и®Ўз®—жңәи§Ҷи§ү"ж–°"иҢғејҸпјҡTransformer | NLPе’ҢCVиғҪз”ЁеҗҢдёҖз§ҚиҢғејҸжқҘиЎЁиҫҫеҗ—пјҹ( дёү )
е°ҶyиЎЁзӨәдёәgtзҡ„йӣҶеҗҲ пјҢиЎЁзӨәдёә дёӘйў„жөӢз»“жһңзҡ„йӣҶеҗҲ гҖӮ еҒҮи®ҫ еӨ§дәҺеӣҫзүҮзӣ®ж Үж•° пјҢеҸҜд»Ҙи®ӨдёәжҳҜз”Ёз©әзұ»(ж— зӣ®ж Ү)еЎ«е……зҡ„еӨ§е°Ҹдёә зҡ„йӣҶеҗҲ гҖӮ
жҗңзҙўдёӨдёӘйӣҶеҗҲ дёӘе…ғзҙ зҡ„дёҚеҗҢжҺ’еҲ—йЎәеәҸ пјҢ дҪҝеҫ—lossе°ҪеҸҜиғҪзҡ„е°Ҹзҡ„жҺ’еҲ—йЎәеәҸеҚідёәдәҢеҲҶеӣҫжңҖеӨ§еҢ№й…Қ(Bipartite Matching) пјҢ е…¬ејҸеҰӮдёӢпјҡ
е…¶дёӯ иЎЁзӨәpredе’Ңgtе…ідәҺ е…ғзҙ зҡ„еҢ№й…Қloss гҖӮ е…¶дёӯдәҢеҲҶеӣҫеҢ№й…ҚйҖҡиҝҮеҢҲзүҷеҲ©з®—жі•(Hungarian algorithm)еҫ—еҲ° гҖӮ
еҢ№й…ҚlossеҗҢж—¶иҖғиҷ‘дәҶpred classе’Ңpred boxзҡ„еҮҶзЎ®жҖ§ гҖӮ жҜҸдёӘgtзҡ„е…ғзҙ еҸҜд»ҘзңӢжҲҗпјҢиЎЁзӨәclass label(еҸҜиғҪжҳҜз©әзұ») иЎЁзӨәgt box пјҢ е°Ҷе…ғзҙ дәҢеҲҶеӣҫеҢ№й…ҚжҢҮе®ҡзҡ„pred classиЎЁзӨәдёәпјҢ pred boxиЎЁзӨәдёәгҖӮ
第дёҖжӯҘе…ҲжүҫеҲ°дёҖеҜ№дёҖеҢ№й…Қзҡ„predе’Ңgt пјҢ 第дәҢжӯҘеҶҚи®Ўз®—hungarian loss гҖӮ
hungarian lossе…¬ејҸеҰӮдёӢпјҡ
е…¶дёӯ з»“еҗҲдәҶL1 lossе’Ңgeneralized IoU loss пјҢ е…¬ејҸеҰӮдёӢпјҡ
ViTе’ҢDETRдёӨзҜҮж–Үз« зҡ„е®һйӘҢе’ҢеҸҜи§ҶеҢ–еҲҶжһҗеҫҲжңүеҗҜеҸ‘жҖ§ пјҢ ж„ҹе…ҙи¶Јзҡ„еҸҜд»Ҙд»”з»ҶзңӢзңӢ~~
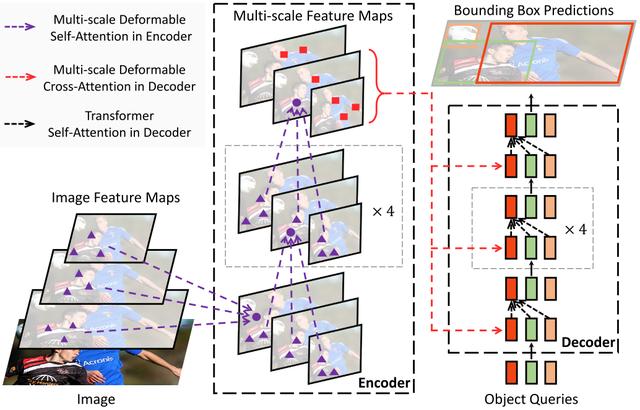
4 Deformable DETR
д»ҺDETRзңӢ пјҢ иҝҳдёҚи¶ід»Ҙиө¶дёҠCNN пјҢ еӣ дёәи®ӯз»ғж—¶й—ҙеӨӘд№…дәҶ пјҢ Deformable DETRзҡ„еҮәзҺ° пјҢ и®©жҲ‘еҜ№TransformerжңүдәҶж–°зҡ„жңҹеҫ… гҖӮ
Deformable DETRе°ҶDETRдёӯзҡ„attentionжӣҝжҚўжҲҗDeformable Attention пјҢ дҪҝDETRиҢғејҸзҡ„жЈҖжөӢеҷЁжӣҙеҠ й«ҳж•Ҳ пјҢ 收ж•ӣйҖҹеәҰеҠ еҝ«10еҖҚ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
Deformable DETRжҸҗеҮәзҡ„Deformable AttentionеҸҜд»ҘеҸҜд»Ҙзј“и§ЈDETRзҡ„收ж•ӣйҖҹеәҰж…ўе’ҢеӨҚжқӮеәҰй«ҳзҡ„й—®йўҳ гҖӮ еҗҢж—¶з»“еҗҲдәҶdeformable convolutionзҡ„зЁҖз–Ҹз©әй—ҙйҮҮж ·иғҪеҠӣе’Ңtransformerзҡ„е…ізі»е»әжЁЎиғҪеҠӣ гҖӮ
