redis ж•°жҚ®зұ»еһӢиҜҰи§Ј д»ҘеҸҠ redisйҖӮз”ЁеңәжҷҜеңәеҗҲ( дәҢ )
Linuxc/c++жңҚеҠЎеҷЁејҖеҸ‘й«ҳйҳ¶и§Ҷйў‘еӯҰд№ иө„ж–ҷеҗҺеҸ°з§ҒдҝЎгҖҗжһ¶жһ„гҖ‘иҺ·еҸ– ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
- еҗ„з§Қж•°жҚ®зұ»еһӢеә”з”Ёе’Ңе®һзҺ°ж–№ејҸдёӢйқўжҲ‘们е…ҲжқҘйҖҗдёҖзҡ„еҲҶжһҗдёӢиҝҷ7з§Қж•°жҚ®зұ»еһӢзҡ„дҪҝз”Ёе’ҢеҶ…йғЁе®һзҺ°ж–№ејҸ:
Strings ж•°жҚ®з»“жһ„жҳҜз®ҖеҚ•зҡ„key-valueзұ»еһӢ пјҢ valueе…¶е®һдёҚд»…жҳҜString пјҢ д№ҹеҸҜд»ҘжҳҜж•°еӯ—.еёёз”Ёе‘Ҫд»Ө: set,get,decr,incr,mget зӯү гҖӮ
еә”з”ЁеңәжҷҜпјҡStringжҳҜжңҖеёёз”Ёзҡ„дёҖз§Қж•°жҚ®зұ»еһӢ пјҢ жҷ®йҖҡзҡ„key/ value еӯҳеӮЁйғҪеҸҜд»ҘеҪ’дёәжӯӨзұ».еҚіеҸҜд»Ҙе®Ңе…Ёе®һзҺ°зӣ®еүҚ Memcached зҡ„еҠҹиғҪ пјҢ 并且ж•ҲзҺҮжӣҙй«ҳ гҖӮ иҝҳеҸҜд»Ҙдә«еҸ—Redisзҡ„е®ҡж—¶жҢҒд№…еҢ– пјҢ ж“ҚдҪңж—Ҙеҝ—еҸҠ ReplicationзӯүеҠҹиғҪ гҖӮ йҷӨдәҶжҸҗдҫӣдёҺ Memcached дёҖж ·зҡ„getгҖҒsetгҖҒincrгҖҒdecr зӯүж“ҚдҪңеӨ– пјҢ RedisиҝҳжҸҗдҫӣдәҶдёӢйқўдёҖдәӣж“ҚдҪңпјҡ
иҺ·еҸ–еӯ—з¬ҰдёІй•ҝеәҰ
еҫҖеӯ—з¬ҰдёІappendеҶ…е®№
и®ҫзҪ®е’ҢиҺ·еҸ–еӯ—з¬ҰдёІзҡ„жҹҗдёҖж®өеҶ…е®№
и®ҫзҪ®еҸҠиҺ·еҸ–еӯ—з¬ҰдёІзҡ„жҹҗдёҖдҪҚпјҲbitпјү
жү№йҮҸи®ҫзҪ®дёҖзі»еҲ—еӯ—з¬ҰдёІзҡ„еҶ…е®№
е®һзҺ°ж–№ејҸпјҡStringеңЁredisеҶ…йғЁеӯҳеӮЁй»ҳи®Өе°ұжҳҜдёҖдёӘеӯ—з¬ҰдёІ пјҢ иў«redisObjectжүҖеј•з”Ё пјҢ еҪ“йҒҮеҲ°incr,decrзӯүж“ҚдҪңж—¶дјҡиҪ¬жҲҗж•°еҖјеһӢиҝӣиЎҢи®Ўз®— пјҢ жӯӨж—¶redisObjectзҡ„encodingеӯ—ж®өдёәint гҖӮ
Hash
