дҪҝз”ЁCNNе’ҢPythonе®һж–Ҫзҡ„иӮәзӮҺжЈҖжөӢпјҒиҝҷдёӘйЎ№зӣ®дҪ з»ҷеҮ еҲҶпјҹ( еӣӣ )
иҝҷйҮҢдҪҝз”ЁsoftmaxжҳҜеӣ дёәжҲ‘们еёҢжңӣиҫ“еҮәжҳҜжҜҸдёӘзұ»еҲ«зҡ„жҰӮзҺҮеҖј гҖӮ
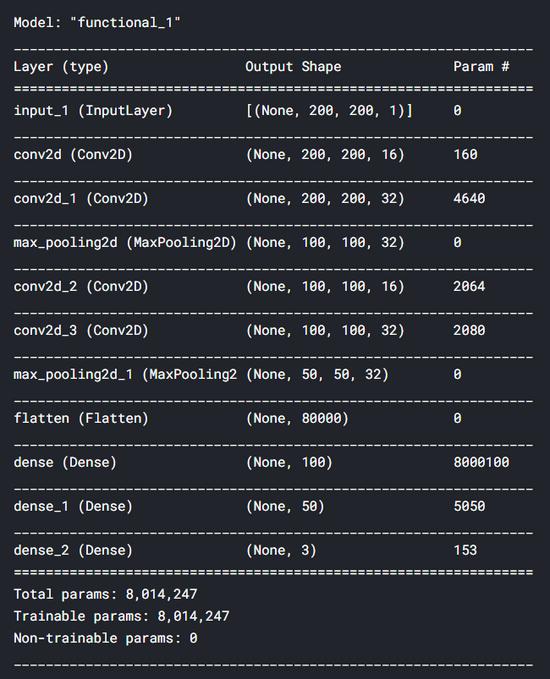
input1 = Input(shape=(X_train.shape[1], X_train.shape[2], 1)) cnn = Conv2D(16, (3, 3), activation='relu', strides=(1, 1),padding='same')(input1) cnn = Conv2D(32, (3, 3), activation='relu', strides=(1, 1),padding='same')(cnn) cnn = MaxPool2D((2, 2))(cnn) cnn = Conv2D(16, (2, 2), activation='relu', strides=(1, 1),padding='same')(cnn) cnn = Conv2D(32, (2, 2), activation='relu', strides=(1, 1),padding='same')(cnn) cnn = MaxPool2D((2, 2))(cnn) cnn = Flatten()(cnn)cnn = Dense(100, activation='relu')(cnn) cnn = Dense(50, activation='relu')(cnn) output1 = Dense(3, activation='softmax')(cnn) model = Model(inputs=input1, outputs=output1) еңЁдҪҝз”ЁдёҠйқўзҡ„д»Јз Ғжһ„йҖ дәҶзҘһз»ҸзҪ‘з»ңд№ӢеҗҺ пјҢ жҲ‘们еҸҜд»ҘйҖҡиҝҮеҜ№modelеҜ№иұЎеә”з”Ёsummary()жқҘжҳҫзӨәжЁЎеһӢзҡ„ж‘ҳиҰҒ гҖӮ дёӢйқўжҳҜжҲ‘们зҡ„CNNжЁЎеһӢзҡ„иҜҰз»Ҷжғ…еҶө гҖӮ жҲ‘们еҸҜд»ҘзңӢеҲ°жҲ‘们жҖ»е…ұжңү800дёҮдёӘеҸӮж•°вҖ”вҖ”иҝҷзЎ®е®һеҫҲеӨҡ гҖӮ еҘҪеҗ§ пјҢ иҝҷе°ұжҳҜдёәд»Җд№ҲжҲ‘еңЁKaggle NotebookдёҠиҝҗиЎҢиҝҷдёӘд»Јз Ғ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҖ»д№Ӣ пјҢ еңЁжһ„е»әжЁЎеһӢд№ӢеҗҺ пјҢ жҲ‘们йңҖиҰҒдҪҝз”ЁеҲҶзұ»дәӨеҸүзҶөжҚҹеӨұеҮҪж•°е’ҢAdamдјҳеҢ–еҷЁжқҘзј–иҜ‘зҘһз»ҸзҪ‘з»ң гҖӮ дҪҝз”ЁиҝҷдёӘжҚҹеӨұеҮҪж•° пјҢ еӣ дёәе®ғеҸӘжҳҜеӨҡзұ»еҲҶзұ»д»»еҠЎдёӯеёёз”Ёзҡ„еҮҪж•° гҖӮ еҗҢж—¶ пјҢ жҲ‘йҖүжӢ©AdamдҪңдёәдјҳеҢ–еҷЁ пјҢ еӣ дёәе®ғжҳҜеңЁеӨ§еӨҡж•°зҘһз»ҸзҪ‘з»ңд»»еҠЎдёӯжңҖе°ҸеҢ–жҚҹеӨұзҡ„жңҖдҪійҖүжӢ© гҖӮ
