计算机视觉"新"范式:Transformer | NLP和CV能用同一种范式来表达吗?
自从Transformer出来以后 , Transformer便开始在NLP领域一统江湖 。
而Transformer在CV领域反响平平 , 一度认为不适合CV领域 , 直到最近计算机视觉领域出来几篇Transformer文章 , 性能直逼CNN的SOTA , 给予了计算机视觉领域新的想象空间 。
本文不拘泥于Transformer原理和细节实现(知乎有很多优质的Transformer解析文章 , 感兴趣的可以看看) , 着重于Transformer对计算机视觉领域的革新 。
首先简略回顾一下Transformer , 然后介绍最近几篇计算机视觉领域的Transformer文章 , 其中ViT用于图像分类 , DETR和Deformable DETR用于目标检测 。
从这几篇可以看出 , Transformer在计算机视觉领域的范式已经初具雏形 , 可以大致概括为:Embedding->Transformer->Head
一些有趣的点写在最后~~
1 Transformer
Transformer详解:
下面以机器翻译为例子 , 简略介绍Transformer结构 。
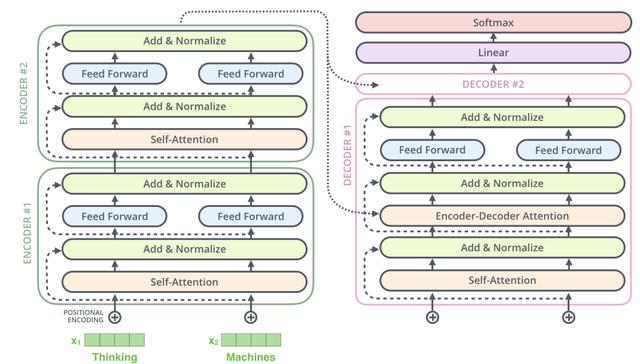
1. Encoder-Decoder
Transformer结构可以表示为Encoder和Decoder两个部分
 文章插图
文章插图
Encoder和Decoder主要由Self-Attention和Feed-Forward Network两个组件构成 , Self-Attention由Scaled Dot-Product Attention和Multi-Head Attention两个组件构成 。
Scaled Dot-Product Attention公式:
Multi-Head Attention公式:
Feed-Forward Network公式:
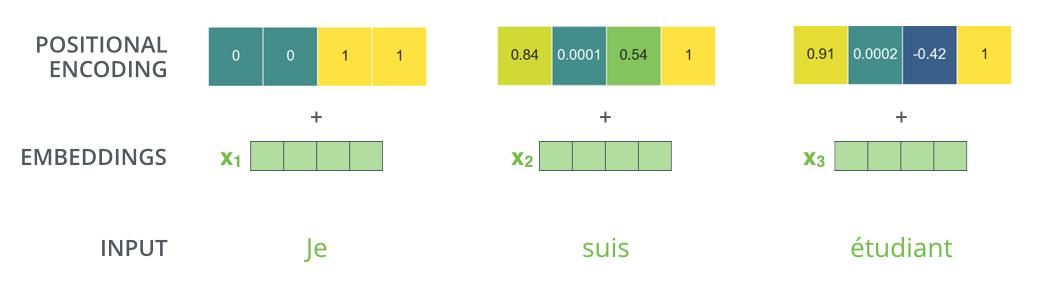
2. Positional Encoding
 文章插图
文章插图
如图所示 , 由于机器翻译任务跟输入单词的顺序有关 , Transformer在编码输入单词的嵌入向量时引入了positional encoding , 这样Transformer就能够区分出输入单词的位置了 。
引入positional encoding的公式为:
是位置 ,是维数 ,是输入单词的嵌入向量维度 。
3. Self-Attention
