Pandasж•ҷзЁӢ( дёү )
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
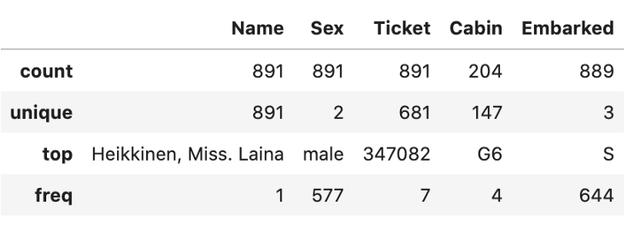
dпјү йҖҡиҝҮдј йҖ’еҸӮж•°include='all' пјҢ е°ҶеҗҢж—¶жҳҫзӨәж•°еӯ—е’Ңйқһж•°еӯ—ж•°жҚ® гҖӮ
data.describe(include='all')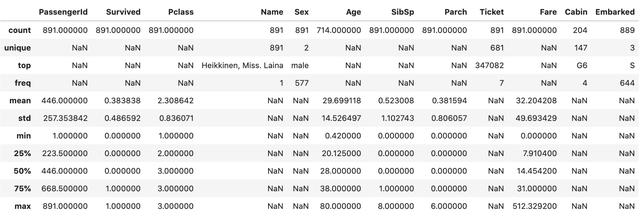 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
eпјү еҲ«еҝҳдәҶйҖҡиҝҮеңЁжң«е°ҫж·»еҠ .TжқҘиҪ¬зҪ®ж•°жҚ®её§ гҖӮ иҝҷд№ҹжҳҜдёҖдёӘйқһеёёжңүз”Ёзҡ„жҠҖе·§
data.describe(include='all').T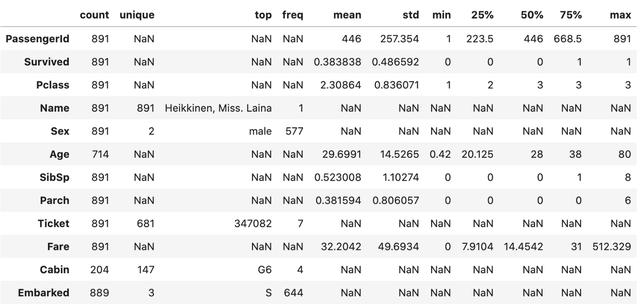 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
fпјү зҷҫеҲҶдҪҚж•°1%гҖҒ5%гҖҒ95%гҖҒ99% гҖӮ жӯЈеҰӮйў„жңҹзҡ„йӮЈж · пјҢ е®ғе°ҶеҸӘи®Ўз®—ж•°еӯ—зү№еҫҒзҡ„з»ҹи®ЎдҝЎжҒҜ гҖӮ
data.quantile(q=[.01, .05, .95, .99])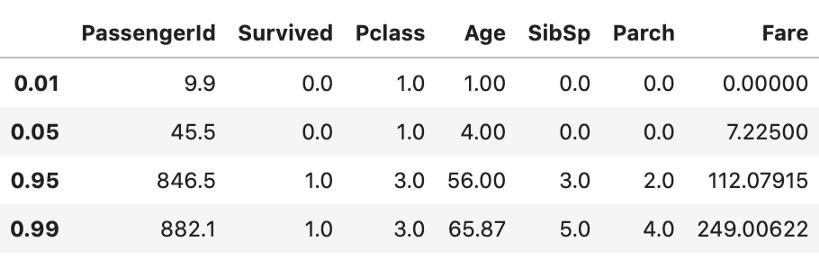 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
gпјү ж‘ҳиҰҒз»ҹи®Ў
- жҳҫзӨәжҹҗдәӣзү№еҫҒзҡ„е”ҜдёҖеҖј гҖӮ
data.Embarked.unique()array(['S', 'C', 'Q', nan], dtype=object)- и®Ўз®—жҹҗдёӘзү№еҫҒзҡ„е”ҜдёҖеҖјзҡ„жҖ»е’Ң гҖӮ
data.Sex.nunique()2- и®Ўз®—жҖ»еҖј
data.count()PassengerId891Survived891Pclass891Name891Sex891Age714SibSp891Parch891Ticket891Fare891Cabin204Embarked889dtype: int64- жҹҗдәӣзү№еҫҒзҡ„жңҖеӨ§еҖј
data.Age.max()80.0- жҹҗдәӣзү№еҫҒзҡ„жңҖе°ҸеҖј
data.Age.min()0.42- жҹҗдәӣзү№еҫҒзҡ„е№іеқҮеҖј
data.Age.mean()29.69911764705882- жҹҗдәӣзү№еҫҒзҡ„дёӯеҖј
data.Age.median()28.0- жҹҗдәӣзү№еҫҒзҡ„第99еҲҶдҪҚж•°
data.Age.quantile(q=[.99])0.9965.87Name: Age, dtype: float64- жҹҗдәӣзү№еҫҒзҡ„ж ҮеҮҶе·®
data.Age.std()14.526497332334044- жҹҗдәӣзү№еҫҒзҡ„ж–№е·®
data.Age.var()211.0191247463081hпјүйўқеӨ–й—®йўҳ1-жҳҫзӨәеҲҶзұ»зү№еҫҒвҖңEmbarkedвҖқжңҖеёёи§Ғзҡ„дёӨдёӘеҖј гҖӮ