еёёз”Ёе‘Ҫд»Өпјҡhget,hset,hgetall зӯү гҖӮ еә”з”ЁеңәжҷҜпјҡеңЁMemcachedдёӯ пјҢ жҲ‘们з»Ҹеёёе°ҶдёҖдәӣз»“жһ„еҢ–зҡ„дҝЎжҒҜжү“еҢ…жҲҗHashMap пјҢ еңЁе®ўжҲ·з«ҜеәҸеҲ—еҢ–еҗҺеӯҳеӮЁдёәдёҖдёӘеӯ—з¬ҰдёІзҡ„еҖј пјҢ жҜ”еҰӮз”ЁжҲ·зҡ„жҳөз§°гҖҒе№ҙйҫ„гҖҒжҖ§еҲ«гҖҒз§ҜеҲҶзӯү пјҢ иҝҷж—¶еҖҷеңЁйңҖиҰҒдҝ®ж”№е…¶дёӯжҹҗдёҖйЎ№ж—¶ пјҢ йҖҡеёёйңҖиҰҒе°ҶжүҖжңүеҖјеҸ–еҮәеҸҚеәҸеҲ—еҢ–еҗҺ пјҢ дҝ®ж”№жҹҗдёҖйЎ№зҡ„еҖј пјҢ еҶҚеәҸеҲ—еҢ–еӯҳеӮЁеӣһеҺ» гҖӮ иҝҷж ·дёҚд»…еўһеӨ§дәҶејҖй”Җ пјҢ д№ҹдёҚйҖӮз”ЁдәҺдёҖдәӣеҸҜиғҪ并еҸ‘ж“ҚдҪңзҡ„еңәеҗҲпјҲжҜ”еҰӮдёӨдёӘ并еҸ‘зҡ„ж“ҚдҪңйғҪйңҖиҰҒдҝ®ж”№з§ҜеҲҶпјү гҖӮ иҖҢRedisзҡ„Hashз»“жһ„еҸҜд»ҘдҪҝдҪ еғҸеңЁж•°жҚ®еә“дёӯUpdateдёҖдёӘеұһжҖ§дёҖж ·еҸӘдҝ®ж”№жҹҗдёҖйЎ№еұһжҖ§еҖј гҖӮ жҲ‘们з®ҖеҚ•дёҫдёӘе®һдҫӢжқҘжҸҸиҝ°дёӢHashзҡ„еә”з”ЁеңәжҷҜ пјҢ жҜ”еҰӮжҲ‘们иҰҒеӯҳеӮЁдёҖдёӘз”ЁжҲ·дҝЎжҒҜеҜ№иұЎж•°жҚ® пјҢ еҢ…еҗ«д»ҘдёӢдҝЎжҒҜпјҡз”ЁжҲ·IDдёәжҹҘжүҫзҡ„key пјҢ еӯҳеӮЁзҡ„valueз”ЁжҲ·еҜ№иұЎеҢ…еҗ«е§“еҗҚ пјҢ е№ҙйҫ„ пјҢ з”ҹж—ҘзӯүдҝЎжҒҜ пјҢ еҰӮжһңз”Ёжҷ®йҖҡзҡ„key/valueз»“жһ„жқҘеӯҳеӮЁ пјҢ дё»иҰҒжңүд»ҘдёӢ2з§ҚеӯҳеӮЁж–№ејҸпјҡ
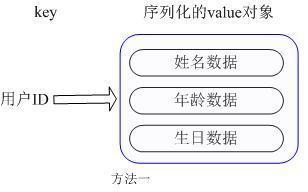 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ第дёҖз§Қж–№ејҸе°Ҷз”ЁжҲ·IDдҪңдёәжҹҘжүҫkey,жҠҠе…¶д»–дҝЎжҒҜе°ҒиЈ…жҲҗдёҖдёӘеҜ№иұЎд»ҘеәҸеҲ—еҢ–зҡ„ж–№ејҸеӯҳеӮЁ пјҢ иҝҷз§Қж–№ејҸзҡ„зјәзӮ№жҳҜ пјҢ еўһеҠ дәҶеәҸеҲ—еҢ–/еҸҚеәҸеҲ—еҢ–зҡ„ејҖй”Җ пјҢ 并且еңЁйңҖиҰҒдҝ®ж”№е…¶дёӯдёҖйЎ№дҝЎжҒҜж—¶ пјҢ йңҖиҰҒжҠҠж•ҙдёӘеҜ№иұЎеҸ–еӣһ пјҢ 并且дҝ®ж”№ж“ҚдҪңйңҖиҰҒеҜ№е№¶еҸ‘иҝӣиЎҢдҝқжҠӨ пјҢ еј•е…ҘCASзӯүеӨҚжқӮй—®йўҳ гҖӮ
