Transformerз«һдәүеҜ№жүӢQRNNи®әж–Үи§ЈиҜ»жӣҙеҝ«зҡ„RNN( дәҢ )
жұ еҢ–组件
йҖҡеёё пјҢ еҗҲ并жҳҜдёҖз§Қж— еҸӮж•°зҡ„еҮҪж•° пјҢ еҸҜжҚ•иҺ·еҚ·з§Ҝзү№еҫҒдёӯзҡ„йҮҚиҰҒзү№еҫҒ гҖӮеҜ№дәҺеӣҫеғҸ пјҢ йҖҡеёёдҪҝз”ЁжңҖеӨ§жұ еҢ–е’Ңе№іеқҮжұ еҢ– гҖӮдҪҶжҳҜ пјҢ еңЁеәҸеҲ—зҡ„жғ…еҶөдёӢ пјҢ жҲ‘们дёҚиғҪз®ҖеҚ•ең°иҺ·еҸ–зү№еҫҒд№Ӣй—ҙзҡ„е№іеқҮеҖјжҲ–жңҖеӨ§еҖј пјҢ е®ғйңҖиҰҒжңүдёҖдәӣеҫӘзҺҜ гҖӮеӣ жӯӨ пјҢ QRNNи®әж–ҮжҸҗеҮәдәҶеҸ—дј з»ҹLSTMеҚ•е…ғдёӯе…ғзҙ зә§й—ЁжҺ§дҪ“зі»з»“жһ„еҗҜеҸ‘зҡ„жұ еҢ–еҠҹиғҪ гҖӮжң¬иҙЁдёҠ пјҢ е®ғжҳҜдёҖдёӘж— еҸӮж•°еҮҪж•° пјҢ е®ғе°Ҷи·Ёж—¶й—ҙжӯҘж··еҗҲйҡҗи—ҸзҠ¶жҖҒ гҖӮ
жңҖз®ҖеҚ•зҡ„йҖүйЎ№жҳҜ"еҠЁжҖҒе№іеқҮжұ еҢ–" пјҢ е®ғд»…дҪҝз”ЁдәҶ"еҝҳи®°й—Ё"пјҲеӣ жӯӨз§°дёәf-poolingпјүпјҡ
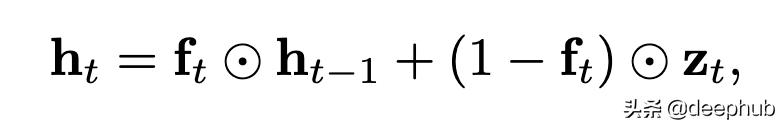 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
вҠҷжҳҜйҖҗе…ғзҙ зҹ©йҳөд№ҳжі• гҖӮ е®ғд»Ҙеҝҳи®°й—ЁдёәеҸӮж•° пјҢ еҮ д№ҺзӯүдәҺиҫ“еҮәзҡ„"移еҠЁе№іеқҮеҖј" гҖӮ
еҸҰдёҖз§ҚйҖүжӢ©жҳҜдҪҝз”Ёеҝҳи®°й—Ёд»ҘеҸҠиҫ“еҮәй—ЁпјҲжүҖд»Ҙиў«з§°дҪң пјҢ fo-poolingпјүпјҡ
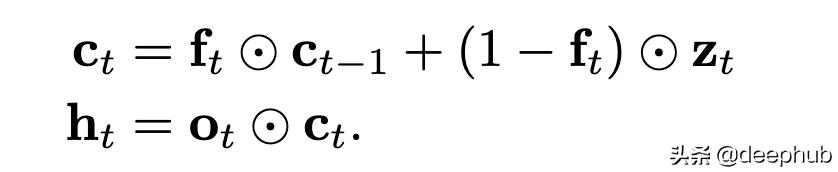 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