model.compile(loss='categorical_crossentropy',optimizer='adam', metrics=['acc']) зҺ°еңЁжҳҜж—¶еҖҷи®ӯз»ғжЁЎеһӢдәҶ!еңЁиҝҷйҮҢ пјҢ жҲ‘们е°ҶдҪҝз”Ёfit_generator()иҖҢдёҚжҳҜfit() пјҢ еӣ дёәжҲ‘们е°Ҷд»Һtrain_genеҜ№иұЎиҺ·еҸ–и®ӯз»ғж•°жҚ® гҖӮ еҰӮжһңдҪ е…іжіЁж•°жҚ®жү©е……йғЁеҲҶ пјҢ дҪ дјҡжіЁж„ҸеҲ°train_genжҳҜдҪҝз”ЁX_trainе’Ңy_train_one_hotеҲӣе»әзҡ„ гҖӮ еӣ жӯӨ пјҢ жҲ‘们дёҚйңҖиҰҒеңЁfit_generator()ж–№жі•дёӯжҳҫејҸе®ҡд№үX-yеҜ№ гҖӮ
history = model.fit_generator(train_gen, epochs=30,validation_data=http://kandian.youth.cn/index/(X_test, y_test_one_hot)) train_genзҡ„зү№ж®Ҡд№ӢеӨ„еңЁдәҺ пјҢ и®ӯз»ғиҝҮзЁӢдёӯе°ҶдҪҝз”Ёе…·жңүдёҖе®ҡйҡҸжңәжҖ§зҡ„ж ·жң¬жқҘе®ҢжҲҗ гҖӮ еӣ жӯӨ пјҢ жҲ‘们еңЁX_trainдёӯжӢҘжңүзҡ„жүҖжңүи®ӯз»ғж•°жҚ®йғҪдёҚдјҡзӣҙжҺҘиҫ“е…ҘеҲ°зҘһз»ҸзҪ‘з»ңдёӯ гҖӮ еҸ–иҖҢд»Јд№Ӣзҡ„жҳҜ пјҢ иҝҷдәӣж ·жң¬е°Ҷиў«з”ЁдҪңз”ҹжҲҗеҷЁзҡ„еҹәзЎҖ пјҢ йҖҡиҝҮдёҖдәӣйҡҸжңәеҸҳжҚўз”ҹжҲҗдёҖдёӘж–°еӣҫеғҸ гҖӮ
жӯӨеӨ– пјҢ иҜҘз”ҹжҲҗеҷЁеңЁжҜҸдёӘж—¶жңҹдә§з”ҹдёҚеҗҢзҡ„еӣҫеғҸ пјҢ иҝҷеҜ№дәҺжҲ‘们зҡ„зҘһз»ҸзҪ‘з»ңеҲҶзұ»еҷЁжӣҙеҘҪең°жіӣеҢ–жөӢиҜ•йӣҶдёӯзҡ„ж ·жң¬йқһеёёжңүеҲ© гҖӮ дёӢйқўжҳҜи®ӯз»ғзҡ„иҝҮзЁӢ гҖӮ
Epoch 1/30 163/163 [==============================] - 19s 114ms/step - loss: 5.7014 - acc: 0.6133 - val_loss: 0.7971 - val_acc: 0.7228 . . . Epoch 10/30 163/163 [==============================] - 18s 111ms/step - loss: 0.5575 - acc: 0.7650 - val_loss: 0.8788 - val_acc: 0.7308 . . . Epoch 20/30 163/163 [==============================] - 17s 102ms/step - loss: 0.5267 - acc: 0.7784 - val_loss: 0.6668 - val_acc: 0.7917 . . . Epoch 30/30 163/163 [==============================] - 17s 104ms/step - loss: 0.4915 - acc: 0.7922 - val_loss: 0.7079 - val_acc: 0.8045 ж•ҙдёӘи®ӯз»ғжң¬иә«еңЁжҲ‘зҡ„Kaggle NotebookдёҠиҠұиҙ№дәҶеӨ§зәҰ10еҲҶй’ҹ гҖӮ жүҖд»ҘиҰҒиҖҗеҝғзӮ№!з»ҸиҝҮи®ӯз»ғеҗҺ пјҢ жҲ‘们еҸҜд»Ҙз»ҳеҲ¶еҮәеҮҶзЎ®еәҰеҫ—еҲҶзҡ„жҸҗй«ҳе’ҢжҚҹеӨұеҖјзҡ„йҷҚдҪҺ пјҢ еҰӮдёӢжүҖзӨәпјҡ
plt.figure(figsize=(8,6)) plt.title('Accuracy scores') plt.plot(history.history['acc']) plt.plot(history.history['val_acc']) plt.legend(['acc', 'val_acc']) plt.show()plt.figure(figsize=(8,6)) plt.title('Loss value') plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.legend(['loss', 'val_loss']) plt.show()
жҺЁиҚҗйҳ…иҜ»







![[еҢ—дә¬жҷҡжҠҘ]д»ҺзңӢжҺЁзҗҶеү§еҲ°жҚўеү§жңҚиө°иҝӣе®һжҷҜ жҺЁзҗҶжёёжҲҸжҲҗдәҶе№ҙиҪ»дәәж–°зҺ©](http://weihai.dzwww.com/gdxw/201912/W020191213348977134657.jpg)




![[дёңиҺһ]дёңиҺһеёӮ6еҗҚеҢ»з–—йӘЁе№ІејҖе§Ӣж–°дёҖиҪ®жҸҙи—Ҹ](http://ttbs.guangsuss.com/image/2f0dd0f7e88f63c501a7262c7ac521f9)



- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’
- жңӘжқҘжғіиҝӣе…ҘAIйўҶеҹҹпјҢиҜҘеӯҰд№ PythonиҝҳжҳҜJavaеӨ§ж•°жҚ®ејҖеҸ‘
- жҲ–дҪҝз”ЁеӨ©зҺ‘1000+иҠҜзүҮпјҹиҚЈиҖҖV40е·Іе…Ёжё йҒ“ејҖеҗҜйў„зәҰ
- иӢ№жһңе°ҶжҺЁеҮәдҪҝз”Ёmini LEDеұҸзҡ„iPad Pro
- жүӢжңәиғҪз”ЁеӨҡд№…пјҹеҰӮжһңеҮәзҺ°иҝҷ3з§ҚеҫҒе…ҶпјҢиҜҙжҳҺвҖңй»ҳи®ӨдҪҝз”Ёж—¶й—ҙвҖқе·ІеҲ°
- иӢ№жһңжңүжңӣеңЁ2021е№ҙеҲқеҸ‘еёғйҰ–ж¬ҫдҪҝз”Ёmini LEDжҳҫзӨәеұҸзҡ„ iPad Pro
- 笔记жң¬дҝқе…»жңүеҰҷжӢӣпјҒеӯҰдјҡиҝҷеҮ жӢӣ笔记жң¬еҶҚжҲҳдёүе№ҙ