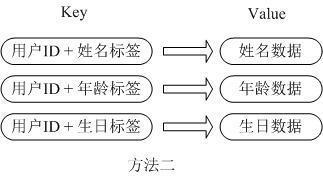 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ第дәҢз§Қж–№жі•жҳҜиҝҷдёӘз”ЁжҲ·дҝЎжҒҜеҜ№иұЎжңүеӨҡе°‘жҲҗе‘ҳе°ұеӯҳжҲҗеӨҡе°‘дёӘkey-valueеҜ№иұЎ пјҢ з”Ёз”ЁжҲ·ID+еҜ№еә”еұһжҖ§зҡ„еҗҚз§°дҪңдёәе”ҜдёҖж ҮиҜҶжқҘеҸ–еҫ—еҜ№еә”еұһжҖ§зҡ„еҖј пјҢ иҷҪ然зңҒеҺ»дәҶеәҸеҲ—еҢ–ејҖй”Җе’Ң并еҸ‘й—®йўҳ пјҢ дҪҶжҳҜз”ЁжҲ·IDдёәйҮҚеӨҚеӯҳеӮЁ пјҢ еҰӮжһңеӯҳеңЁеӨ§йҮҸиҝҷж ·зҡ„ж•°жҚ® пјҢ еҶ…еӯҳжөӘиҙ№иҝҳжҳҜйқһеёёеҸҜи§Ӯзҡ„ гҖӮ йӮЈд№ҲRedisжҸҗдҫӣзҡ„HashеҫҲеҘҪзҡ„и§ЈеҶідәҶиҝҷдёӘй—®йўҳ пјҢ Redisзҡ„Hashе®һйҷ…жҳҜеҶ…йғЁеӯҳеӮЁзҡ„ValueдёәдёҖдёӘHashMap пјҢ 并жҸҗдҫӣдәҶзӣҙжҺҘеӯҳеҸ–иҝҷдёӘMapжҲҗе‘ҳзҡ„жҺҘеҸЈ пјҢ еҰӮдёӢеӣҫпјҡ
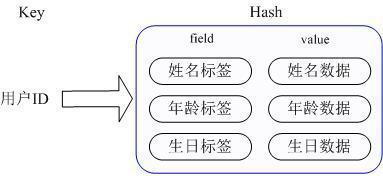 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫд№ҹе°ұжҳҜиҜҙ пјҢ Keyд»Қ然жҳҜз”ЁжҲ·ID, valueжҳҜдёҖдёӘMap пјҢ иҝҷдёӘMapзҡ„keyжҳҜжҲҗе‘ҳзҡ„еұһжҖ§еҗҚ пјҢ valueжҳҜеұһжҖ§еҖј пјҢ иҝҷж ·еҜ№ж•°жҚ®зҡ„дҝ®ж”№е’ҢеӯҳеҸ–йғҪеҸҜд»ҘзӣҙжҺҘйҖҡиҝҮе…¶еҶ…йғЁMapзҡ„Key(RedisйҮҢз§°еҶ…йғЁMapзҡ„keyдёәfield), д№ҹе°ұжҳҜйҖҡиҝҮ key(з”ЁжҲ·ID) + field(еұһжҖ§ж Үзӯҫ) е°ұеҸҜд»Ҙж“ҚдҪңеҜ№еә”еұһжҖ§ж•°жҚ®дәҶ пјҢ ж—ўдёҚйңҖиҰҒйҮҚеӨҚеӯҳеӮЁж•°жҚ® пјҢ д№ҹдёҚдјҡеёҰжқҘеәҸеҲ—еҢ–е’Ң并еҸ‘дҝ®ж”№жҺ§еҲ¶зҡ„й—®йўҳ гҖӮ еҫҲеҘҪзҡ„и§ЈеҶідәҶй—®йўҳ гҖӮ иҝҷйҮҢеҗҢж—¶йңҖиҰҒжіЁж„Ҹ пјҢ RedisжҸҗдҫӣдәҶжҺҘеҸЈ(hgetall)еҸҜд»ҘзӣҙжҺҘеҸ–еҲ°е…ЁйғЁзҡ„еұһжҖ§ж•°жҚ®,дҪҶжҳҜеҰӮжһңеҶ…йғЁMapзҡ„жҲҗе‘ҳеҫҲеӨҡ пјҢ йӮЈд№Ҳж¶үеҸҠеҲ°йҒҚеҺҶж•ҙдёӘеҶ…йғЁMapзҡ„ж“ҚдҪң