йҷӨжӯӨд»ҘеӨ– пјҢ жұ еҢ–еҸҜиғҪеҸҰеӨ–е…·жңүдё“з”Ёзҡ„иҫ“е…Ҙй—ЁпјҲifo-poolingпјүпјҡ
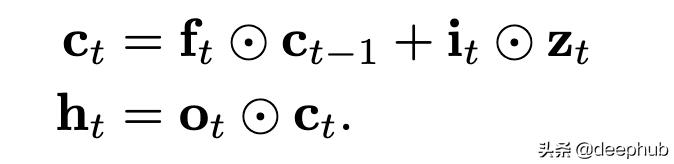 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жӯЈеҲҷеҢ–еңЁжЈҖжҹҘдәҶеҗ„з§ҚйҖ’еҪ’йҖҖеҮәж–№жЎҲд№ӢеҗҺ пјҢ QRNNдҪҝз”ЁдәҶдёҖз§Қжү©еұ•ж–№жЎҲ пјҢ з§°дёә"еҢәеҹҹйҖҖеҮә"пјҲ'zone outпјү пјҢ е®ғжң¬иҙЁдёҠжҳҜеңЁжҜҸдёӘж—¶й—ҙжӯҘйҖүжӢ©дёҖдёӘйҡҸжңәеӯҗйӣҶжқҘйҖҖеҮә пјҢ еҜ№дәҺиҝҷдәӣйҖҡйҒ“ пјҢ е®ғеҸӘжҳҜе°ҶеҪ“еүҚйҖҡйҒ“еҖјеӨҚеҲ¶еҲ°дёӢдёҖж¬Ў жӯҘйӘӨ пјҢ ж— йңҖд»»дҪ•дҝ®ж”№ гҖӮ
иҝҷзӯүж•ҲдәҺе°ҶQRNNзҡ„"еҝҳи®°й—Ё"йҖҡйҒ“зҡ„еӯҗйӣҶйҡҸжңәи®ҫзҪ®дёә1 пјҢ жҲ–еңЁ1-FдёҠиҝӣиЎҢdropout -- QRNN Paper
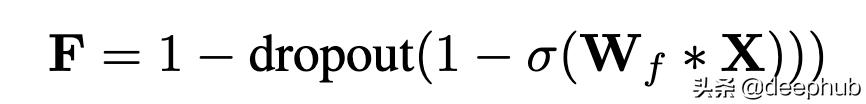 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жқҘиҮӘDenseNetзҡ„жғіжі•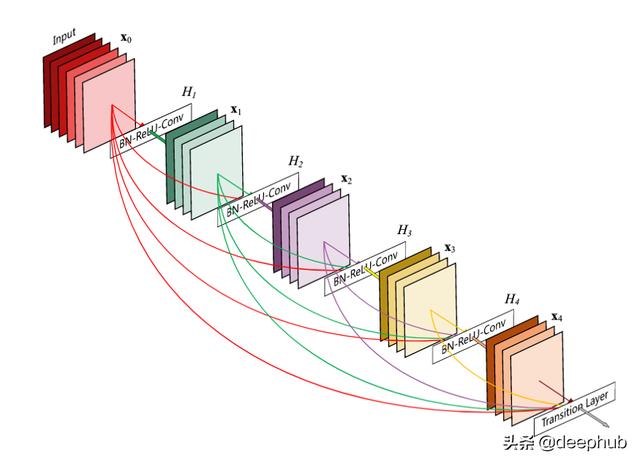 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
DenseNetдҪ“зі»з»“жһ„е»әи®®еңЁжҜҸдёҖеұӮдёҺе…¶еүҚйқўзҡ„жҜҸдёҖеұӮд№Ӣй—ҙйғҪе…·жңүи·іиҝҮиҝһжҺҘ пјҢ иҝҷдёҺеңЁеҗҺз»ӯеұӮдёҠе…·жңүи·іиҝҮиҝһжҺҘзҡ„жғҜдҫӢзӣёеҸҚ гҖӮеӣ жӯӨ пјҢ еҜ№дәҺе…·жңүLдёӘеұӮзҡ„зҪ‘з»ң пјҢ е°ҶеӯҳеңЁLпјҲL-1пјүдёӘи·іиҝҮиҝһжҺҘ гҖӮиҝҷжңүеҠ©дәҺжўҜеәҰжөҒеҠЁе’Ң收ж•ӣ пјҢ дҪҶиҰҒиҖғиҷ‘дәҢж¬Ўз©әй—ҙ гҖӮ
