒиҝҮеӨҡд»Ӣз»ҚдәҶ пјҢ е®ғзҡ„еҶҷе…Ҙж•ҲзҺҮеҫҲй«ҳ O(1) пјҢ жҜ”еҰӮжҲ‘们иҰҒжҹҘиҜў id=3 зҡ„ж•°жҚ®ж—¶ пјҢ йңҖиҰҒе°Ҷ 3 иҝӣиЎҢе“ҲеёҢиҝҗз®— пјҢ 然еҗҺеҶҚиҝҷдёӘж•°з»„дёӯжүҫеҲ°еҜ№еә”зҡ„дҪҚзҪ®еҚіеҸҜ гҖӮ
дҪҶеҰӮжһңжҲ‘们жғіжҹҘиҜў 1вүӨidвүӨ6 иҝҷж ·зҡ„еҢәй—ҙж•°жҚ®ж—¶ пјҢ ж•ЈеҲ—иЎЁе°ұдёҚиғҪеҫҲеҘҪзҡ„ж»Ўи¶ідәҶ пјҢ з”ұдәҺе®ғжҳҜж— еәҸзҡ„ пјҢ жүҖд»Ҙеҫ—е°ҶжүҖжңүж•°жҚ®йҒҚеҺҶдёҖйҒҚжүҚиғҪзҹҘйҒ“е“Әдәӣж•°жҚ®еұһдәҺиҝҷдёӘеҢәй—ҙ гҖӮ
в‘ЎжңүеәҸж•°з»„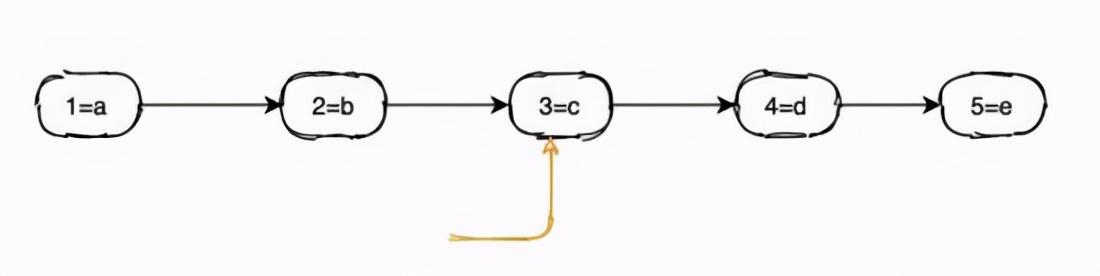 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жңүеәҸж•°з»„зҡ„жҹҘиҜўж•ҲзҺҮд№ҹеҫҲй«ҳ пјҢ еҪ“жҲ‘们иҰҒжҹҘиҜў id=4 зҡ„ж•°жҚ®ж—¶ пјҢ еҸӘйңҖиҰҒйҖҡиҝҮдәҢеҲҶжҹҘжүҫд№ҹиғҪй«ҳж•Ҳе®ҡдҪҚеҲ°ж•°жҚ® O(logn) гҖӮ
еҗҢж—¶з”ұдәҺж•°жҚ®д№ҹжҳҜжңүеәҸзҡ„ пјҢ жүҖд»ҘиҮӘ然д№ҹиғҪж”ҜжҢҒеҢәй—ҙжҹҘиҜў;иҝҷд№ҲзңӢжқҘжңүеәҸж•°з»„йҖӮеҗҲз”ЁеҒҡзҙўеј•е’Ҝ?
