- MySql+Memcachedжһ¶жһ„зҡ„й—®йўҳ
е®һйҷ…MySQLжҳҜйҖӮеҗҲиҝӣиЎҢжө·йҮҸж•°жҚ®еӯҳеӮЁзҡ„ пјҢ йҖҡиҝҮMemcachedе°ҶзғӯзӮ№ж•°жҚ®еҠ иҪҪеҲ°cache пјҢ еҠ йҖҹи®ҝй—® пјҢ еҫҲеӨҡе…¬еҸёйғҪжӣҫз»ҸдҪҝз”ЁиҝҮиҝҷж ·зҡ„жһ¶жһ„ пјҢ дҪҶйҡҸзқҖдёҡеҠЎж•°жҚ®йҮҸзҡ„дёҚж–ӯеўһеҠ пјҢ е’Ңи®ҝй—®йҮҸзҡ„жҢҒз»ӯеўһй•ҝ пјҢ жҲ‘们йҒҮеҲ°дәҶеҫҲеӨҡй—®йўҳпјҡ1.MySQLйңҖиҰҒдёҚж–ӯиҝӣиЎҢжӢҶеә“жӢҶиЎЁ пјҢ Memcachedд№ҹйңҖдёҚж–ӯи·ҹзқҖжү©е®№ пјҢ жү©е®№е’Ңз»ҙжҠӨе·ҘдҪңеҚ жҚ®еӨ§йҮҸејҖеҸ‘ж—¶й—ҙ гҖӮ2.MemcachedдёҺMySQLж•°жҚ®еә“ж•°жҚ®дёҖиҮҙжҖ§й—®йўҳ гҖӮ3.Memcachedж•°жҚ®е‘ҪдёӯзҺҮдҪҺжҲ–downжңә пјҢ еӨ§йҮҸи®ҝй—®зӣҙжҺҘз©ҝйҖҸеҲ°DB пјҢ MySQLж— жі•ж”Ҝж’‘ гҖӮ4.и·ЁжңәжҲҝcacheеҗҢжӯҘй—®йўҳ гҖӮдј—еӨҡNoSQLзҷҫиҠұйҪҗж”ҫ пјҢ еҰӮдҪ•йҖүжӢ©жңҖиҝ‘еҮ е№ҙ пјҢ дёҡз•ҢдёҚж–ӯж¶ҢзҺ°еҮәеҫҲеӨҡеҗ„з§Қеҗ„ж ·зҡ„NoSQLдә§е“Ғ пјҢ йӮЈд№ҲеҰӮдҪ•жүҚиғҪжӯЈзЎ®ең°дҪҝз”ЁеҘҪиҝҷдәӣдә§е“Ғ пјҢ жңҖеӨ§еҢ–ең°еҸ‘жҢҘе…¶й•ҝеӨ„ пјҢ жҳҜжҲ‘们йңҖиҰҒж·ұе…Ҙз ”з©¶е’ҢжҖқиҖғзҡ„й—®йўҳ пјҢ е®һйҷ…еҪ’ж №з»“еә•жңҖйҮҚиҰҒзҡ„жҳҜдәҶи§Јиҝҷдәӣдә§е“Ғзҡ„е®ҡдҪҚ пјҢ 并且дәҶи§ЈеҲ°жҜҸж¬ҫдә§е“Ғзҡ„tradeoffs пјҢ еңЁе®һйҷ…еә”з”ЁдёӯеҒҡеҲ°жү¬й•ҝйҒҝзҹӯ пјҢ жҖ»дҪ“дёҠиҝҷдәӣNoSQLдё»иҰҒз”ЁдәҺи§ЈеҶід»ҘдёӢеҮ з§Қй—®йўҳ1.е°‘йҮҸж•°жҚ®еӯҳеӮЁ пјҢ й«ҳйҖҹиҜ»еҶҷи®ҝй—® гҖӮ жӯӨзұ»дә§е“ҒйҖҡиҝҮж•°жҚ®е…ЁйғЁin-momery зҡ„ж–№ејҸжқҘдҝқиҜҒй«ҳйҖҹи®ҝй—® пјҢ еҗҢж—¶жҸҗдҫӣж•°жҚ®иҗҪең°зҡ„еҠҹиғҪ пјҢ е®һйҷ…иҝҷжӯЈжҳҜRedisжңҖдё»иҰҒзҡ„йҖӮз”ЁеңәжҷҜ гҖӮ2.