дҪҝз”ЁQRNNжһ„е»әseq2seq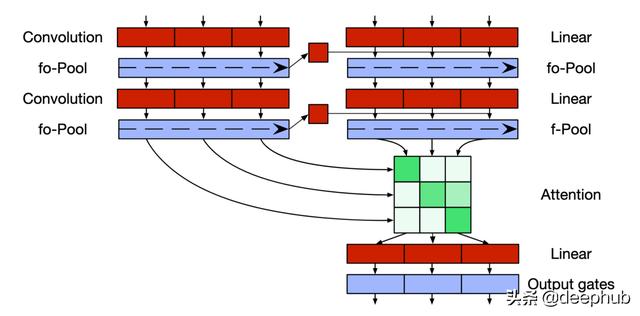 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
еңЁеҹәдәҺRNNзҡ„常规seq2seqжЁЎеһӢдёӯ пјҢ жҲ‘们еҸӘйңҖдҪҝз”Ёзј–з ҒеҷЁзҡ„жңҖеҗҺдёҖдёӘйҡҗи—ҸзҠ¶жҖҒеҲқе§ӢеҢ–и§Јз ҒеҷЁ пјҢ 然еҗҺй’ҲеҜ№и§Јз ҒеҷЁеәҸеҲ—еҜ№е…¶иҝӣиЎҢиҝӣдёҖжӯҘдҝ®ж”№ гҖӮжҲ‘д»¬ж— жі•еҜ№еҫӘзҺҜжұ еұӮжү§иЎҢжӯӨж“ҚдҪң пјҢ еӣ дёәеңЁиҝҷйҮҢ пјҢ зј–з ҒеҷЁзҠ¶жҖҒж— жі•дёәи§Јз ҒеҷЁзҡ„йҡҗи—ҸзҠ¶жҖҒеҒҡеҮәеҫҲеӨ§иҙЎзҢ® гҖӮеӣ жӯӨ пјҢ дҪңиҖ…жҸҗеҮәдәҶдёҖз§Қж”№иҝӣзҡ„и§Јз ҒеҷЁжһ¶жһ„ гҖӮ
е°Ҷзј–з ҒеҷЁзҡ„жңҖеҗҺдёҖдёӘйҡҗи—ҸзҠ¶жҖҒпјҲжңҖеҗҺдёҖдёӘд»ӨзүҢзҡ„йҡҗи—ҸзҠ¶жҖҒпјүзәҝжҖ§жҠ•еҪұпјҲзәҝжҖ§еұӮпјү пјҢ 并еңЁеә”з”Ёд»»дҪ•жҝҖжҙ»д№ӢеүҚ пјҢ е°Ҷе…¶ж·»еҠ еҲ°и§Јз ҒеҷЁеұӮжҜҸдёӘж—¶й—ҙжӯҘй•ҝзҡ„еҚ·з§Ҝиҫ“еҮәдёӯпјҲе№ҝж’ӯ пјҢ еӣ дёәзј–з ҒеҷЁзҹўйҮҸиҫғе°Ҹпјүпјҡ
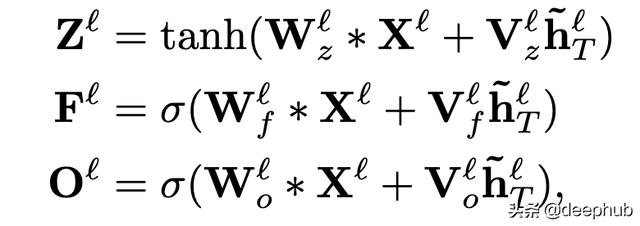 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
