Pandasж•ҷзЁӢ( дә” )
еёғе°”зҙўеј•пјҡilocdata.iloc[
aпјү йҖүжӢ©ж•°жҚ®йӣҶзҡ„第4иЎҢ гҖӮ
data.iloc[3] ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
bпјү д»ҺжүҖжңүеҲ—дёӯйҖүжӢ©дёҖдёӘиЎҢж•°з»„ гҖӮ
data.iloc[6:12]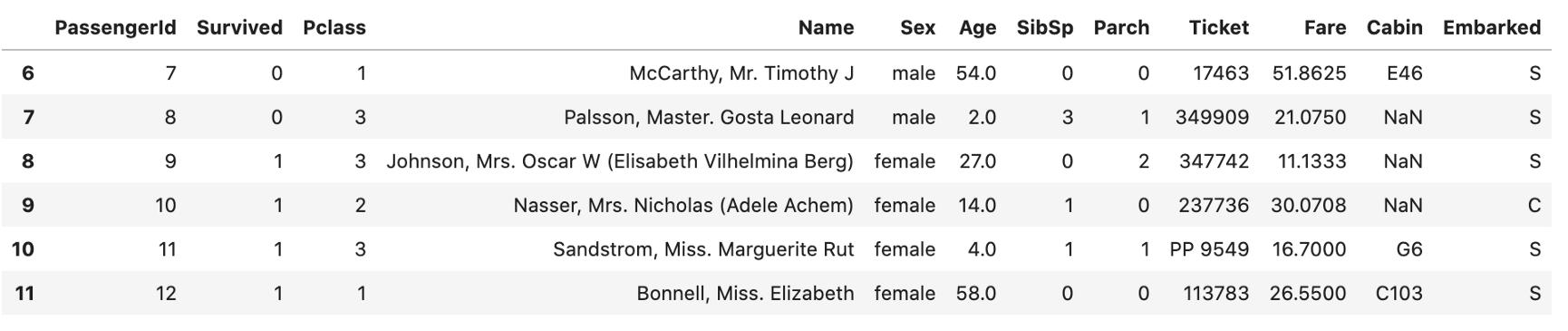 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
cпјү д»ҺжүҖжңүеҲ—дёӯйҖүжӢ©еҮ иЎҢ гҖӮ
data.iloc[[7,28,39],:] ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
dпјү д»ҺвҖңNameвҖқгҖҒвҖңAgeвҖқгҖҒвҖңSexвҖқе’ҢвҖңSurvivedвҖқеҲ—дёӯйҖүжӢ©дёҖиЎҢ гҖӮ
data.iloc[[7], [3,5,4,1]] ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
eпјү д»ҺеӨҡдёӘеҲ—дёӯйҖүжӢ©еӨҡиЎҢ гҖӮ
data.iloc[[7,28,39], [3,5,4,1]] ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
fпјү йҖүжӢ©еӨҡиЎҢеҪўжҲҗеҲ—еәҸеҲ— гҖӮ
data.iloc[[7,28,39], 3:10] ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
gпјү йҖүжӢ©е…¶д»–еҖј гҖӮ
data.iloc[6:13, -1]data.iloc[:, [3,6]]data.iloc[[7,28,39], 3:7]data.iloc[-20:, -1:]еҹәжң¬еӨ„зҗҶж•°жҚ® ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
aпјү пјҲеҲ йҷӨnanеҖјпјү гҖӮ
data.isnull().values.any()жҳҜеҗҰжңүдёўеӨұзҡ„ж•°жҚ®пјҹ
TrueеҰӮжһңжІЎжңүе°Ҷе…¶еҲҶй…ҚеҲ°(ж–°)еҸҳйҮҸдёӯ пјҢ еҲҷеә”иҜҘжҢҮе®ҡinplace=True пјҢ д»Ҙдҫҝжӣҙж”№иғҪз”ҹж•Ҳ гҖӮ
data.dropna(axis=0, inplace=True) #д»ҺиЎҢдёӯеҲ йҷӨnandata.isnull().values.any() #жҳҜеҗҰжңүдёўеӨұзҡ„ж•°жҚ®пјҹFalsebпјү еҲ йҷӨеҲ—
