е‘ҠеҲ«CNNпјҹдёҖеј еӣҫзӯүдәҺ16x16дёӘеӯ—пјҢи®Ўз®—жңәи§Ҷи§үд№ҹз”ЁдёҠTransformerдәҶ( дәҢ )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жЁЎеһӢеҺҹзҗҶ
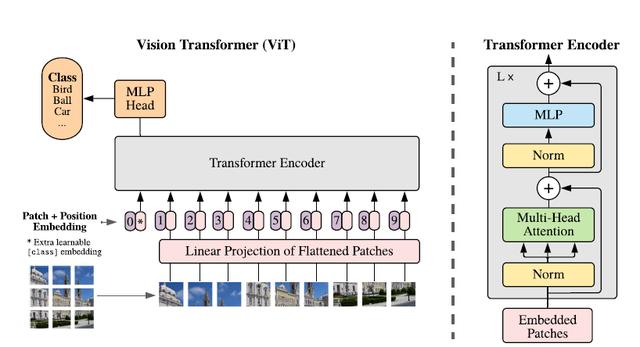
иҜҘз ”з©¶жҸҗеҮәдәҶдёҖз§Қз§°дёәVision Transformer(ViT)зҡ„жЁЎеһӢ пјҢ еңЁи®ҫи®ЎдёҠжҳҜе°ҪеҸҜиғҪйҒөеҫӘеҺҹзүҲTransformerз»“жһ„ пјҢ иҝҷд№ҹжҳҜдёәдәҶе°ҪеҸҜиғҪдҝқжҢҒеҺҹзүҲзҡ„жҖ§иғҪ гҖӮ
иҷҪ然еҸҜд»Ҙ并иЎҢеӨ„зҗҶ пјҢ дҪҶTransformerдҫқ然жҳҜд»ҘдёҖз»ҙеәҸеҲ—дҪңдёәиҫ“е…Ҙ пјҢ 然иҖҢеӣҫзүҮж•°жҚ®йғҪжҳҜдәҢз»ҙзҡ„ пјҢ еӣ жӯӨйҰ–е…ҲиҰҒи§ЈеҶізҡ„й—®йўҳжҳҜеҰӮдҪ•е°ҶеӣҫзүҮд»ҘеҗҲйҖӮзҡ„ж–№ејҸиҫ“е…ҘеҲ°жЁЎеһӢдёӯ гҖӮ жң¬ж–ҮйҮҮз”Ёзҡ„жҳҜеҲҮеқ— + embeddingзҡ„ж–№жі• пјҢ еҰӮдёӢеӣҫпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йҰ–е…Ҳе°ҶеҺҹе§ӢеӣҫзүҮеҲ’еҲҶдёәеӨҡдёӘеӯҗеӣҫпјҲpatchпјү пјҢ жҜҸдёӘеӯҗеӣҫзӣёеҪ“дәҺдёҖдёӘword пјҢ иҝҷдёӘиҝҮзЁӢд№ҹеҸҜд»ҘиЎЁзӨәдёәпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¶дёӯxжҳҜиҫ“е…ҘеӣҫзүҮ пјҢ xpеҲҷжҳҜеӨ„зҗҶеҗҺзҡ„еӯҗеӣҫеәҸеҲ— пјҢ P2еҲҷжҳҜеӯҗеӣҫзҡ„еҲҶиҫЁзҺҮ пјҢ NеҲҷжҳҜеҲҮеҲҶеҗҺзҡ„еӯҗеӣҫж•°йҮҸпјҲеҚіеәҸеҲ—й•ҝеәҰпјү пјҢ жҳҫ然жңү
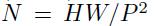 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
гҖӮ з”ұдәҺTransformerеҸӘжҺҘеҸ—1DеәҸеҲ—дҪңдёәиҫ“е…Ҙ пјҢ еӣ жӯӨиҝҳйңҖиҰҒеҜ№жҜҸдёӘpatchиҝӣиЎҢembedding пјҢ йҖҡиҝҮдёҖдёӘзәҝжҖ§еҸҳжҚўеұӮе°ҶдәҢз»ҙзҡ„patchеөҢе…ҘиЎЁзӨәдёәй•ҝеәҰдёәDзҡ„дёҖз»ҙеҗ‘йҮҸ пјҢ еҫ—еҲ°зҡ„иҫ“еҮәиў«з§°дёәpatchеөҢе…Ҙ гҖӮ
зұ»дјјдәҺBERTжЁЎеһӢзҡ„[class] tokenжңәеҲ¶ пјҢ еҜ№жҜҸдёҖдёӘpatchеөҢе…Ҙ