VжҳҜеә”з”ЁдәҺжңҖеҗҺдёҖдёӘзј–з ҒеҷЁйҡҗи—ҸзҠ¶жҖҒзҡ„зәҝжҖ§жқғйҮҚ гҖӮ
жіЁж„ҸеҠӣжңәеҲ¶жіЁж„ҸеҠӣд»…еә”з”ЁдәҺи§Јз ҒеҷЁзҡ„жңҖеҗҺйҡҗи—ҸзҠ¶жҖҒ гҖӮ
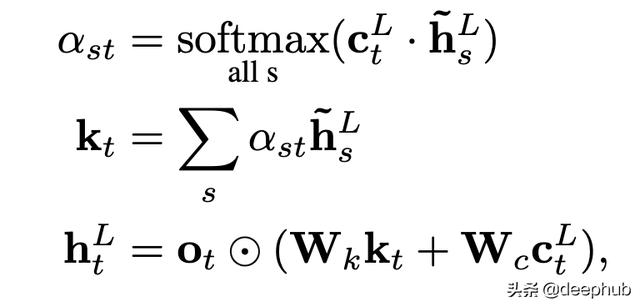 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
е…¶дёӯsжҳҜзј–з ҒеҷЁзҡ„еәҸеҲ—й•ҝеәҰ пјҢ tжҳҜи§Јз ҒеҷЁзҡ„еәҸеҲ—й•ҝеәҰ пјҢ LиЎЁзӨәжңҖеҗҺдёҖеұӮ гҖӮ
йҰ–е…Ҳ пјҢ е°Ҷи§Јз ҒеҷЁзҡ„жңӘйҖүйҖҡзҡ„жңҖеҗҺдёҖеұӮйҡҗи—ҸзҠ¶жҖҒзҡ„зӮ№з§ҜдёҺжңҖеҗҺдёҖеұӮзј–з ҒеҷЁйҡҗи—ҸзҠ¶жҖҒзӣёд№ҳ гҖӮиҝҷе°ҶеҜјиҮҙеҪўзҠ¶зҹ©йҳөпјҲt пјҢ sпјү гҖӮе°ҶSoftmaxжӣҝд»Јs пјҢ 并дҪҝз”ЁиҜҘеҲҶж•°иҺ·еҫ—еҪўзҠ¶пјҲt пјҢ hiddendimпјүзҡ„жіЁж„ҸжҖ»е’Ңkt гҖӮ然еҗҺ пјҢ е°ҶktдёҺctдёҖиө·дҪҝз”Ё пјҢ д»ҘиҺ·еҸ–и§Јз ҒеҷЁзҡ„й—ЁжҺ§жңҖеҗҺдёҖеұӮйҡҗи—ҸзҠ¶жҖҒ гҖӮ
жҖ§иғҪжөӢиҜ•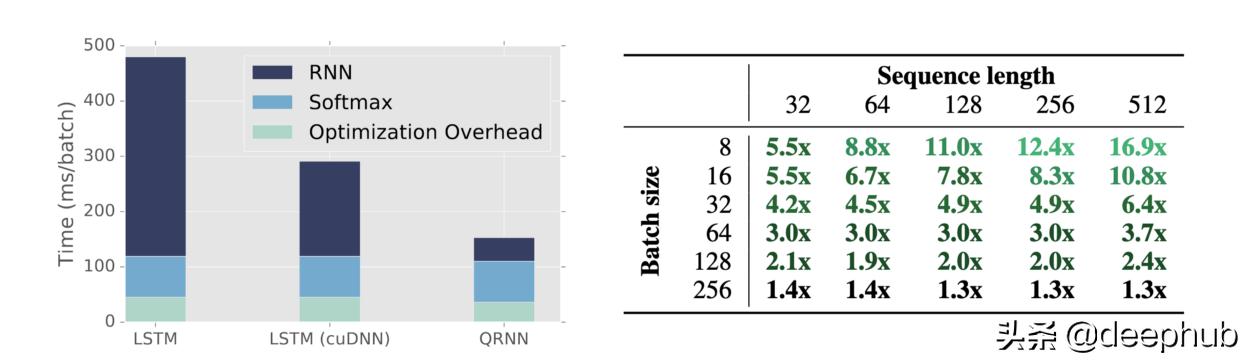 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
гҖҗTransformerз«һдәүеҜ№жүӢQRNNи®әж–Үи§ЈиҜ»жӣҙеҝ«зҡ„RNNгҖ‘дёҺLSTMжһ¶жһ„зӣёжҜ” пјҢ QRNNеҸҜд»ҘиҫҫеҲ°зӣёеҪ“зҡ„еҮҶзЎ®еәҰ пјҢ еңЁжҹҗдәӣжғ…еҶөдёӢз”ҡиҮіжҜ”LSTMжһ¶жһ„з•ҘиғңдёҖзӯ№ пјҢ 并且иҝҗз®—йҖҹеәҰжҸҗй«ҳдәҶ17еҖҚ гҖӮ
жҺЁиҚҗйҳ…иҜ»