жө·йҮҸж•°жҚ®еӯҳеӮЁ пјҢ еҲҶеёғејҸзі»з»ҹж”ҜжҢҒ пјҢ ж•°жҚ®дёҖиҮҙжҖ§дҝқиҜҒ пјҢ ж–№дҫҝзҡ„йӣҶзҫӨиҠӮзӮ№ж·»еҠ /еҲ йҷӨ гҖӮ3.иҝҷж–№йқўжңҖе…·д»ЈиЎЁжҖ§зҡ„жҳҜdynamoе’Ңbigtable 2зҜҮи®әж–ҮжүҖйҳҗиҝ°зҡ„жҖқи·Ҝ гҖӮ еүҚиҖ…жҳҜдёҖдёӘе®Ңе…Ёж— дёӯеҝғзҡ„и®ҫи®Ў пјҢ иҠӮзӮ№д№Ӣй—ҙйҖҡиҝҮgossipж–№ејҸдј йҖ’йӣҶзҫӨдҝЎжҒҜ пјҢ ж•°жҚ®дҝқиҜҒжңҖз»ҲдёҖиҮҙжҖ§ пјҢ еҗҺиҖ…жҳҜдёҖдёӘдёӯеҝғеҢ–зҡ„ж–№жЎҲи®ҫи®Ў пјҢ йҖҡиҝҮзұ»дјјдёҖдёӘеҲҶеёғејҸй”ҒжңҚеҠЎжқҘдҝқиҜҒе°ҶдёҖиҮҙжҖ§,ж•°жҚ®еҶҷе…Ҙе…ҲеҶҷеҶ…еӯҳе’Ңredo log пјҢ 然еҗҺе®ҡжңҹcompatеҪ’并еҲ°зЈҒзӣҳдёҠ пјҢ е°ҶйҡҸжңәеҶҷдјҳеҢ–дёәйЎәеәҸеҶҷ пјҢ жҸҗй«ҳеҶҷе…ҘжҖ§иғҪ гҖӮ4.Schema free пјҢ auto-shardingзӯү гҖӮ жҜ”еҰӮзӣ®еүҚеёёи§Ғзҡ„дёҖдәӣж–ҮжЎЈж•°жҚ®еә“йғҪжҳҜж”ҜжҢҒschema-freeзҡ„ пјҢ зӣҙжҺҘеӯҳеӮЁjsonж јејҸж•°жҚ® пјҢ 并且ж”ҜжҢҒauto-shardingзӯүеҠҹиғҪ пјҢ жҜ”еҰӮmongodb гҖӮйқўеҜ№иҝҷдәӣдёҚеҗҢзұ»еһӢзҡ„NoSQLдә§е“Ғ,жҲ‘们йңҖиҰҒж №жҚ®жҲ‘们зҡ„дёҡеҠЎеңәжҷҜйҖүжӢ©жңҖеҗҲйҖӮзҡ„дә§е“Ғ гҖӮ RedisжңҖйҖӮеҗҲжүҖжңүж•°жҚ®in-momoryзҡ„еңәжҷҜ пјҢ иҷҪ然Redisд№ҹжҸҗдҫӣжҢҒд№…еҢ–еҠҹиғҪ пјҢ дҪҶе®һйҷ…жӣҙеӨҡзҡ„жҳҜдёҖдёӘdisk-backedзҡ„еҠҹиғҪ пјҢ и·ҹдј з»ҹж„Ҹд№үдёҠзҡ„жҢҒд№…еҢ–жңүжҜ”иҫғеӨ§зҡ„е·®еҲ« пјҢ йӮЈд№ҲеҸҜиғҪеӨ§е®¶е°ұдјҡжңүз–‘й—® пјҢ дјјд№ҺRedisжӣҙеғҸдёҖдёӘеҠ ејәзүҲзҡ„Memcached пјҢ йӮЈд№ҲдҪ•ж—¶дҪҝз”ЁMemcached,дҪ•ж—¶дҪҝз”ЁRedisе‘ў?