е‘ҠеҲ«CNNпјҹдёҖеј еӣҫзӯүдәҺ16x16дёӘеӯ—пјҢи®Ўз®—жңәи§Ҷи§үд№ҹз”ЁдёҠTransformerдәҶ( дёү )
ж•°жҚ®йӣҶдё»иҰҒдҪҝз”ЁILSVRC-2012 пјҢ ImageNet-21K пјҢ д»ҘеҸҠJFTж•°жҚ®йӣҶ гҖӮ
4.2 дёҺSOTAжЁЎеһӢзҡ„жҖ§иғҪеҜ№жҜ”
йҰ–е…ҲжҳҜе’ҢResNetд»ҘеҸҠefficientNetзҡ„еҜ№жҜ” пјҢ иҝҷдёӨдёӘжЁЎеһӢйғҪжҳҜжҜ”иҫғжңүд»ЈиЎЁзҡ„еҹәдәҺCNNзҡ„жЁЎеһӢ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¶дёӯViTжЁЎеһӢйғҪжҳҜеңЁJFT-300Mж•°жҚ®йӣҶдёҠиҝӣиЎҢдәҶйў„и®ӯз»ғ гҖӮ д»ҺдёҠиЎЁеҸҜд»ҘзңӢеҮә пјҢ еӨҚжқӮеәҰиҫғдҪҺ пјҢ 规模иҫғе°Ҹзҡ„ViT-LеңЁеҗ„дёӘж•°жҚ®йӣҶдёҠйғҪи¶…иҝҮдәҶResNet пјҢ 并且其жүҖйңҖзҡ„з®—еҠӣд№ҹиҰҒе°‘еҚҒеӨҡеҖҚ гҖӮ ViT-H规模жӣҙеӨ§ пјҢ дҪҶжҖ§иғҪд№ҹжңүиҝӣдёҖжӯҘжҸҗеҚҮ пјҢ еңЁImageNet, CIFAR,Oxford-IIIT, VTABзӯүж•°жҚ®йӣҶдёҠи¶…иҝҮдәҶSOTA пјҢ дё”жңүеӨ§е№…жҸҗеҚҮ гҖӮ
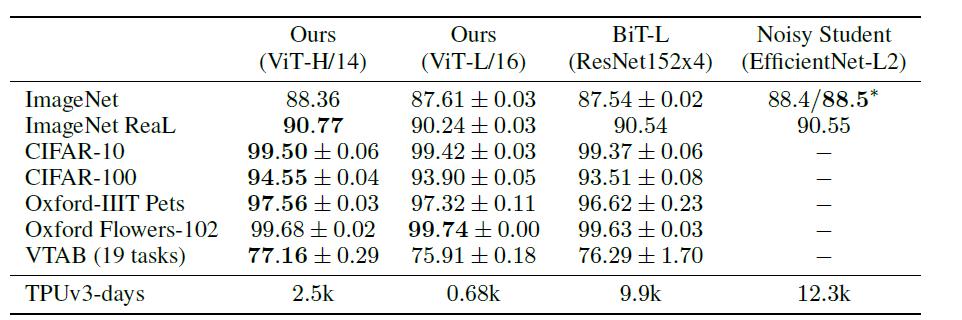
дҪңиҖ…иҝӣдёҖжӯҘе°ҶVTABзҡ„д»»еҠЎеҲҶдёәеӨҡз»„ пјҢ 并еҜ№жҜ”дәҶViTе’Ңе…¶д»–еҮ дёӘSOTAжЁЎеһӢзҡ„жҖ§иғҪпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҸҜд»ҘзңӢеҲ°йҷӨдәҶеңЁNatrualд»»еҠЎдёӯViTз•ҘдҪҺдәҺBiTеӨ– пјҢ еңЁе…¶д»–дёүдёӘд»»еҠЎдёӯйғҪиҫҫеҲ°дәҶSOTA пјҢ иҝҷеҶҚж¬ЎиҜҒжҳҺдәҶViTзҡ„жҖ§иғҪејәеӨ§ гҖӮ
4.3 дёҚеҗҢйў„и®ӯз»ғж•°жҚ®йӣҶеҜ№жҖ§иғҪзҡ„еҪұе“Қ
йў„и®ӯз»ғеҜ№дәҺиҜҘжЁЎеһӢиҖҢиЁҖжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„зҺҜиҠӮ пјҢ йў„и®ӯз»ғжүҖз”Ёж•°жҚ®йӣҶзҡ„规模е°ҶеҪұе“ҚжЁЎеһӢзҡ„еҪ’зәіеҒҸзҪ®иғҪеҠӣ пјҢ еӣ жӯӨдҪңиҖ…иҝӣдёҖжӯҘжҺўз©¶дәҶдёҚеҗҢ规模зҡ„йў„и®ӯз»ғж•°жҚ®йӣҶеҜ№жҖ§иғҪзҡ„еҪұе“Қпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