![[ж•°з Ғе°ҸзҺӢ]ProжңүзӮ№еғҸпјҢиҝҳжҳҜеҸҢжү“еӯ”жӣІйқўеұҸпјҒиҚЈиҖҖ30 Proзңҹжңәжӣқе…үпјҢи·ҹеҚҺдёәP40](https://imgcdn.toutiaoyule.com/20200328/20200328061128829913a_t.jpeg)
















- е°Ҹзұі11иҝҺжқҘеҜ№жүӢпјҢеӣҪйҷ…е·ЁеӨҙеҚіе°ҶеҮәеҮ»пјҢжҲ–йҮҮз”ЁвҖңеҸҢиҠҜзүҮвҖқж–№жЎҲ
- зҫҺеӘ’пјҡзҫҺеӣҪжӢүе°ҸејҹжҗһејҖж”ҫзҪ‘з»ң规иҢғж‘Ҷи„ұеҚҺдёә дҪҶжӣҙеӨҡдёӯеӣҪе…¬еҸёеҠ е…Ҙз«һдәүжҗ…й»„зҫҺж–№и®ЎеҲ’
- ж•°жҚ®жқҖзҶҹгҖҒеұҸи”ҪеҜ№жүӢпјҒйў‘йў‘вҖңжғ№дәӢвҖқзҡ„зҫҺеӣўйҒӯеҸҚеһ„ж–ӯиҜүи®ј
- иҜ¬йҷ·еҜ№жүӢпјҢз”©й”…е‘ҳе·ҘпјҢеҺҹжқҘзӨҫдәӨиөӣйҒ“зҡ„вҖңзҗғйңёвҖқжҳҜд»–пјҹ
- 2020е№ҙеәҰзӣҳзӮ№пҪңжүӢжңәеҺӮе•Ҷз«һдәүеҠ еү§пјҢеҠ йҖҹеҮәжө·гҖҒеҸ‘еҠӣIoTжһ„е»әз”ҹжҖҒжҲҗдё»жөҒ
- еҸҲдёҖиЎҢиҝҺвҖңе…іеҒңжҪ®вҖқпјҢе•Ҷиҙ©иў«вҖңжҠўйҘӯзў—вҖқпјҢз”ҹж„ҸйҡҫеҒҡеӣ жҒ¶ж„Ҹз«һдәүпјҹ
- е°Ҹзұі11дёҚйҖҒе……з”өеҷЁпјҢжңҖеӨ§еҜ№жүӢзӣҙжҺҘе®Јеёғпјҡж Үй…ҚйғҪжҳҜ120Wеҝ«е……еӨҙ
- VMwareеҜ№и·іж§ҪеҲ°з«һдәүеҜ№жүӢе…¬еҸёзҡ„еүҚй«ҳз®ЎеҸ‘иө·иҜүи®јпјҢз§°иҝқеҸҚеҗҲеҗҢ
- iQOO7жҲҗдёәе°Ҹзұі11жңҖеӨ§еҜ№жүӢпјҢжҖ§д»·жҜ”е®Ңе…ЁдёҚиҫ“пјҢд»·ж јжүҚжҳҜе…ій”®
- е…¬е№із«һдәүжҳҜеёӮеңәз»ҸжөҺзҡ„еҹәзҹі