иҮӘ然жҳҜдёҚиЎҢ пјҢ е®ғжңүеҸҰдёҖдёӘйҮҚеӨ§й—®йўҳ;еҒҮи®ҫжҲ‘们жҸ’е…ҘдәҶ id=2.5 зҡ„ж•°жҚ® пјҢ е°ұеҫ—еҗҢж—¶е°ҶеҗҺз»ӯзҡ„жүҖжңүж•°жҚ®йғҪ移еҠЁдёҖдҪҚ пјҢ иҝҷдёӘеҶҷе…Ҙж•ҲзҺҮе°ұдјҡеҸҳеҫ—йқһеёёдҪҺ гҖӮ
в‘ўе№іиЎЎдәҢеҸүж ‘ж—ўз„¶жңүеәҸж•°з»„зҡ„еҶҷе…Ҙж•ҲзҺҮдёҚй«ҳ пјҢ йӮЈжҲ‘们е°ұжқҘзңӢзңӢеҶҷе…Ҙж•ҲзҺҮй«ҳзҡ„ пјҢ еҫҲе®№жҳ“е°ұиғҪжғіеҲ°дәҢеҸүж ‘ гҖӮ
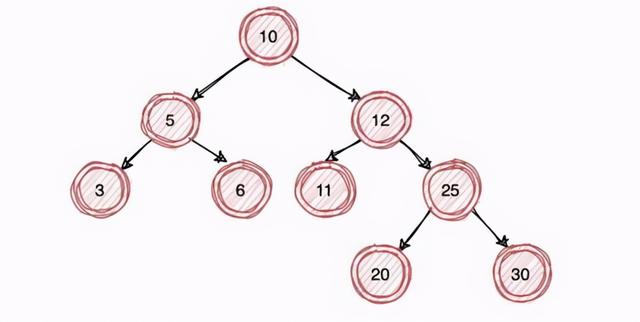
иҝҷйҮҢжҲ‘们д»Ҙе№іиЎЎдәҢеҸүж ‘дёәдҫӢпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
з”ұдәҺе№іиЎЎдәҢеҸүж ‘зҡ„зү№жҖ§пјҡе·ҰиҠӮзӮ№е°ҸдәҺзҲ¶иҠӮзӮ№гҖҒеҸіиҠӮзӮ№еӨ§дәҺзҲ¶иҠӮзӮ№ гҖӮ
жүҖд»ҘеҒҮи®ҫжҲ‘们иҰҒжҹҘиҜў id=11 зҡ„ж•°жҚ® пјҢ еҸӘйңҖиҰҒжҹҘиҜў 10вҶ’12вҶ’11 дҫҝиғҪжңҖз»ҲжүҫеҲ°ж•°жҚ® пјҢ ж—¶й—ҙеӨҚжқӮеәҰдёә O(logn) пјҢ еҗҢзҗҶеҶҷе…Ҙж•°жҚ®ж—¶д№ҹдёә O(logn) гҖӮ
дҪҶдҫқ然дёҚиғҪеҫҲеҘҪзҡ„ж”ҜжҢҒеҢәй—ҙиҢғеӣҙжҹҘжүҫ пјҢ еҒҮи®ҫжҲ‘们иҰҒжҹҘиҜў 5вүӨidвүӨ20 зҡ„ж•°жҚ®ж—¶ пјҢ йңҖиҰҒе…ҲжҹҘиҜў 10 иҠӮзӮ№зҡ„е·Ұеӯҗж ‘еҶҚжҹҘиҜў 10 иҠӮзӮ№зҡ„еҸіеӯҗж ‘жңҖз»ҲжүҚиғҪжҹҘиҜўеҲ°жүҖжңүж•°жҚ® гҖӮ еҜјиҮҙиҝҷж ·зҡ„жҹҘиҜўж•ҲзҺҮ并дёҚй«ҳ гҖӮ
в‘Ји·іиЎЁи·іиЎЁеҸҜиғҪдёҚеғҸдёҠиҫ№жҸҗеҲ°зҡ„ж•ЈеҲ—иЎЁгҖҒжңүеәҸж•°з»„гҖҒдәҢеҸүж ‘йӮЈж ·ж—Ҙеёёи§Ғзҡ„жҜ”иҫғеӨҡ пјҢ дҪҶе…¶е®һ Redis дёӯзҡ„ sort set е°ұйҮҮз”ЁдәҶи·іиЎЁе®һзҺ° гҖӮ иҝҷйҮҢжҲ‘们з®ҖеҚ•д»Ӣз»ҚдёӢи·іиЎЁе®һзҺ°зҡ„ж•°жҚ®з»“жһ„жңүдҪ•дјҳеҠҝ гҖӮ