еҰӮжһңз®ҖеҚ•ең°жҜ”иҫғRedisдёҺMemcachedзҡ„еҢәеҲ« пјҢ еӨ§еӨҡж•°йғҪдјҡеҫ—еҲ°д»ҘдёӢи§ӮзӮ№пјҡ1 гҖҒRedisдёҚд»…д»…ж”ҜжҢҒз®ҖеҚ•зҡ„k/vзұ»еһӢзҡ„ж•°жҚ® пјҢ еҗҢж—¶иҝҳжҸҗдҫӣlist пјҢ set пјҢ zset пјҢ hashзӯүж•°жҚ®з»“жһ„зҡ„еӯҳеӮЁ гҖӮ2 гҖҒRedisж”ҜжҢҒж•°жҚ®зҡ„еӨҮд»Ҫ пјҢ еҚіmaster-slaveжЁЎејҸзҡ„ж•°жҚ®еӨҮд»Ҫ гҖӮ3 гҖҒRedisж”ҜжҢҒж•°жҚ®зҡ„жҢҒд№…еҢ– пјҢ еҸҜд»Ҙе°ҶеҶ…еӯҳдёӯзҡ„ж•°жҚ®дҝқжҢҒеңЁзЈҒзӣҳдёӯ пјҢ йҮҚеҗҜзҡ„ж—¶еҖҷеҸҜд»ҘеҶҚж¬ЎеҠ иҪҪиҝӣиЎҢдҪҝз”Ё гҖӮ
- Redisеёёз”Ёж•°жҚ®зұ»еһӢRedisжңҖдёәеёёз”Ёзҡ„ж•°жҚ®зұ»еһӢдё»иҰҒжңүд»ҘдёӢпјҡString
гҖҗredis ж•°жҚ®зұ»еһӢиҜҰи§Ј д»ҘеҸҠ redisйҖӮз”ЁеңәжҷҜеңәеҗҲгҖ‘Hash
List
Set
Sorted set
pub/sub
Transactions
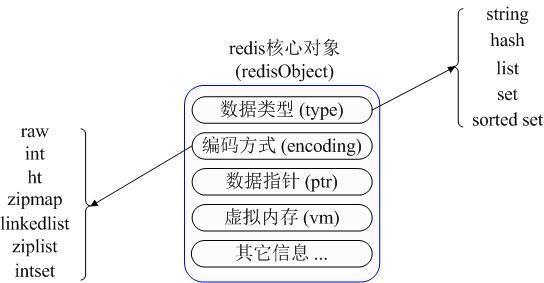
еңЁе…·дҪ“жҸҸиҝ°иҝҷеҮ з§Қж•°жҚ®зұ»еһӢд№ӢеүҚ пјҢ жҲ‘们е…ҲйҖҡиҝҮдёҖеј еӣҫдәҶи§ЈдёӢRedisеҶ…йғЁеҶ…еӯҳз®ЎзҗҶдёӯжҳҜеҰӮдҪ•жҸҸиҝ°иҝҷдәӣдёҚеҗҢж•°жҚ®зұ»еһӢзҡ„пјҡ
ж–Үз« жҸ’еӣҫ
йҰ–е…ҲRedisеҶ…йғЁдҪҝз”ЁдёҖдёӘredisObjectеҜ№иұЎжқҘиЎЁзӨәжүҖжңүзҡ„keyе’Ңvalue,redisObjectжңҖдё»иҰҒзҡ„дҝЎжҒҜеҰӮдёҠеӣҫжүҖзӨәпјҡtypeд»ЈиЎЁдёҖдёӘvalueеҜ№иұЎе…·дҪ“жҳҜдҪ•з§Қж•°жҚ®зұ»еһӢ пјҢ encodingжҳҜдёҚеҗҢж•°жҚ®зұ»еһӢеңЁredisеҶ…йғЁзҡ„еӯҳеӮЁж–№ејҸ пјҢ жҜ”еҰӮпјҡtype=stringд»ЈиЎЁvalueеӯҳеӮЁзҡ„жҳҜдёҖдёӘжҷ®йҖҡеӯ—з¬ҰдёІ пјҢ йӮЈд№ҲеҜ№еә”зҡ„encodingеҸҜд»ҘжҳҜrawжҲ–иҖ…жҳҜint,еҰӮжһңжҳҜintеҲҷд»ЈиЎЁе®һйҷ…redisеҶ…йғЁжҳҜжҢүж•°еҖјеһӢзұ»еӯҳеӮЁе’ҢиЎЁзӨәиҝҷдёӘеӯ—з¬ҰдёІзҡ„ пјҢ еҪ“然еүҚжҸҗжҳҜиҝҷдёӘеӯ—з¬ҰдёІжң¬иә«еҸҜд»Ҙз”Ёж•°еҖјиЎЁзӨә пјҢ жҜ”еҰӮ:"123" "456"иҝҷж ·зҡ„еӯ—з¬ҰдёІ гҖӮ иҝҷйҮҢйңҖиҰҒзү№ж®ҠиҜҙжҳҺдёҖдёӢvmеӯ—ж®ө