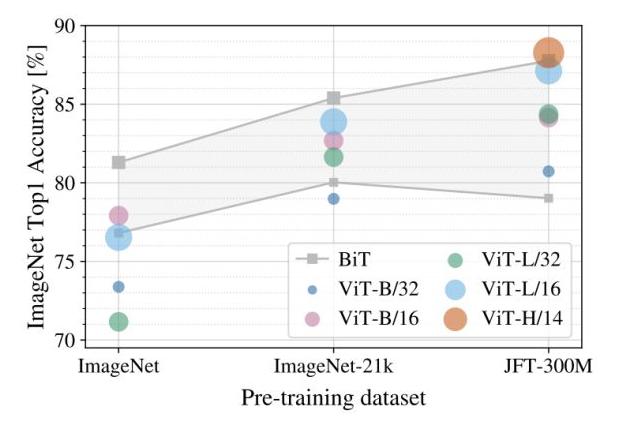
дёҠеӣҫеұ•зӨәдәҶдёҚеҗҢ规模зҡ„йў„и®ӯз»ғж•°жҚ®йӣҶпјҲжЁӘиҪҙпјүеҜ№дёҚеҗҢеӨ§е°Ҹзҡ„жЁЎеһӢзҡ„жҖ§иғҪеҪұе“Қ пјҢ жіЁж„Ҹеҫ®и°ғж—¶зҡ„ж•°жҚ®йӣҶеӣәе®ҡдёәImageNet гҖӮ еҸҜд»ҘзңӢеҲ°еҜ№еӨ§йғЁеҲҶжЁЎеһӢиҖҢиЁҖ пјҢ йў„и®ӯз»ғж•°жҚ®йӣҶ规模и¶ҠеӨ§ пјҢ жңҖз»Ҳзҡ„жҖ§иғҪи¶ҠеҘҪ гҖӮ 并且йҡҸзқҖж•°жҚ®йӣҶзҡ„еўһеӨ§ пјҢ иҫғеӨ§зҡ„ViTжЁЎеһӢпјҲViT-H/14пјүиҰҒз”ұдәҺиҫғе°Ҹзҡ„ViTжЁЎеһӢпјҲViT-Lпјү гҖӮ
жӯӨеӨ– пјҢ дҪңиҖ…иҝҳеңЁдёҚеҗҢеӨ§е°Ҹзҡ„JFTж•°жҚ®йӣҶзҡ„еӯҗйӣҶдёҠиҝӣиЎҢдәҶжЁЎеһӢи®ӯз»ғпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
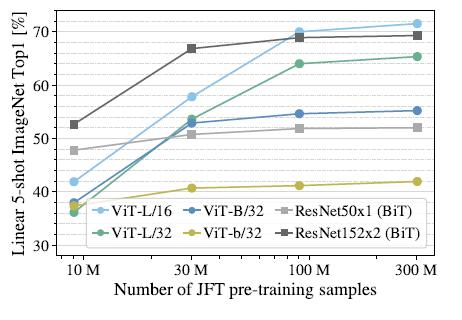
еҸҜд»ҘеҸ‘зҺ°ViT-LеҜ№еә”зҡ„дёӨдёӘжЁЎеһӢеңЁж•°жҚ®йӣҶ规模еўһеӨ§ж—¶жңүйқһеёёжҳҺжҳҫзҡ„жҸҗеҚҮ пјҢ иҖҢResNetеҲҷеҮ д№ҺжІЎжңүеҸҳеҢ– гҖӮ иҝҷйҮҢеҸҜд»Ҙеҫ—еҮәдёӨдёӘз»“и®ә пјҢ дёҖжҳҜViTжЁЎеһӢжң¬иә«зҡ„жҖ§иғҪдёҠйҷҗиҰҒдјҳдәҺResNet,иҝҷеҸҜд»ҘзҗҶи§ЈдёәжіЁж„ҸеҠӣжңәеҲ¶зҡ„дёҠйҷҗй«ҳдәҺCNN гҖӮ дәҢжҳҜеңЁж•°жҚ®йӣҶйқһеёёеӨ§зҡ„жғ…еҶөдёӢ пјҢ ViTжЁЎеһӢжҖ§иғҪеӨ§е№…и¶…и¶ҠResNet, иҝҷиҜҙжҳҺеңЁж•°жҚ®и¶іеӨҹзҡ„жғ…еҶөдёӢ пјҢ жіЁж„ҸеҠӣжңәеҲ¶е®Ңе…ЁеҸҜд»Ҙд»ЈжӣҝCNN пјҢ иҖҢеңЁж•°жҚ®йӣҶиҫғе°Ҹзҡ„жғ…еҶөдёӢпјҲ10Mпјү пјҢ еҚ·з§ҜеҲҷжӣҙдёәжңүж•Ҳ гҖӮ
йҷӨдәҶд»ҘдёҠе®һйӘҢ пјҢ дҪңиҖ…иҝҳжҺўз©¶дәҶViTжЁЎеһӢзҡ„иҝҒ移жҖ§иғҪ пјҢ е®һйӘҢз»“жһңиЎЁжҳҺдёҚи®әжҳҜжҖ§иғҪиҝҳжҳҜз®—еҠӣйңҖжұӮ пјҢ ViTжЁЎеһӢеңЁиҝӣиЎҢиҝҒ移时йғҪдјҳдәҺResNet гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҸҜи§ҶеҢ–еҲҶжһҗ