жҲ‘们йғҪзҹҘйҒ“еҚідҫҝжҳҜеҜ№дёҖдёӘжңүеәҸй“ҫиЎЁиҝӣиЎҢжҹҘиҜўж•ҲзҺҮд№ҹдёҚй«ҳ пјҢ з”ұдәҺе®ғдёҚиғҪдҪҝз”Ёж•°з»„дёӢж ҮиҝӣиЎҢдәҢеҲҶжҹҘжүҫ пјҢ жүҖд»Ҙж—¶й—ҙеӨҚжқӮеәҰжҳҜ o(n) гҖӮ
дҪҶжҲ‘们д№ҹеҸҜд»Ҙе·§еҰҷзҡ„дјҳеҢ–й“ҫиЎЁжқҘеҸҳзӣёзҡ„е®һзҺ°дәҢеҲҶжҹҘжүҫ пјҢ еҰӮдёӢеӣҫпјҡ
жҺЁиҚҗйҳ…иҜ»















- iQOO 7е®ҳж–№зҫҺеӣҫиөҸпјҡдёүз§Қй…ҚиүІгҖҒйҖҹеәҰзҫҺеӯҰи®ҫи®Ўдј жүҝ
- AIжҲҳз–«гҖҒзңҹ5GжқҘдәҶпјҢеҚҒеӨ§жңҖзғӯ门科жҠҖеә”з”Ёжј”з»ҺйҖҹеәҰдёҺжё©еәҰ
- йҰ–ж¬ҫ7GB/s SSDпјҒдёүжҳҹ980PRO 1TBиҜ„жөӢпјҡж°ёжҒ’зҡ„1.8GB/sзј“еӨ–еҶҷе…ҘйҖҹеәҰ
- е°Ҹзұі11 PK е°Ҹзұі10пјҡдј иҫ“йҖҹеәҰжҸҗеҚҮ1.6еҖҚ
- 4GйҖҹеәҰеҸҳж…ўпјҹиҝҗиҗҘе•Ҷиҝҷжіўж“ҚдҪңпјҢи®©5Gз§’еҸҳвҖңзңҹйҰҷзҺ°еңәвҖқ
- 专家д»Ӣз»ҚеҰӮдҪ•еҲӨж–ӯжҷәиғҪжүӢжңәиў«е…ҘдҫөпјҡиҝҗиЎҢйҖҹеәҰеҸҳж…ўгҖҒз”өжұ ж¶ҲиҖ—иҝҮеҝ«д»ҘеҸҠеҚЎйЎҝ
- 马еҢ–и…ҫиҝҷжӢӣеӨӘй«ҳжҳҺпјҒзҪ‘еҸӢпјҡеҸӘиҰҒжҲ‘ж”№еҗҚзҡ„йҖҹеәҰеӨҹеҝ«пјҢзҰҒд»Өе°ұиҝҪдёҚдёҠжҲ‘
- жҖҺж ·жҸҗй«ҳиӢ№жһң6зҡ„иҝҗиЎҢйҖҹеәҰпјҹжңүиҝҷдәӣй—®йўҳе°ұеҲ«ж•‘дәҶпјҢдҪ з”ЁдәҶеҮ е№ҙдәҶпјҹ
- з”ЁжҲ·|4GйҖҹеәҰж…ўдәҶпјҒ5Gд№ҹйҡҫйҖғвҖңзңҹйҰҷе®ҡеҫӢвҖқ
- еҒҘеә·е®қпјҢдҝқеҒҘеә·дёҚдҝқйҡҗз§Ғпјҹ