Pandasж•ҷзЁӢ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
дҪңдёәжҜҸдёӘж•°жҚ®з§‘еӯҰ家йғҪйқһеёёзҶҹжӮүе’ҢдҪҝз”Ёзҡ„жңҖеҸ—ж¬ўиҝҺе’ҢдҪҝз”Ёзҡ„е·Ҙе…·д№ӢдёҖ пјҢ Pandasеә“еңЁж•°жҚ®ж“ҚдҪңгҖҒеҲҶжһҗе’ҢеҸҜи§ҶеҢ–ж–№йқўйқһеёёеҮәиүІ
дёәдәҶеё®еҠ©дҪ е®ҢжҲҗиҝҷйЎ№д»»еҠЎе№¶еҜ№Pythonзј–з ҒжӣҙеҠ иҮӘдҝЎ пјҢ жҲ‘з”ЁPandasдёҠдёҖдәӣжңҖеёёз”Ёзҡ„еҮҪж•°е’Ңж–№жі•еҲӣе»әдәҶжң¬ж•ҷзЁӢ гҖӮ жҲ‘зңҹеҝғеёҢжңӣиҝҷеҜ№дҪ жңүз”Ё гҖӮ
зӣ®еҪ•
- еҜје…Ҙеә“
- еҜје…Ҙ/еҜјеҮәж•°жҚ®
- жҳҫзӨәж•°жҚ®
- еҹәжң¬дҝЎжҒҜпјҡеҝ«йҖҹжҹҘзңӢж•°жҚ®
- еҹәжң¬з»ҹи®Ў
- и°ғж•ҙж•°жҚ®
- еёғе°”зҙўеј•пјҡloc
- еёғе°”зҙўеј•пјҡiloc
- еҹәжң¬еӨ„зҗҶж•°жҚ®
жі°еқҰе°је…ӢеҸ·зҡ„ж•°жҚ®йӣҶеҸҜд»ҘеңЁиҝҷйҮҢдёӢиҪҪпјҡ
еҜје…Ҙеә“дёәдәҶжҲ‘们зҡ„зӣ®зҡ„ пјҢ вҖңPandasвҖқеә“жҳҜеҝ…йЎ»еҜје…Ҙзҡ„
import pandas as pdеҜје…Ҙ/еҜјеҮәж•°жҚ®вҖңжі°еқҰе°је…ӢеҸ·ж•°жҚ®йӣҶвҖқжҢҮе®ҡдёәвҖңdataвҖқ гҖӮaпјү дҪҝз”Ёread_csvе°Ҷcsvж–Ү件еҜје…Ҙ гҖӮ дҪ еә”иҜҘеңЁж–Ү件дёӯж·»еҠ ж•°жҚ®зҡ„еҲҶйҡ”з¬Ұ гҖӮ
data = http://kandian.youth.cn/index/pd.read_csv("file_name.csv", sep=';')bпјү дҪҝз”Ёread_excelд»Һexcelж–Ү件иҜ»еҸ–ж•°жҚ® гҖӮdata = http://kandian.youth.cn/index/pd.read_excel('file_name.xls')cпјү е°Ҷж•°жҚ®её§еҜјеҮәеҲ°csvж–Ү件 пјҢ дҪҝз”Ёto_csvdata.to_csv("file_name.csv", sep=';', index=False)dпјү дҪҝз”ЁвҖңto_excelвҖқе°Ҷж•°жҚ®жЎҶеҜјеҮәеҲ°excelж–Ү件 гҖӮdata.to_excel("file_name.xlsвҖІ)жҳҫзӨәж•°жҚ®aпјү жӯЈеңЁжү“еҚ°еүҚnиЎҢ гҖӮ еҰӮжһңжІЎжңүз»ҷе®ҡ пјҢ еҲҷй»ҳи®ӨжҳҫзӨә5иЎҢ гҖӮdata.head() ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫbпјү жү“еҚ°жңҖеҗҺвҖңnвҖқиЎҢ гҖӮ дёӢйқў пјҢ жҳҫзӨәжңҖеҗҺ7иЎҢ гҖӮ
data.tail(7)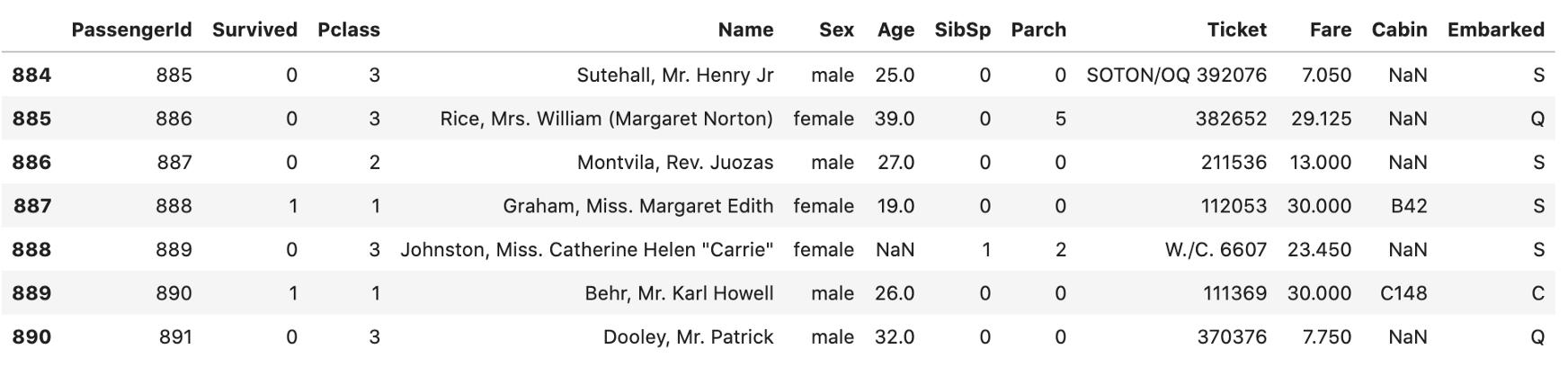 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫеҹәжң¬дҝЎжҒҜпјҡеҝ«йҖҹжҹҘзңӢж•°жҚ®
aпјү жҳҫзӨәж•°жҚ®йӣҶзҡ„з»ҙеәҰпјҡжҖ»иЎҢж•°гҖҒеҲ—ж•° гҖӮ
