计算机视觉"新"范式:Transformer | NLP和CV能用同一种范式来表达吗?( 二 )
2 ViT
ViT将Transformer巧妙的应用于图像分类任务 , 更少计算量下性能跟SOTA相当 。
 文章插图
文章插图
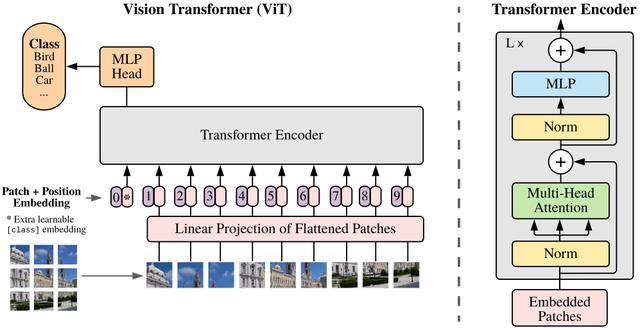
Vision Transformer(ViT)将输入图片拆分成16x16个patches , 每个patch做一次线性变换降维同时嵌入位置信息 , 然后送入Transformer , 避免了像素级attention的运算 。 类似BERT[class]标记位的设置 , ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位 , 并且该位置的Transformer Encoder输出作为图像特征 。
其中 为原图像分辨率 ,为每个图像patch的分辨率 。为Transformer输入序列的长度 。
ViT舍弃了CNN的归纳偏好问题 , 更加有利于在超大规模数据上学习知识 , 即大规模训练优归纳偏好 , 在众多图像分类任务上直逼SOTA 。
3 DETR
DETR使用set loss function作为监督信号来进行端到端训练 , 然后同时预测所有目标 , 其中set loss function使用bipartite matching算法将pred目标和gt目标匹配起来 。
直接将目标检测任务看成set prediction问题 , 使训练过程变的简洁 , 并且避免了anchor、NMS等复杂处理 。
DETR主要有两个部分:architecture和set prediction loss 。
1. Architecture
 文章插图
文章插图
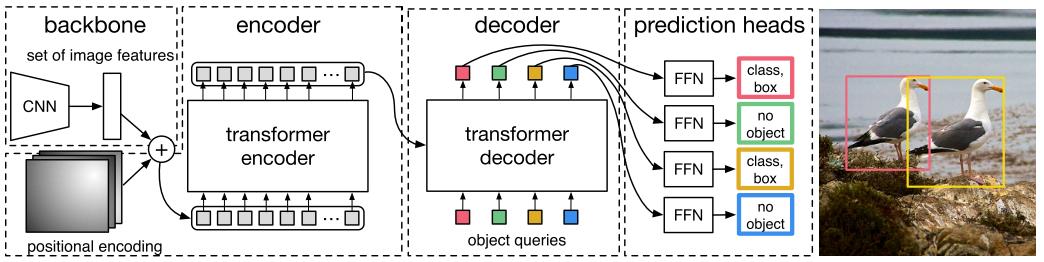
DETR先用CNN将输入图像embedding成一个二维表征 , 然后将二维表征转换成一维表征并结合positional encoding一起送入encoder , decoder将少量固定数量的已学习的object queries(可以理解为positional embeddings)和encoder的输出作为输入 。
最后将decoder得到的每个output embdding传递到一个共享的前馈网络(FFN) , 该网络可以预测一个检测结果(包括类和边框)或着“没有目标”的类 。
1.1 Transformer
 文章插图
文章插图
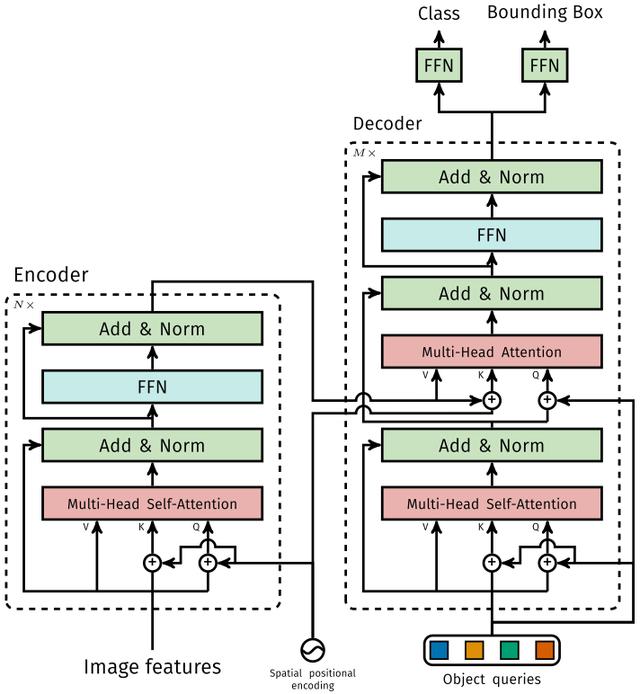
1.1.1 Encoder
将Backbone输出的feature map转换成一维表征 , 得到 特征图 , 然后结合positional encoding作为Encoder的输入 。
每个Encoder都由Multi-Head Self-Attention和FFN组成 。
和Transformer Encoder不同的是 , 因为Encoder具有位置不变性 , DETR将positional encoding添加到每一个Multi-Head Self-Attention中 , 来保证目标检测的位置敏感性 。
1.1.2 Decoder
因为Decoder也具有位置不变性 , Decoder的 个object query(可以理解为学习不同object的positional embedding)必须是不同 , 以便产生不同的结果 , 并且同时把它们添加到每一个Multi-Head Attention中 。
个object queries通过Decoder转换成一个output embedding , 然后output embedding通过FFN独立解码出 个预测结果 , 包含box和class 。
对输入embedding同时使用Self-Attention和Encoder-Decoder Attention , 模型可以利用目标的相互关系来进行全局推理 。
和Transformer Decoder不同的是 , DETR的每个Decoder并行输出 个对象 , Transformer Decoder使用的是自回归模型 , 串行输出 个对象 , 每次只能预测一个输出序列的一个元素 。
1.1.3 FFN
FFN由3层perceptron和一层linear projection组成 。 FFN预测出box的归一化中心坐标、长、宽和class 。
DETR预测的是固定数量的 个box的集合 , 并且 通常比实际目标数要大的多 , 所以使用一个额外的空类来表示预测得到的box不存在目标 。
2. Set prediction loss
DETR模型训练的主要困难是如何根据gt衡量预测结果(类别、位置、数量) 。 DETR提出的loss函数可以产生pred和gt的最优双边匹配(确定pred和gt的一对一关系) , 然后优化loss 。
推荐阅读




















- 为什么有"iphone是穷人手机"的言论?用万元机的人真穷吗
- 大一非计算机专业的学生,如何利用寒假自学C语言
- 又爆炸!联电科技传来一声巨响,或把8 英寸晶圆市场"炸"了
- 计算机专业大一下学期,该选择学习Java还是Python
- 雷军再次放大招,小米"轻装上阵"后,华为还能扛得住吗?
- 美国公司破解"刷脸支付"?用马云照片做实验,结果弹出4个大字
- 苹果改变立场 称macOS实用程序Amphetamine可继续留在Mac应用商店中
- "二八定律"难破 CPU市占率英特尔持续占优
- 边缘计算点燃新风暴,IT与OT之战一触即发
- 用了两到三年的华为手机,一键打开"开发者选项",帮助性能加速