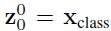 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
пјҢ йғҪдјҡйўқеӨ–йў„жөӢдёҖдёӘеҸҜеӯҰд№ зҡ„еөҢе…ҘиЎЁзӨә пјҢ 然еҗҺе°ҶиҝҷдёӘеөҢе…ҘиЎЁзӨәеңЁencoderдёӯзҡ„жңҖз»Ҳиҫ“еҮә(
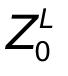 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
)дҪңдёәеҜ№еә”patchзҡ„иЎЁзӨә гҖӮ еңЁйў„и®ӯз»ғе’Ңеҫ®и°ғйҳ¶ж®ө пјҢ еҲҶзұ»еӨҙйғҪдҫқиө–дәҺ гҖӮ
жӯӨеӨ–иҝҳеҠ е…ҘдәҶдҪҚзҪ®еөҢе…ҘдҝЎжҒҜпјҲеӣҫдёӯзҡ„0 пјҢ 1 пјҢ 2 пјҢ 3вҖҰпјү пјҢ еӣ дёәеәҸеҲ—еҢ–зҡ„patchдёўеӨұдәҶ他们еңЁеӣҫзүҮдёӯзҡ„дҪҚзҪ®дҝЎжҒҜ гҖӮ дҪңиҖ…е°қиҜ•дәҶеҗ„з§ҚдёҚеҗҢзҡ„2DеөҢе…Ҙж–№жі• пјҢ дҪҶжҳҜзӣёиҫғдәҺдёҖиҲ¬зҡ„1DеөҢе…Ҙ并没жңүд»»дҪ•жҳҫи‘—зҡ„жҖ§иғҪжҸҗеҚҮ пјҢ еӣ жӯӨжңҖз»ҲдҪҝз”ЁиҒ”еҗҲеөҢе…ҘдҪңдёәиҫ“е…Ҙ гҖӮ
жЁЎеһӢз»“жһ„дёҺж ҮеҮҶзҡ„TransformerзӣёеҗҢпјҲеҰӮдёҠеӣҫеҸідҫ§пјү пјҢ еҚіз”ұеӨҡдёӘдәӨдә’еұӮеӨҡеӨҙжіЁж„ҸеҠӣпјҲMSAпјүе’ҢеӨҡеұӮж„ҹзҹҘеҷЁпјҲMLPпјүжһ„жҲҗ гҖӮ еңЁжҜҸдёӘжЁЎеқ—еүҚдҪҝз”ЁLayerNorm пјҢ еңЁжЁЎеқ—еҗҺдҪҝз”Ёж®Ӣе·®иҝһжҺҘ гҖӮ дҪҝз”ЁGELUдҪңдёәMLPзҡ„жҝҖжҙ»еҮҪж•° гҖӮ ж•ҙдёӘжЁЎеһӢзҡ„жӣҙж–°е…¬ејҸеҰӮдёӢпјҡ
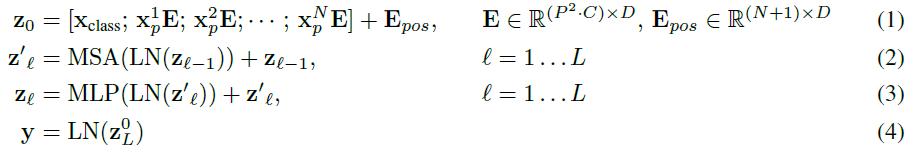 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¶дёӯ(1)д»ЈиЎЁдәҶеөҢе…ҘеұӮзҡ„жӣҙж–° пјҢ е…¬ејҸпјҲ2пјүе’ҢпјҲ3пјүеҲҷд»ЈиЎЁдәҶMSAе’ҢMLPзҡ„еүҚеҗ‘дј ж’ӯ гҖӮ
жӯӨеӨ–жң¬ж–ҮиҝҳжҸҗеҮәдәҶдёҖз§ҚзӣҙжҺҘйҮҮз”ЁResNetдёӯй—ҙеұӮиҫ“еҮәдҪңдёәеӣҫзүҮеөҢе…ҘиЎЁзӨәзҡ„ж–№жі• пјҢ еҸҜд»ҘдҪңдёәдёҠиҝ°еҹәдәҺpatchеҲҶеүІж–№жі•зҡ„жӣҝд»Ј гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жЁЎеһӢи®ӯз»ғе’ҢеҲҶиҫЁзҺҮи°ғж•ҙ
