使用CNN和Python实施的肺炎检测!这个项目你给几分?( 二 )
声明了以上两个函数后 , 现在我们可以使用它来加载训练数据了 。 如果你运行下面的代码 , 你还将看到为什么我选择在该项目中实现tqdm模块 。
norm_images, norm_labels = load_normal('/kaggle/input/chest-xray-pneumonia/chest_xray/train/NORMAL/')pneu_images, pneu_labels = load_pneumonia('/kaggle/input/chest-xray-pneumonia/chest_xray/train/PNEUMONIA/')  文章插图
文章插图
到目前为止 , 我们已经获得了几个数组:norm_images , norm_labels , pneu_images和pneu_labels 。
带_images后缀的表示它包含预处理的图像 , 而带_labels后缀的数组表示它存储了所有基本信息(也称为标签) 。 换句话说 , norm_images和pneu_images都将成为我们的X数据 , 其余的将成为y数据 。
为了使项目看起来更简单 , 我将这些数组的值连接起来并存储在X_train和y_train数组中 。
X_train = np.append(norm_images, pneu_images, axis=0) y_train = np.append(norm_labels, pneu_labels) 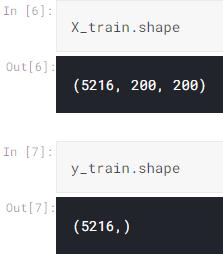 文章插图
文章插图
顺便说一句 , 我使用以下代码获取每个类的图像数:
 文章插图
文章插图
显示多张图像好吧 , 在这个阶段 , 显示几个图像并不是强制性的 。 但我想做是为了确保图片是否已经加载和预处理好 。 下面的代码用于显示14张从X_train阵列随机拍摄的图像以及标签 。
fig, axes = plt.subplots(ncols=7, nrows=2, figsize=(16, 4)) indices = np.random.choice(len(X_train), 14) counter = 0 for i in range(2):for j in range(7):axes[i,j].set_title(y_train[indices[counter]])axes[i,j].imshow(X_train[indices[counter]], cmap='gray')axes[i,j].get_xaxis().set_visible(False)axes[i,j].get_yaxis().set_visible(False)counter += 1 plt.show() 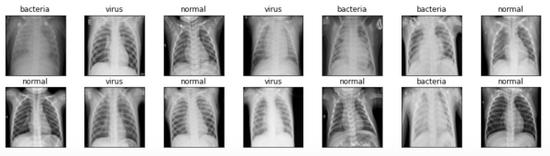 文章插图
文章插图
我们可以看到上图 , 所有图像现在都具有完全相同的大小 , 这与我用于本帖子封面图片的图像不同 。
加载测试图像我们已经知道所有训练数据都已成功加载 , 现在我们可以使用完全相同的函数加载测试数据 。 步骤几乎相同 , 但是这里我将那些加载的数据存储在X_test和y_test数组中 。 用于测试的数据本身包含624个样本 。
norm_images_test, norm_labels_test = load_normal('/kaggle/input/chest-xray-pneumonia/chest_xray/test/NORMAL/')pneu_images_test, pneu_labels_test = load_pneumonia('/kaggle/input/chest-xray-pneumonia/chest_xray/test/PNEUMONIA/')X_test = np.append(norm_images_test, pneu_images_test, axis=0) y_test = np.append(norm_labels_test, pneu_labels_test) 此外 , 我注意到仅加载整个数据集就需要很长时间 。 因此 , 我将使用pickle模块将X_train , X_test , y_train和y_test保存在单独的文件中 。 这样我下次想再使用这些数据的时候 , 就不需要再次运行这些代码了 。
# Use this to save variables with open('pneumonia_data.pickle', 'wb') as f:pickle.dump((X_train, X_test, y_train, y_test), f)# Use this to load variables with open('pneumonia_data.pickle', 'rb') as f:(X_train, X_test, y_train, y_test) = pickle.load(f) 由于所有X数据都经过了很好的预处理 , 因此现在使用标签y_train和y_test了 。
推荐阅读
















- Biogen将使用Apple Watch研究老年痴呆症的早期症状
- Eyeware Beam使用iPhone追踪玩家在游戏中的眼睛运动
- 计算机专业大一下学期,该选择学习Java还是Python
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 或使用天玑1000+芯片?荣耀V40已全渠道开启预约
- 苹果将推出使用mini LED屏的iPad Pro
- 手机能用多久?如果出现这3种征兆,说明“默认使用时间”已到
- 苹果有望在2021年初发布首款使用mini LED显示屏的 iPad Pro
- 笔记本保养有妙招!学会这几招笔记本再战三年