Deformable AttentionеҸҜд»ҘиҖғиҷ‘е°Ҹзҡ„йҮҮж ·дҪҚзҪ®йӣҶдҪңдёәдёҖдёӘpre-filterзӘҒеҮәжүҖжңүfeature mapзҡ„е…ій”®зү№еҫҒ пјҢ 并且еҸҜд»ҘиҮӘ然ең°жү©еұ•еҲ°иһҚеҗҲеӨҡе°әеәҰзү№еҫҒ пјҢ 并且Multi-scale Deformable Attentionжң¬иә«е°ұеҸҜд»ҘеңЁеӨҡе°әеәҰзү№еҫҒеӣҫд№Ӣй—ҙиҝӣиЎҢдәӨжҚўдҝЎжҒҜ пјҢ дёҚйңҖиҰҒFPNж“ҚдҪң гҖӮ
1. Deformable Attention Module
з»ҷе®ҡдёҖдёӘqueryе…ғзҙ (еҰӮиҫ“еҮәеҸҘеӯҗдёӯзҡ„зӣ®ж ҮиҜҚ)е’ҢдёҖз»„keyе…ғзҙ (еҰӮиҫ“е…ҘеҸҘеӯҗзҡ„жәҗиҜҚ) пјҢ Multi-Head AttentionиғҪеӨҹж №жҚ®query-key pairsзҡ„зӣёе…іжҖ§иҮӘйҖӮеә”зҡ„иҒҡеҗҲkeyзҡ„дҝЎжҒҜ гҖӮ дёәдәҶи®©жЁЎеһӢе…іжіЁжқҘиҮӘдёҚеҗҢиЎЁзӨәеӯҗз©әй—ҙе’ҢдёҚеҗҢдҪҚзҪ®зҡ„дҝЎжҒҜ пјҢ еҜ№multi-headзҡ„дҝЎжҒҜиҝӣиЎҢеҠ жқғиҒҡеҗҲ гҖӮ
е…¶дёӯ иЎЁзӨәqueryе…ғзҙ (зү№еҫҒиЎЁзӨәдёә ) пјҢиЎЁзӨәkeyе…ғзҙ (зү№еҫҒиЎЁзӨәдёә ) пјҢжҳҜзү№еҫҒз»ҙеәҰ пјҢе’Ң еҲҶеҲ«дёә е’Ң зҡ„йӣҶеҗҲ гҖӮ
йӮЈд№ҲTransformer зҡ„ Multi-Head Attentionе…¬ејҸиЎЁзӨәдёәпјҡ
е…¶дёӯ жҢҮе®ҡattention head пјҢе’Ң жҳҜеҸҜеӯҰд№ еҸӮж•° пјҢ жіЁж„ҸеҠӣжқғйҮҚ 并且еҪ’дёҖеҢ–пјҢ е…¶дёӯ жҳҜеҸҜеӯҰд№ еҸӮж•° гҖӮ дёәдәҶиғҪеӨҹеҲҶиҫЁдёҚеҗҢз©әй—ҙдҪҚзҪ® пјҢе’Ң йҖҡеёёдјҡеј•е…Ҙpositional embedding гҖӮ
еҜ№дәҺDETRдёӯзҡ„Transformer Encoder пјҢ queryе’Ңkeyе…ғзҙ йғҪжҳҜfeature mapдёӯзҡ„еғҸзҙ гҖӮ
DETR зҡ„ Multi-Head Attention е…¬ејҸиЎЁзӨәдёәпјҡ
е…¶дёӯгҖӮ
DETRдё»иҰҒжңүдёӨдёӘй—®йўҳпјҡйңҖиҰҒжӣҙеӨҡзҡ„и®ӯз»ғж—¶й—ҙжқҘ收ж•ӣ пјҢ еҜ№е°Ҹзӣ®ж Үзҡ„жЈҖжөӢжҖ§иғҪзӣёеҜ№иҫғе·® гҖӮ жң¬иҙЁдёҠжҳҜеӣ дёәTransfomerзҡ„Multi-Head AttentionдјҡеҜ№иҫ“е…ҘеӣҫзүҮзҡ„жүҖжңүз©әй—ҙдҪҚзҪ®иҝӣиЎҢи®Ўз®— гҖӮ
иҖҢDeformable DETRзҡ„Deformable AttentionеҸӘе…іжіЁеҸӮиҖғзӮ№е‘Ёеӣҙзҡ„дёҖе°ҸйғЁеҲҶе…ій”®йҮҮж ·зӮ№ пјҢ дёәжҜҸдёӘqueryеҲҶй…Қе°‘йҮҸеӣәе®ҡж•°йҮҸзҡ„key пјҢ еҸҜд»Ҙ缓解收ж•ӣжҖ§е’Ңиҫ“е…ҘеҲҶиҫЁзҺҮеҸ—йҷҗеҲ¶зҡ„й—®йўҳ гҖӮ