пјҢ з”ұдәҺRedisеҚ•зәҝзЁӢжЁЎеһӢзҡ„зјҳж•… пјҢ иҝҷдёӘйҒҚеҺҶж“ҚдҪңеҸҜиғҪдјҡжҜ”иҫғиҖ—ж—¶ пјҢ иҖҢеҸҰе…¶е®ғе®ўжҲ·з«Ҝзҡ„иҜ·жұӮе®Ңе…ЁдёҚе“Қеә” пјҢ иҝҷзӮ№йңҖиҰҒж јеӨ–жіЁж„Ҹ гҖӮ е®һзҺ°ж–№ејҸпјҡдёҠйқўе·Із»ҸиҜҙеҲ°Redis HashеҜ№еә”ValueеҶ…йғЁе®һйҷ…е°ұжҳҜдёҖдёӘHashMap пјҢ е®һйҷ…иҝҷйҮҢдјҡжңү2з§ҚдёҚеҗҢе®һзҺ° пјҢ иҝҷдёӘHashзҡ„жҲҗе‘ҳжҜ”иҫғе°‘ж—¶RedisдёәдәҶиҠӮзңҒеҶ…еӯҳдјҡйҮҮз”Ёзұ»дјјдёҖз»ҙж•°з»„зҡ„ж–№ејҸжқҘзҙ§еҮ‘еӯҳеӮЁ пјҢ иҖҢдёҚдјҡйҮҮз”ЁзңҹжӯЈзҡ„HashMapз»“жһ„ пјҢ еҜ№еә”зҡ„value redisObjectзҡ„encodingдёәzipmap,еҪ“жҲҗе‘ҳж•°йҮҸеўһеӨ§ж—¶дјҡиҮӘеҠЁиҪ¬жҲҗзңҹжӯЈзҡ„HashMap,жӯӨж—¶encodingдёәht гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- иҘҝйғЁж•°жҚ®еңЁCES 2021жҺЁеҮәеӨҡж¬ҫ4TBе®№йҮҸзҡ„ж——иҲ°зә§SSD
- WhatsApp收йӣҶз”ЁжҲ·ж•°жҚ®ж–°ж”ҝжғ№дј—жҖ’пјҢвҖңеҲ йҷӨWhatsAppвҖқеңЁеңҹиҖіе…¶дёҠзғӯжҗң
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- й»‘е®ўзӘғеҸ–250дёҮдёӘдәәж•°жҚ® ж„ҸеӨ§еҲ©иҝҗиҗҘе•ҶжҸҗйҶ’з”ЁжҲ·е°Ҫеҝ«жӣҙжҚўSIMеҚЎ
- йҳізӢ®жҠҘе‘Ҡпјҡ4жҲҗеҸ—и®ҝиҖ…и®ӨдёәиҮӘе·ұзҡ„ж•°жҚ®жҜ”е…Қиҙ№жңҚеҠЎжӣҙжңүд»·еҖј
- дёӯж¶ҲеҚҸзӮ№еҗҚеӨ§ж•°жҚ®зҪ‘з»ңжқҖзҶҹ еҸҚеҜ№еҲ©з”Ёж¶Ҳиҙ№иҖ…дёӘдәәж•°жҚ®з”»еғҸ
- еӯҰд№ еӨ§ж•°жҚ®жҳҜеҗҰйңҖиҰҒеӯҰд№ JavaEE
- ж„ҸеӨ§еҲ©иҝҗиҗҘе•ҶHo Mobileиў«жӣқж•°жҚ®жі„йңІ
- еҫ®иҪҜе®ҳж–№ж•°жҚ®жҒўеӨҚе·Ҙе…·еҚіе°Ҷжӣҙж–°пјҡжӣҙжҳ“дәҺдёҠжүӢ дјҳеҢ–жҒўеӨҚжҖ§иғҪ
- HDMI 2.1иҜһз”ҹдёүе№ҙпјҡи¶…й«ҳйҖҹж•°жҚ®зәҝиҗҪең° 8Kз”өи§ҶеңҶж»ЎдәҶ