data[вҖҳEmbarkedвҖҷ].value_counts().head(2)S644C168Name: Embarked, dtype: int64й—®йўҳ2-вҖңEmbarkedвҖқзҡ„зҷҫеҲҶжҜ”жңҖй«ҳжҳҜеӨҡе°‘пјҹtop_unique = data['Embarked'].value_counts(normalize=True)[0]print(f'{top_unique:.2%}')72.44%iпјү еҸҳйҮҸд№Ӣй—ҙзҡ„зӣёе…іжҖ§ гҖӮ жӯЈеҰӮйў„жңҹзҡ„йӮЈж · пјҢ е®ғе°ҶеҸӘжҳҫзӨәж•°еҖјж•°жҚ®зҡ„з»ҹи®ЎдҝЎжҒҜ гҖӮdata.corr()й»ҳи®Өжғ…еҶөдёӢзҡ„зҡ®е°”йҖҠзӣёе…іжҖ§
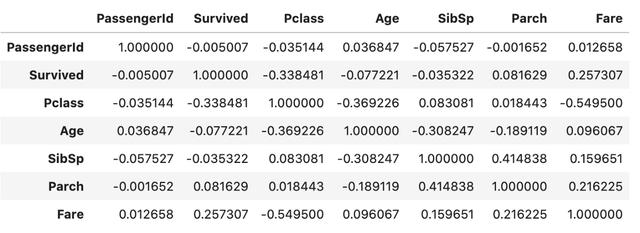 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫJпјү жүҖйҖүеҸҳйҮҸпјҲзӨәдҫӢдёӯдёәвҖңSurvivedвҖқпјүдёҺе…¶д»–еҸҳйҮҸд№Ӣй—ҙзҡ„зӣёе…іжҖ§ гҖӮ
correlation = data.corr()correlation.Survived.sort_values().sort_values(ascending=False) # жңүеәҸеҖјSurvived1.000000Fare0.257307Parch0.081629PassengerId-0.005007SibSp-0.035322Age-0.077221Pclass-0.338481Name: Survived, dtype: float64и°ғж•ҙж•°жҚ®aпјү еҲ—еҮәеҲ—зҡ„еҗҚз§° гҖӮdata.columnsIndex(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')
жҺЁиҚҗйҳ…иҜ»
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 111е®ҢзҫҺйӮ®з®ұдёҠзәҝпјҢе®ҡдҪҚвҖңе№ҙиҪ»дәәзҡ„дё“еұһйӮ®з®ұвҖқ
- з»ҷдҪ зҡ„iPhone12е…Ёж–№дҪҚдҝқжҠӨпјҡ6ж¬ҫжүӢжңәдҝқжҠӨеЈіжЁӘиҜ„
- еҚҺдә‘еӨ§е’–иҜҙ дә‘и®Ўз®—дә‘иҝҗз»ҙжө…и°Ҳ
- еңЁзәҝйҹід№җз”ЁжҲ·еҜ„жңӣз”ЁзҲұеҸ‘з”өпјҢиө„жң¬дёҚж„ҝж— зұід№ӢзӮҠ
- 36еІҒпјҢжҲ‘еңЁеӨ§еҺӮпјҢе’Ңе…Ҳз”ҹе…»иӮІвҖңдә’иҒ”зҪ‘еӯӨе„ҝвҖқ
- иҷҫзұійҹід№җпјҢдёӢдёӘжңҲжӯЈејҸеҒңжӯўжңҚеҠЎ
- ж”Ҝд»ҳе®қе№ҙиҙҰеҚ•жқҘдәҶпјҢдҪ еҸҜиғҪй”ҷеӨұдәҶдёҖеҘ—жҲҝвҖҰвҖҰ
- жІіеҢ—зңҒйҰ–家вҖңж”ҝзӯ–жҷәйҖҡвҖқи®Ўз®—еҷЁжӯЈејҸдёҠзәҝ
- вҖңе…ЁиғҪзҘһвҖқејҖеҸ‘и°·жӯҢеә”з”ЁAPPдј ж’ӯйӮӘж•ҷж•ҷд№ү
- еҗ‘зҫҺеӣҪйқ жӢўпјҹз‘һе…ёз»•ејҖеҚҺдёәйғЁзҪІ5GпјҒеҚҺдёәе·І2ж¬Ўиө·иҜү


