з»ҷе®ҡдёҖдёӘиҫ“е…Ҙfeature mapпјҢиЎЁзӨәдёәqueryе…ғзҙ (зү№еҫҒиЎЁзӨәдёә) пјҢ дәҢз»ҙеҸӮиҖғзӮ№иЎЁзӨәдёәпјҢ Deformable DETR зҡ„ Deformable Attentionе…¬ејҸиЎЁзӨәдёәпјҡ
е…¶дёӯ жҢҮе®ҡattention head пјҢжҢҮе®ҡйҮҮж ·зҡ„key пјҢиЎЁзӨәйҮҮж ·keyзҡ„жҖ»ж•° гҖӮ, еҲҶеҲ«иЎЁзӨә第 дёӘйҮҮж ·зӮ№еңЁз¬¬ дёӘattention headзҡ„йҮҮж ·еҒҸ移йҮҸе’ҢжіЁж„ҸеҠӣжқғйҮҚ гҖӮ жіЁж„ҸеҠӣжқғйҮҚ еңЁ[0,1]зҡ„иҢғеӣҙеҶ… пјҢ еҪ’дёҖеҢ–гҖӮиЎЁзӨәдёәж— зәҰжқҹиҢғеӣҙзҡ„дәҢз»ҙе®һж•° гҖӮ еӣ дёә дёәеҲҶж•° пјҢ йңҖиҰҒйҮҮз”ЁеҸҢзәҝжҖ§жҸ’еҖјж–№жі•и®Ўз®—гҖӮ
2. Multi-scale Deformable Attention Module
Deformable AttentionеҸҜд»ҘеҫҲиҮӘ然ең°жү©еұ•еҲ°еӨҡе°әеәҰзҡ„feature maps гҖӮиЎЁзӨәдёәиҫ“е…Ҙзҡ„еӨҡе°әеәҰfeature maps пјҢгҖӮиЎЁзӨәдёәжҜҸдёӘqueryе…ғзҙ зҡ„еҸӮиҖғзӮ№ зҡ„еҪ’дёҖеҢ–еқҗж Ү гҖӮ Deformable DETR зҡ„Multi-scale Deformable Attentionе…¬ејҸиЎЁзӨәдёәпјҡ
жҺЁиҚҗйҳ…иҜ»




















- дёәд»Җд№Ҳжңү"iphoneжҳҜз©·дәәжүӢжңә"зҡ„иЁҖи®әпјҹз”ЁдёҮе…ғжңәзҡ„дәәзңҹз©·еҗ—
- еӨ§дёҖйқһи®Ўз®—жңәдё“дёҡзҡ„еӯҰз”ҹпјҢеҰӮдҪ•еҲ©з”ЁеҜ’еҒҮиҮӘеӯҰCиҜӯиЁҖ
- еҸҲзҲҶзӮёпјҒиҒ”з”ө科жҠҖдј жқҘдёҖеЈ°е·Ёе“ҚпјҢжҲ–жҠҠ8 иӢұеҜёжҷ¶еңҶеёӮеңә"зӮё"дәҶ
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- йӣ·еҶӣеҶҚж¬Ўж”ҫеӨ§жӢӣпјҢе°Ҹзұі"иҪ»иЈ…дёҠйҳө"еҗҺпјҢеҚҺдёәиҝҳиғҪжүӣеҫ—дҪҸеҗ—пјҹ
- зҫҺеӣҪе…¬еҸёз ҙи§Ј"еҲ·и„ёж”Ҝд»ҳ"пјҹ用马дә‘з…§зүҮеҒҡе®һйӘҢпјҢз»“жһңеј№еҮә4дёӘеӨ§еӯ—
- иӢ№жһңж”№еҸҳз«Ӣеңә з§°macOSе®һз”ЁзЁӢеәҸAmphetamineеҸҜ继з»ӯз•ҷеңЁMacеә”з”Ёе•Ҷеә—дёӯ
- "дәҢе…«е®ҡеҫӢ"йҡҫз ҙ CPUеёӮеҚ зҺҮиӢұзү№е°”жҢҒз»ӯеҚ дјҳ
- иҫ№зјҳи®Ўз®—зӮ№зҮғж–°йЈҺжҡҙпјҢITдёҺOTд№ӢжҲҳдёҖи§ҰеҚіеҸ‘
- з”ЁдәҶдёӨеҲ°дёүе№ҙзҡ„еҚҺдёәжүӢжңәпјҢдёҖй”®жү“ејҖ"ејҖеҸ‘иҖ…йҖүйЎ№"пјҢеё®еҠ©жҖ§иғҪеҠ йҖҹ