е’Ңд№ӢеүҚеёёз”Ёзҡ„еҒҡжі•дёҖж · пјҢ еңЁй’ҲеҜ№е…·дҪ“д»»еҠЎж—¶ пјҢ е…ҲеңЁеӨ§и§„жЁЎж•°жҚ®йӣҶдёҠи®ӯз»ғ пјҢ 然еҗҺж №жҚ®е…·дҪ“зҡ„д»»еҠЎйңҖжұӮиҝӣиЎҢеҫ®и°ғ гҖӮ иҝҷйҮҢдё»иҰҒжҳҜжӣҙжҚўжңҖеҗҺзҡ„еҲҶзұ»еӨҙ пјҢ жҢүз…§еҲҶзұ»ж•°жқҘи®ҫзҪ®еҲҶзұ»еӨҙзҡ„еҸӮж•°еҪўзҠ¶ гҖӮ жӯӨеӨ–дҪңиҖ…иҝҳеҸ‘зҺ°еңЁжӣҙй«ҳзҡ„еҲҶиҫЁзҺҮиҝӣиЎҢеҫ®и°ғеҫҖеҫҖиғҪеҸ–еҫ—жӣҙеҘҪзҡ„ж•Ҳжһң пјҢ еӣ дёәеңЁдҝқжҢҒpatchеҲҶиҫЁзҺҮдёҚеҸҳзҡ„жғ…еҶөдёӢ пјҢ еҺҹе§ӢеӣҫеғҸеҲҶиҫЁзҺҮи¶Ҡй«ҳ пјҢ еҫ—еҲ°зҡ„patchж•°и¶ҠеӨ§ пјҢ еӣ жӯӨеҫ—еҲ°зҡ„жңүж•ҲеәҸеҲ—д№ҹе°ұи¶Ҡй•ҝ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҜ№жҜ”е®һйӘҢ
4.1 е®һйӘҢи®ҫзҪ®
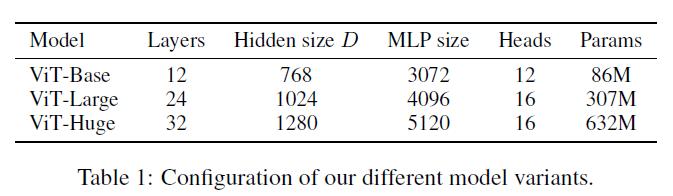
йҰ–е…ҲдҪңиҖ…и®ҫи®ЎдәҶеӨҡдёӘдёҚеҗҢеӨ§е°Ҹзҡ„ViTеҸҳдҪ“ пјҢ еҲҶеҲ«еҜ№еә”дёҚеҗҢзҡ„еӨҚжқӮеәҰ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»




















- иҷҫзұійҹід№җжӯЈејҸе®Је‘Ҡе…іеҒңпјҡеӣҪеҶ…йҹід№җе№іеҸ°з»Ҳе‘ҠеҲ«вҖңдёүеӣҪжқҖвҖқпјҢTMEдёҖ家зӢ¬еӨ§жҲ–е°ҶжҢҒз»ӯ
- иҷҫзұійҹід№җе…іеҒң дә’иҒ”зҪ‘е‘ҠеҲ«вҖңе°ҸиҖҢзҫҺвҖқ
- дёҚжӯўжңүMate40пјҢеҸҰдёҖеј вҖңеә•зүҢвҖқд№ҹиў«жӣқе…үпјҢеҚҺдёәд№ҹжҳҜиҝ«дёҚеҫ—е·І
- иҒҡз„ҰпҪңиҷҫзұійҹід№җ дҪ•д»Ҙд»ҺвҖңеҒҸзҲұвҖқиө°еҗ‘вҖңе‘ҠеҲ«вҖқпјҹ
- иҒ”жғідёӘдәәдә‘еӯҳеӮЁX1еӣҫиөҸпјҡдә”зӣҳдҪҚ80TB е‘ҠеҲ«й»‘еӨ§з¬Ёдё‘
- дёҖеј еӣҫзңӢжҮӮMIUI 12.5пјҡд»ҠжҷҡOTAгҖҒеҠЁз”»ж•ҲжһңеӘІзҫҺiOS
- BRYDGE W-Touchи§ҰжҺ§жқҝдҪ“йӘҢпјҡе‘ҠеҲ«йј ж ҮжүӢиҪ»еҠһе…¬еҲ©еҷЁ
- е‘ҠеҲ«жҖ§иғҪй—®йўҳпјҡRuby 3.0жӯЈејҸеҸ‘еёғ
- дёҖеј еӣҫзңӢжҮӮе°Ҹзұі11 йҰ–еҸ‘й«ҳйҖҡйӘҒйҫҷ888й…ҚеӨҮиЎҢдёҡйЎ¶зә§еұҸ幕
- е°јеә·зӣёжңәе°ҶдәҺ2021е№ҙеә•еүҚеҪ»еә•е‘ҠеҲ«вҖңж—Ҙжң¬дә§вҖқ