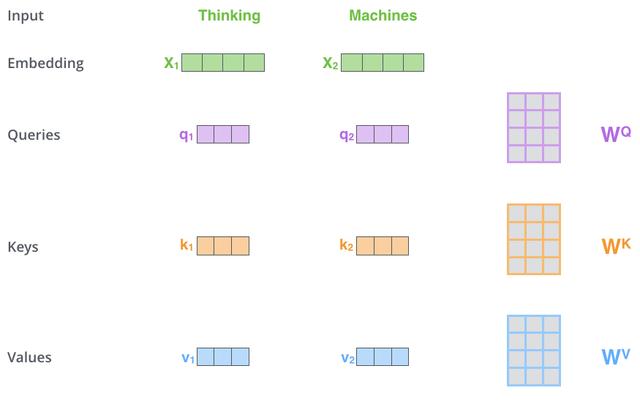
3.1 Scaled Dot-Product Attention
 文章插图
文章插图
在Scaled Dot-Product Attention中 , 每个输入单词的嵌入向量分别通过3个矩阵,和 来分别得到Query向量 , Key向量和Value向量 。
 文章插图
文章插图
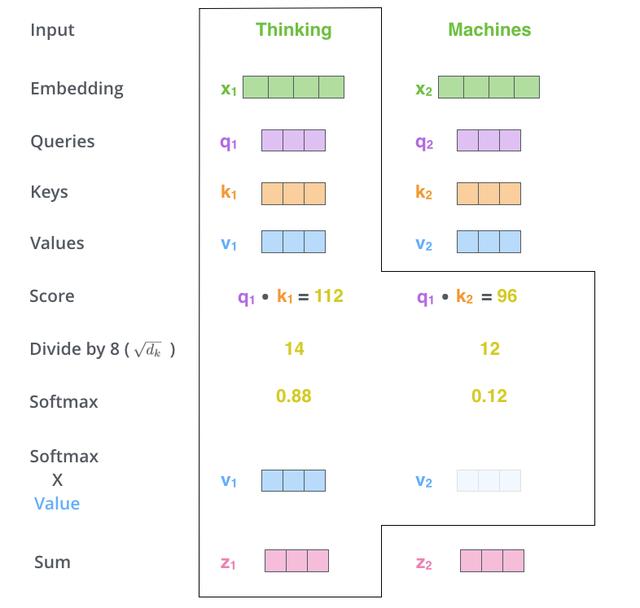
如图所示 , Scaled Dot-Product Attention的计算过程可以分成7个步骤:
- 每个输入单词转化成嵌入向量 。
- 根据嵌入向量得到 ,,三个向量 。
- 通过 , 向量计算 :。
- 对 进行归一化 , 即除以。
- 通过 激活函数计算。
- 点乘Value值, 得到每个输入向量的评分。
- 所有输入向量的评分 之和为 :。
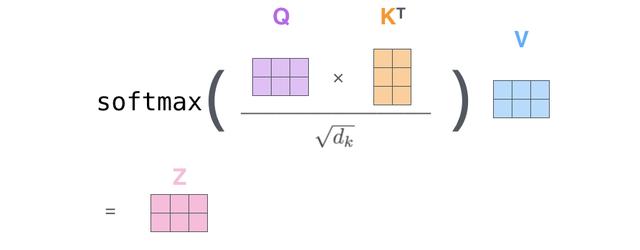 文章插图
文章插图与Scaled Dot-Product Attention公式一致 。
3.2 Multi-Head Attention
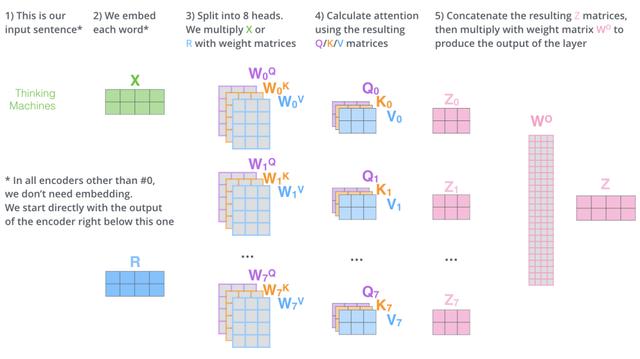 文章插图
文章插图如图所示 , Multi-Head Attention相当于h个不同Scaled Dot-Product Attention的集成 , 以h=8为例子 , Multi-Head Attention步骤如下:
- 将数据 分别输入到8个不同的Scaled Dot-Product Attention中 , 得到8个加权后的特征矩阵。
- 将8个 按列拼成一个大的特征矩阵 。
- 特征矩阵经过一层全连接得到输出。
推荐阅读

















- 为什么有"iphone是穷人手机"的言论?用万元机的人真穷吗
- 大一非计算机专业的学生,如何利用寒假自学C语言
- 又爆炸!联电科技传来一声巨响,或把8 英寸晶圆市场"炸"了
- 计算机专业大一下学期,该选择学习Java还是Python
- 雷军再次放大招,小米"轻装上阵"后,华为还能扛得住吗?
- 美国公司破解"刷脸支付"?用马云照片做实验,结果弹出4个大字
- 苹果改变立场 称macOS实用程序Amphetamine可继续留在Mac应用商店中
- "二八定律"难破 CPU市占率英特尔持续占优
- 边缘计算点燃新风暴,IT与OT之战一触即发
- 用了两到三年的华为手机,一键打开"开发者选项",帮助性能加速