笔者以此两种标准检视数据痕迹 。 数据痕迹首先是一种行为痕迹 , 数据痕迹的累积就是网络用户网络行为的累计 , 对数据痕迹的分析其实是对网络用户行为模式和行为轨迹的分析 。 现今大数据技术通过对网络用户网络行为、网络行踪的深度挖掘、分析 , 已经可以将特定主体识别出来 , 此符合“识别性标准” 。 人格的数据图像是通过行为刻画 , 依靠行为搭建起对人格的描绘 。 正如一美国学者所说 , 数字行为在一段时间内积累到一定程度 , 就能够构成与实际人格相似的数字人格 , 即以在交易中体现出来的数据为基础的个人的公共形象 , 被用来作为该个人的代号 。 由此可知 , 数字化人格图像是由数据痕迹而非宽泛意义的个人信息拼接得出 。 因此 , 数据痕迹带有行为主体某种人格特质 , 具备人格利益 。 数据痕迹满足个人信息必备的识别性与人格性特征 , 应属于个人信息的一部分 。
数据痕迹产生于网络用户的网络活动 , 指向同一特定用户的数据痕迹可能来自不同网络用户 。 根据数据痕迹的生产者区别 , 可进一步将数据痕迹区分为用户自身网络活动制造的数据痕迹(简称为“自生型数据痕迹”) , 与用户之外他者网络活动制造但与该用户相关的数据痕迹(简称为“他生型数据痕迹”) 。
(二)搜索引擎工作原理及其间权利义务关系的抽取
1.搜索引擎工作原理
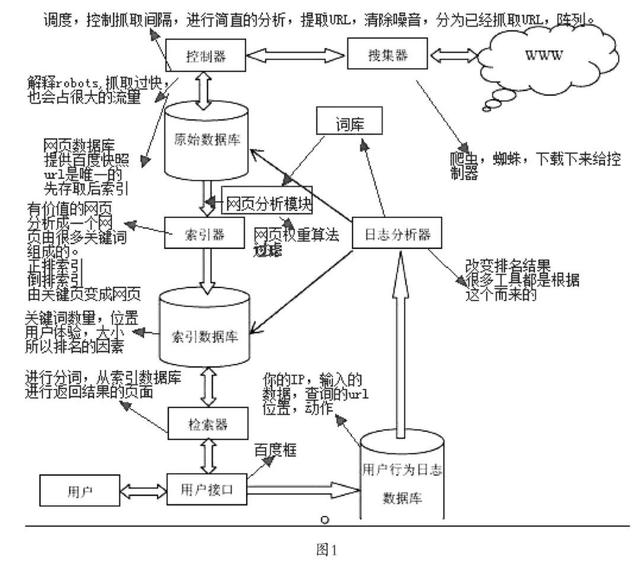
搜索引擎是处理数据痕迹最常用的工具之一 。 按照百度给出的定义 , 搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息 , 在对信息进行组织和处理后 , 为用户提供检索服务 , 将用户检索相关的信息展示给用户的系统 。 搜索引擎主要由四个部分组成 , 其工作流程主要有三个步骤 。 这四个部分分别是采集器、分析索引器、检索器和查询器 。 其工作过程的三个步骤分别是:
①爬取、搜集数据 。 搜索引擎派出能够自动收集网页链接的爬虫 , 自动访问一定IP地址内的互联网网页 , 沿着网页中的URL爬到其他网页 。 在重复这一过程中 , 爬虫会持续定期地抓取其爬过的网页 , 并将搜集到的数据存入搜索引擎数据库 , 以此周而复始 , 保证搜索引擎的时效性 。
②建立索引数据库 。 搜索引擎对收集到的原始网页数据进行分析 , 判断网页类型、权重、去重计算 , 把重复网页清洗掉 。 经过分析处理的网页数据不再是爬虫抓取的原始页面 , 而是浓缩成能反映特定主题内容的、以词为单位的文档 , 即搜索引擎索引系统根据一定的算法进行大量运算得到每一个网页针对页面内容及超链中每一个关键词或者某一个文本的相关度 , 然后利用这些文档建立索引数据库 。
③在索引数据库中搜索并排序 。 当用户在搜索引擎界面输入搜索关键词后 , 检索系统会在索引数据库中找出包含搜索词的相关网页 , 并根据事先设定好的算法对网页进行排序 。 在这个过程中 , 检索系统会根据搜索词计算数据库中网页对搜索词的相关度 , 按照相关度数据将相关网页降序排列 , 相关度越高排名越靠前 。 最后由页面生成系统将检索结果的链接地址和页面内容摘要等数据组织起来返回给用户 。
综上 , 搜索引擎工作流程及各部分负担职能 , 如图1所示:
 文章插图
文章插图
2.搜索引擎工作过程中权利义务关系的提炼
搜素引擎数据痕迹处理的工作原理若仅采上述介绍 , 对于法律人无疑晦涩且难懂 , 所以需要将上述搜索引擎工作原理转化为法律语言表述 , 用“法律人彼此约定一种特定的语言使用方式” , 即以法律关系表达 。 一切法律关系皆可化约为权利与义务 。 所以 , 我们能够用搜索引擎与相对方的权利义务关系表达其工作过程 。 根据搜索引擎的工作流程 , 步骤①、③属于搜索引擎与外界的关联 , 必然引发搜索引擎与不同主体之间的权利义务关系 。 步骤②发生于搜索引擎的内部 , 不涉及搜索引擎之外的其他主体 , 自然也不存在搜索引擎与其他主体之间的权利义务关系 。 搜索引擎数据痕迹处理过程 , 实质上形成了以搜索引擎为中心的三主体、两阶段的权利义务关系:第一 , 被搜集数据痕迹的制造者与搜索引擎之间的权利义务关系;第二 , 搜索引擎与用户之间的权利义务关系 。 如图2如下:
推荐阅读

















- 西部数据在CES 2021推出多款4TB容量的旗舰级SSD
- WhatsApp收集用户数据新政惹众怒,“删除WhatsApp”在土耳其上热搜
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能
- HDMI 2.1诞生三年:超高速数据线落地 8K电视圆满了