Pandasж•ҷзЁӢ( дәҢ )
data.Survived.value_counts(normalize=True).round(decimals=4) * 100061.62138.38Name: Survived, dtype: float64iпјү иҜ„дј°ж•°жҚ®йӣҶдёӯжҳҜеҗҰеӯҳеңЁзјәеӨұеҖј гҖӮ
data.isnull().values.any()Truejпјү дҪҝз”Ёisnull()еҫ—еҲ°зјәеӨұеҖјзҡ„ж•°зӣ® гҖӮ
data.isnull().sum()PassengerId0Survived0Pclass0Name0Sex0Age177SibSp0Parch0Ticket0Fare0Cabin687Embarked2dtype: int64kпјү дҪҝз”Ёnotnull()еҫ—еҲ°зҺ°жңүеҖјзҡ„ж•°зӣ® гҖӮ
data.notnull().sum()PassengerId891Survived891Pclass891Name891Sex891Age714SibSp891Parch891Ticket891Fare891Cabin204Embarked889dtype: int64lпјү жҢүеҸҳйҮҸеҲ—еҮәзҡ„зјәеӨұеҖјзҡ„зҷҫеҲҶжҜ”пјҲ%пјү гҖӮ
data.isnull().sum() / data.isnull().shape[0] * 100зӯүеҗҢдәҺ
data.isnull().mean() * 100PassengerId0.000000Survived0.000000Pclass0.000000Name0.000000Sex0.000000Age19.865320SibSp0.000000Parch0.000000Ticket0.000000Fare0.000000Cabin77.104377Embarked0.224467dtype: float64mпјү еӣӣиҲҚдә”е…ҘпјҲеңЁзӨәдҫӢдёӯдёә2пјү гҖӮ
(data.isnull().sum() / data.isnull().shape[0] * 100).round(decimals=2)зӯүеҗҢдәҺ
(data.isnull().mean() * 100).round(decimals=2)PassengerId0.00Survived0.00Pclass0.00Name0.00Sex0.00Age19.87SibSp0.00Parch0.00Ticket0.00Fare0.00Cabin77.10Embarked0.22dtype: float64nпјү еҸҰеӨ–пјҡз”Ёз»„еҗҲж–Үжң¬жү“еҚ°з»“жһң гҖӮ
print("The percentage of 'Age' is missing values:",(data.Age.isnull().sum() / data.Age.isnull().shape[0] * 100).round(decimals=2), "%")The percentage of 'Age' is missing values: 19.87 %print(f"The feature 'Age' has {data.Age.isnull().sum()} missing values")The feature 'Age' has 177 missing valuesprint("'Age' has {} and 'Cabin' has {} missing values".format(data.Age.isnull().sum(), data.Cabin.isnull().sum()))'Age' has 177 and 'Cabin' has 687 missing valuesoпјү еҪўзҠ¶гҖҒеҸҳйҮҸзұ»еһӢе’ҢзјәеӨұеҖјзҡ„дҝЎжҒҜ гҖӮ