data.drop(columns=['PassengerId', 'Name'], axis=1).head()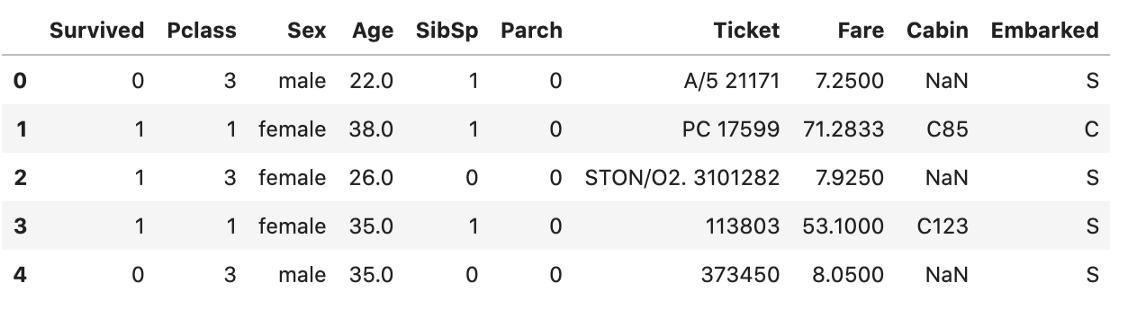 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
cпјү value_countsд№ҹеҸҜд»ҘжҳҫзӨәNaNеҖј гҖӮ
data.Age.value_counts(dropna=False)NaN17724.003022.002718.002628.0025... 36.50155.50166.00123.5010.421Name: Age, Length: 89, dtype: int64dпјү жӣҝжҚўдёўеӨұеҖј
new_df = data.copy()и®Ўз®—е№ҙйҫ„е№іеқҮеҖј:
new_df.Age.mean()29.69911764705882new_df['Age_mean'] = new_df.Age.fillna(new_df.Age.mean())е№ҙйҫ„зҡ„дёӯеҖј
new_df.Age.median()28.0з”Ёж•°жҚ®зҡ„дёӯеҖјеЎ«е……д»»ж„ҸNAN пјҢ 并е°Ҷз»“жһңеҲҶй…Қз»ҷдёҖдёӘж–°еҲ— гҖӮ
new_df['Age_median'] = new_df.Age.fillna(new_df.Age.median())
жҺЁиҚҗйҳ…иҜ»



















- 111е®ҢзҫҺйӮ®з®ұдёҠзәҝпјҢе®ҡдҪҚвҖңе№ҙиҪ»дәәзҡ„дё“еұһйӮ®з®ұвҖқ
- з»ҷдҪ зҡ„iPhone12е…Ёж–№дҪҚдҝқжҠӨпјҡ6ж¬ҫжүӢжңәдҝқжҠӨеЈіжЁӘиҜ„
- еҚҺдә‘еӨ§е’–иҜҙ дә‘и®Ўз®—дә‘иҝҗз»ҙжө…и°Ҳ
- еңЁзәҝйҹід№җз”ЁжҲ·еҜ„жңӣз”ЁзҲұеҸ‘з”өпјҢиө„жң¬дёҚж„ҝж— зұід№ӢзӮҠ
- 36еІҒпјҢжҲ‘еңЁеӨ§еҺӮпјҢе’Ңе…Ҳз”ҹе…»иӮІвҖңдә’иҒ”зҪ‘еӯӨе„ҝвҖқ
- иҷҫзұійҹід№җпјҢдёӢдёӘжңҲжӯЈејҸеҒңжӯўжңҚеҠЎ
- ж”Ҝд»ҳе®қе№ҙиҙҰеҚ•жқҘдәҶпјҢдҪ еҸҜиғҪй”ҷеӨұдәҶдёҖеҘ—жҲҝвҖҰвҖҰ
- жІіеҢ—зңҒйҰ–家вҖңж”ҝзӯ–жҷәйҖҡвҖқи®Ўз®—еҷЁжӯЈејҸдёҠзәҝ
- вҖңе…ЁиғҪзҘһвҖқејҖеҸ‘и°·жӯҢеә”з”ЁAPPдј ж’ӯйӮӘж•ҷж•ҷд№ү
- еҗ‘зҫҺеӣҪйқ жӢўпјҹз‘һе…ёз»•ејҖеҚҺдёәйғЁзҪІ5GпјҒеҚҺдёәе·І2ж¬Ўиө·иҜү