еҸҜи§ҶеҢ–еҲҶжһҗеҸҜд»Ҙеё®еҠ©жҲ‘们дәҶи§ЈViTзҡ„зү№еҫҒеӯҰд№ иҝҮзЁӢ гҖӮ жҳҫ然 пјҢ ViTжЁЎеһӢзҡ„жіЁж„ҸеҠӣдёҖе®ҡжҳҜж”ҫеңЁдәҶдёҺеҲҶзұ»жңүе…ізҡ„еҢәеҹҹпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҖ»з»“
жң¬ж–ҮжҸҗеҮәзҡ„еҹәдәҺpatchеҲҶеүІзҡ„еӣҫеғҸи§ЈйҮҠзӯ–з•Ҙ пјҢ еңЁз»“еҗҲTransformerзҡ„жғ…еҶөдёӢеҸ–еҫ—дәҶйқһеёёеҘҪзҡ„ж•Ҳжһң пјҢ иҝҷдёәCVйўҶеҹҹзҡ„е…¶д»–з ”з©¶жҸҗдҫӣдәҶдёҖдёӘеҫҲеҘҪзҡ„жҖқи·Ҝ гҖӮ жӯӨеӨ– пјҢ жҺҘдёӢжқҘеә”иҜҘдјҡеҮәзҺ°и®ёеӨҡеҹәдәҺиҝҷзҜҮе·ҘдҪңзҡ„з ”з©¶ пјҢ иҝӣдёҖжӯҘе°ҶиҝҷдёҖеҲ’ж—¶д»Јзҡ„жЁЎеһӢеә”з”ЁеҲ°жӣҙеӨҡзҡ„д»»еҠЎдёҠ пјҢ дҫӢеҰӮзӣ®ж ҮжЈҖжөӢгҖҒе®һдҫӢеҲҶеүІгҖҒиЎҢдёәиҜҶеҲ«зӯүзӯү гҖӮ жӯӨеӨ– пјҢ д№ҹдјҡеҮәзҺ°й’ҲеҜ№patchеҲҶеүІзӯ–з•Ҙзҡ„ж”№иҝӣ пјҢ жқҘиҝӣдёҖжӯҘжҸҗй«ҳжЁЎеһӢжҖ§иғҪ гҖӮ
#de89ca259eb1
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҺЁиҚҗйҳ…иҜ»












- иҷҫзұійҹід№җжӯЈејҸе®Је‘Ҡе…іеҒңпјҡеӣҪеҶ…йҹід№җе№іеҸ°з»Ҳе‘ҠеҲ«вҖңдёүеӣҪжқҖвҖқпјҢTMEдёҖ家зӢ¬еӨ§жҲ–е°ҶжҢҒз»ӯ
- иҷҫзұійҹід№җе…іеҒң дә’иҒ”зҪ‘е‘ҠеҲ«вҖңе°ҸиҖҢзҫҺвҖқ
- дёҚжӯўжңүMate40пјҢеҸҰдёҖеј вҖңеә•зүҢвҖқд№ҹиў«жӣқе…үпјҢеҚҺдёәд№ҹжҳҜиҝ«дёҚеҫ—е·І
- иҒҡз„ҰпҪңиҷҫзұійҹід№җ дҪ•д»Ҙд»ҺвҖңеҒҸзҲұвҖқиө°еҗ‘вҖңе‘ҠеҲ«вҖқпјҹ
- иҒ”жғідёӘдәәдә‘еӯҳеӮЁX1еӣҫиөҸпјҡдә”зӣҳдҪҚ80TB е‘ҠеҲ«й»‘еӨ§з¬Ёдё‘
- дёҖеј еӣҫзңӢжҮӮMIUI 12.5пјҡд»ҠжҷҡOTAгҖҒеҠЁз”»ж•ҲжһңеӘІзҫҺiOS
- BRYDGE W-Touchи§ҰжҺ§жқҝдҪ“йӘҢпјҡе‘ҠеҲ«йј ж ҮжүӢиҪ»еҠһе…¬еҲ©еҷЁ
- е‘ҠеҲ«жҖ§иғҪй—®йўҳпјҡRuby 3.0жӯЈејҸеҸ‘еёғ
- дёҖеј еӣҫзңӢжҮӮе°Ҹзұі11 йҰ–еҸ‘й«ҳйҖҡйӘҒйҫҷ888й…ҚеӨҮиЎҢдёҡйЎ¶зә§еұҸ幕
- е°јеә·зӣёжңәе°ҶдәҺ2021е№ҙеә•еүҚеҪ»еә•е‘ҠеҲ«вҖңж—Ҙжң¬дә§вҖқ