пјҢ еҸӘжңүжү“ејҖдәҶRedisзҡ„иҷҡжӢҹеҶ…еӯҳеҠҹиғҪ пјҢ жӯӨеӯ—ж®өжүҚдјҡзңҹжӯЈзҡ„еҲҶй…ҚеҶ…еӯҳ пјҢ иҜҘеҠҹиғҪй»ҳи®ӨжҳҜе…ій—ӯзҠ¶жҖҒзҡ„ пјҢ иҜҘеҠҹиғҪдјҡеңЁеҗҺйқўе…·дҪ“жҸҸиҝ° гҖӮ йҖҡиҝҮдёҠеӣҫжҲ‘们еҸҜд»ҘеҸ‘зҺ°RedisдҪҝз”ЁredisObjectжқҘиЎЁзӨәжүҖжңүзҡ„key/valueж•°жҚ®жҳҜжҜ”иҫғжөӘиҙ№еҶ…еӯҳзҡ„ пјҢ еҪ“然иҝҷдәӣеҶ…еӯҳз®ЎзҗҶжҲҗжң¬зҡ„д»ҳеҮәдё»иҰҒд№ҹжҳҜдёәдәҶз»ҷRedisдёҚеҗҢж•°жҚ®зұ»еһӢжҸҗдҫӣдёҖдёӘз»ҹдёҖзҡ„з®ЎзҗҶжҺҘеҸЈ пјҢ е®һйҷ…дҪңиҖ…д№ҹжҸҗдҫӣдәҶеӨҡз§Қж–№жі•её®еҠ©жҲ‘们е°ҪйҮҸиҠӮзңҒеҶ…еӯҳдҪҝз”Ё пјҢ жҲ‘们йҡҸеҗҺдјҡе…·дҪ“и®Ёи®ә гҖӮ
жҺЁиҚҗйҳ…иҜ»
-
Intel|12д»Јй…·зқҝеҚҮзә§LGA1700жҸ’ж§Ҫ зҪ‘еҸӢе®һйҷ…ж•°дәҶдёҖйҒҚпјҡзңҹжҳҜ1700дёӘй’Ҳи„ҡ
-
е°ҸзұіжүӢзҺҜ4|8еӨ©еҮәиҙ§йҮҸ100дёҮж”ҜпјҒе°ҸзұіжүӢзҺҜ4жҲҗе…ЁзҗғжңҖз•…й”ҖжүӢзҺҜ
-
жұҹиӢҸеҚ«и§Ҷ|еҢ—дә¬еҚ«и§Ҷе’ҢжұҹиӢҸеҚ«и§ҶиҒ”ж’ӯпјҢжң¬д»Ҙдёәиҝҷеү§дјҡзҒ«пјҢз»“жһң收и§ҶиЎЁзҺ°еҮәд№Һж„Ҹж–ҷ
-
гҖҢеҚҒжёЎиҪҰзҘһгҖҚе№іиЎҢиҝӣеҸЈиҪҰз»ҸеҺҶз”ҹжӯ»еӨ§иҖғ
-
жҪ®жөҒе°ҡжӢҚзІҫйҖү|иҝҳжҳҜз©ҝеҫ—вҖңз®ҖзәҰйЈҺвҖқдәӣжӣҙеё…ж°”пјҢз”·з”ҹиЎ¬иЎ«
-
зәўиҢ¶жҳҜз…®иҝҳжҳҜжіЎ,еІ©иҢ¶д№ҹжҳҜжҷ®жҙұиҢ¶еҸҜд»Ҙз…®
-
еҰӮжӯҢеІҒжңҲ|д»»жӯЈйқһи°ҲжұҪиҪҰиҮӘдё»еҲӣж–°пјҡжҲ‘дёҚеҸҚеҜ№жқҺд№ҰзҰҸпјҒзҪ‘еҸӢпјҡеҸ‘еҠЁжңәдёҚйҮҚиҰҒеҗ—пјҹ
-
ChristteCYChuaе…ёйӣ…еӨӘ|жқЁе№ӮеҫҲжҢ‘йЈҹпјҢеҗҙеҪҰзҘ–жҺҘең°ж°”пјҢзңӢеҲ°еҗҙдә¬пјҡиҰҒдёҚпјҢеҪ“жҳҺжҳҹ们еңЁзүҮеңәеҗғйҘӯ
-
жёёжҲҸе°ҸжҖӘе…Ҫ|зҺӢиҖ…иҚЈиҖҖпјҡжүӢж®Ӣж„ҸиҜҶеҘҪпјҹйӮЈе°ұйҖүжӢ©иҝҷдәӣиӢұйӣ„дёҠеҲҶеҗ§
-