data.info()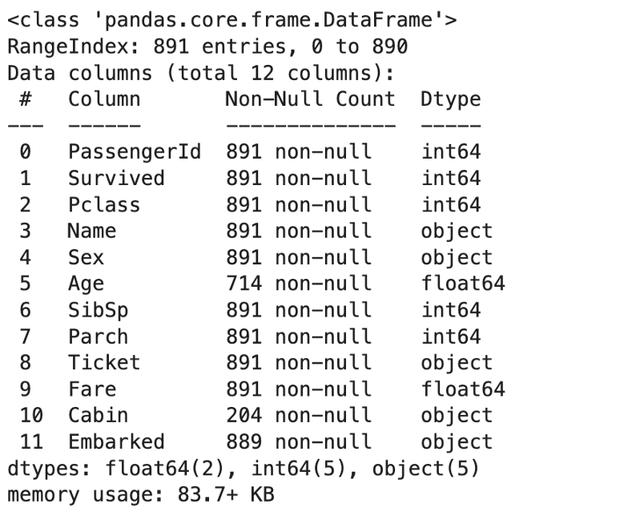 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
pпјү е…·дҪ“зү№еҫҒжҰӮиҝ°пјҲдёӢдҫӢдёӯдёәвҖңжҖ§еҲ«вҖқе’ҢвҖңе№ҙйҫ„вҖқпјү гҖӮ
data[['Sex','Age']].info()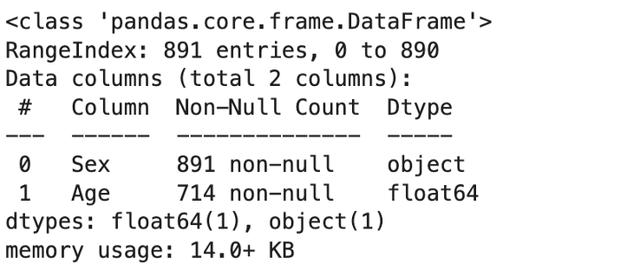 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еҹәжң¬з»ҹи®Ўa) describeж–№жі•еҸӘз»ҷеҮәж•°жҚ®зҡ„еҹәжң¬з»ҹи®ЎдҝЎжҒҜ гҖӮ й»ҳи®Өжғ…еҶөдёӢ пјҢ е®ғеҸӘи®Ўз®—ж•°еҖјж•°жҚ®зҡ„дё»з»ҹи®ЎдҝЎжҒҜ гҖӮ з»“жһңз”Ёpandasж•°жҚ®её§иЎЁзӨә гҖӮ
data.describe()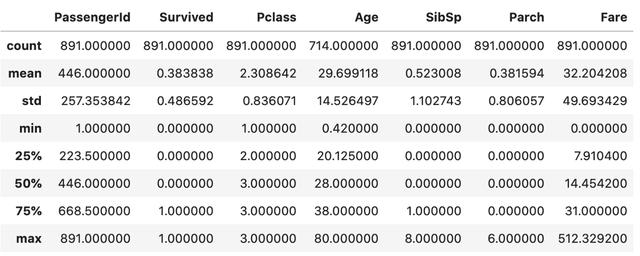 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
bпјү ж·»еҠ е…¶д»–йқһж ҮеҮҶеҖј пјҢ дҫӢеҰӮвҖңж–№е·®вҖқ гҖӮ
describe = data.describe()describe.append(pd.Series(data.var(), name='variance'))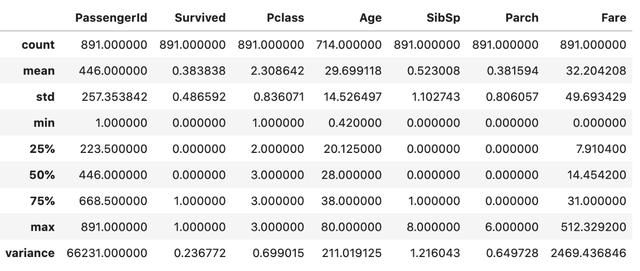 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
cпјү жҳҫзӨәеҲҶзұ»ж•°жҚ® гҖӮ
data.describe(include=["O"])зӯүеҗҢдәҺ
data.describe(exclude=['float64','int64'])зӯүеҗҢдәҺ
data.describe(include=[np.object])
жҺЁиҚҗйҳ…иҜ»



















- 111е®ҢзҫҺйӮ®з®ұдёҠзәҝпјҢе®ҡдҪҚвҖңе№ҙиҪ»дәәзҡ„дё“еұһйӮ®з®ұвҖқ
- з»ҷдҪ зҡ„iPhone12е…Ёж–№дҪҚдҝқжҠӨпјҡ6ж¬ҫжүӢжңәдҝқжҠӨеЈіжЁӘиҜ„
- еҚҺдә‘еӨ§е’–иҜҙ дә‘и®Ўз®—дә‘иҝҗз»ҙжө…и°Ҳ
- еңЁзәҝйҹід№җз”ЁжҲ·еҜ„жңӣз”ЁзҲұеҸ‘з”өпјҢиө„жң¬дёҚж„ҝж— зұід№ӢзӮҠ
- 36еІҒпјҢжҲ‘еңЁеӨ§еҺӮпјҢе’Ңе…Ҳз”ҹе…»иӮІвҖңдә’иҒ”зҪ‘еӯӨе„ҝвҖқ
- иҷҫзұійҹід№җпјҢдёӢдёӘжңҲжӯЈејҸеҒңжӯўжңҚеҠЎ
- ж”Ҝд»ҳе®қе№ҙиҙҰеҚ•жқҘдәҶпјҢдҪ еҸҜиғҪй”ҷеӨұдәҶдёҖеҘ—жҲҝвҖҰвҖҰ
- жІіеҢ—зңҒйҰ–家вҖңж”ҝзӯ–жҷәйҖҡвҖқи®Ўз®—еҷЁжӯЈејҸдёҠзәҝ
- вҖңе…ЁиғҪзҘһвҖқејҖеҸ‘и°·жӯҢеә”з”ЁAPPдј ж’ӯйӮӘж•ҷж•ҷд№ү
- еҗ‘зҫҺеӣҪйқ жӢўпјҹз‘һе…ёз»•ејҖеҚҺдёәйғЁзҪІ5GпјҒеҚҺдёәе·І2ж¬Ўиө·иҜү