data.shapeпјҲ891 пјҢ 12пјүbпјү жҳҫзӨәеҸҳйҮҸзұ»еһӢ гҖӮ
data.dtypesPassengerIdint64Survivedint64Pclassint64NameobjectSexobjectAgefloat64SibSpint64Parchint64TicketobjectFarefloat64CabinobjectEmbarkedobjectdtype: objectcпјү жҢүеҚҮеәҸеҖјжҳҫзӨәеҸҳйҮҸзұ»еһӢ гҖӮdata.dtypes.sort_values(ascending=True)PassengerIdint64Survivedint64Pclassint64SibSpint64Parchint64Agefloat64Farefloat64NameobjectSexobjectTicketobjectCabinobjectEmbarkedobjectdtype: objectdпјү жҢүзұ»еһӢеҜ№еҸҳйҮҸи®Ўж•° гҖӮdata.dtypes.value_counts()object5int645float642dtype: int64eпјү жҢүеҚҮеәҸеҖјеҜ№жҜҸз§Қзұ»еһӢи®Ўж•° гҖӮdata.dtypes.value_counts(ascending=True)float642int645object5dtype: int64fпјү д»Ҙз»қеҜ№еҖјжЈҖжҹҘз”ҹеӯҳиҖ…дёҺйқһз”ҹеӯҳиҖ…зҡ„ж•°йҮҸ гҖӮdata.Survived.value_counts()05491342Name: Survived, dtype: int64gпјү жЈҖжҹҘзү№еҫҒзҡ„жҜ”дҫӢ пјҢ д»ҘзҷҫеҲҶжҜ”иЎЁзӨә гҖӮdata.Survived.value_counts() / data.Survived.value_counts().sum()дёҺд»ҘдёӢзӣёеҗҢпјҡdata.Survived.value_counts(normalize=True)00.61616210.383838Name: Survived, dtype: float64hпјү жЈҖжҹҘзү№еҫҒзҡ„жҜ”дҫӢ пјҢ д»ҘзҷҫеҲҶжҜ”иЎЁзӨә пјҢ еӣӣиҲҚдә”е…Ҙ гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- 111е®ҢзҫҺйӮ®з®ұдёҠзәҝпјҢе®ҡдҪҚвҖңе№ҙиҪ»дәәзҡ„дё“еұһйӮ®з®ұвҖқ
- з»ҷдҪ зҡ„iPhone12е…Ёж–№дҪҚдҝқжҠӨпјҡ6ж¬ҫжүӢжңәдҝқжҠӨеЈіжЁӘиҜ„
- еҚҺдә‘еӨ§е’–иҜҙ дә‘и®Ўз®—дә‘иҝҗз»ҙжө…и°Ҳ
- еңЁзәҝйҹід№җз”ЁжҲ·еҜ„жңӣз”ЁзҲұеҸ‘з”өпјҢиө„жң¬дёҚж„ҝж— зұід№ӢзӮҠ
- 36еІҒпјҢжҲ‘еңЁеӨ§еҺӮпјҢе’Ңе…Ҳз”ҹе…»иӮІвҖңдә’иҒ”зҪ‘еӯӨе„ҝвҖқ
- иҷҫзұійҹід№җпјҢдёӢдёӘжңҲжӯЈејҸеҒңжӯўжңҚеҠЎ
- ж”Ҝд»ҳе®қе№ҙиҙҰеҚ•жқҘдәҶпјҢдҪ еҸҜиғҪй”ҷеӨұдәҶдёҖеҘ—жҲҝвҖҰвҖҰ
- жІіеҢ—зңҒйҰ–家вҖңж”ҝзӯ–жҷәйҖҡвҖқи®Ўз®—еҷЁжӯЈејҸдёҠзәҝ
- вҖңе…ЁиғҪзҘһвҖқејҖеҸ‘и°·жӯҢеә”з”ЁAPPдј ж’ӯйӮӘж•ҷж•ҷд№ү
- еҗ‘зҫҺеӣҪйқ жӢўпјҹз‘һе…ёз»•ејҖеҚҺдёәйғЁзҪІ5GпјҒеҚҺдёәе·І2ж¬Ўиө·иҜү