еӨҡзү№дҪ“иӮІ|е®Ҹиҝңжү“вҖңйҮҺзҗғвҖқзӢӮиғң150еҲҶпјҒеӣҪ家йҳҹж¬әиҙҹйқ’е№ҙйҳҹпјҢжқңй”ӢзңҹдёҚз»ҷйқўеӯҗ
-
#жҳҹеә§еҗ¬иҜӯ#з—ҙжғ…зң·жҒӢпјҢйҡҫд»ҘиҲҚејғпјҢ3жҳҹеә§дёҚеҶҚйҖҖзј©пјҢжҢҪеӣһж—§зҲұеҶҚзӣёе®ҲпјҢ5жңҲдёӢж—¬
-
зәөзӣёж–°й—»|иҘҝеӘ’й«ҳе‘ј"дёӯеӣҪеёӮеңәеҫҲзҘһеҘҮ"пјҢе“ҲиҗЁе…Ӣж–ҜеқҰз§°дёӯеӣҪиҝӣеҚҡдјҡд»ЈиЎЁдәҶзЁіе®ҡе’Ңеҗёеј•еҠӣ | еӨ–еӘ’зңӢиҝӣеҚҡ
-
йқ’еІ©жўҰзҪў|дёҒеҪ“иҠӮзӣ®жҺҘй•ҝеҸ‘пјҢжң¬д»Ҙдёәж•ҲжһңдёҖиҲ¬пјҢзңӢжё…ж•ҲжһңеҗҺпјҢзІүдёқйғҪеҝ«и®ӨдёҚеҮәдәҶ
-
[з»ҝиұҶ]з”·дәәжғіиҰҒй•ҝеҜҝпјҢ5件вҖңиҖ—йҳівҖқзҡ„дәӢиҰҒвҖңиҲҚејғвҖқпјҢдёҖдәӣдәәиЎЁзӨәеҫҲйҡҫеҒҡеҲ°
-
йўҶеҜјжү“еҺӢдёӢеұһпјҢжңҖеёёз”Ёиҝҷдә”з§ҚжүӢж®өпјҢдёҖжӢӣжҜ”дёҖжӢӣжҜ’
-
гҖҢгҖҚеј жқ°зҡ„дёҖйҰ–жӯҢ, з«ҹжҲҗй«ҳиҖғзҘһжӣІ, зҪ‘еҸӢ: зӮ№зҮғж— ж•°й«ҳиҖғеӯҰз”ҹзҡ„жҝҖжғ…
-
жҷҙжҷҙдҫғжёёжҲҸ|еҶҚд№ҹдёҚжҖ•еҲҡжһӘпјҢе’Ңе№ізІҫиӢұпјҡдё»еүҜжӯҰеҷЁжҖҺд№ҲйҖүпјҹжңҖе®һз”Ёзҡ„жҗӯй…Қ
-
з»“еұҖ|дёӯеӣҪеҸӨд»Је”ҜдёҖеҘізҠ¶е…ғпјҢжүҚиІҢеҸҢе…Ёе®ҳеұ…дёһзӣёпјҢеҚҙжҲҗд»–дәәзӮ№еҝғпјҢз»“еұҖжӮІжғЁ
-
дёҠи§Ӯж–°й—»|收еҲ°вҖңиҖҒжқҝвҖқжҢҮд»ӨиҪ¬иҙҰжұҮж¬ҫпјҹиҰҒеҪ“еҝғдәҶпјҒеҶ’е……иҖҒжқҝйӘ—еұҖеҶҚж¬ЎеҚ·еңҹйҮҚжқҘ
-
жқҺе°Ҹз’җйҖҒй—әиңң1599жңөзҺ«з‘°|жӮЈйҡҫи§Ғзңҹжғ…!жқҺе°Ҹз’җйҖҒй—әиңң1599жңөзҺ«з‘° 1599жңөзҡ„еҜ“ж„ҸдәҶи§ЈдёӢ











![[з»ҝиұҶ]з”·дәәжғіиҰҒй•ҝеҜҝпјҢ5件вҖңиҖ—йҳівҖқзҡ„дәӢиҰҒвҖңиҲҚејғвҖқпјҢдёҖдәӣдәәиЎЁзӨәеҫҲйҡҫеҒҡеҲ°](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/26fa2bbcc60faf5ef39679c3f1999fd3.jpg)




